題記:昨晚在一個技術社區直播分享了“利用Azure Functions和k8s構建Serverless計算平台”這一話題。整個分享分為4個部分:Serverless概念的介紹、Azure Functions的簡單介紹、k8s和KEDA的介紹和最後的演示。
Serverless
Serverless其實包含了兩種概念:BaaS(Backend as a Service)和FaaS(Function as a Service)。這次的分享主要針對的是FaaS概念。
FaaS的最大特徵就是:無需管理自己的服務器或擁有自己的持續運行的服務應用的情況下運行後端代碼。 上面加粗的地方其實也揭示了FaaS和PaaS的本質區別:你為了運行後端代碼,需不需要擁有一套持續運行的服務端完整應用(不管是WebSite還是Web API)。
另外,FaaS還擁有如下特徵:
- 可以使用任何語言,不需要針對特定框架和函數進行編碼
- 部署方式和傳統系統有很大不同
- 水平伸縮完全自動化、彈性,並由平台供應商管理
- 函數通常由事件觸發,部分平台供應商支持接收HTTP觸發
當然判斷什麼東西不是FaaS也有一些標準:
- 能否在20ms啟動半秒執行完,根本區別在於伸縮性的方式
- FaaS也可能依賴容器,但是和其他使用容器的應用區別在於伸縮性的自動化、透明和細度
- 沒有傳統的Ops,但是應用本身運維過程還是需要,甚至更難(因為不同)
使用FaaS有其優缺點,這裏就報喜不報憂,只列一下優點:
- 降低運維成本
- 降低伸縮成本
- 按量付費:偶爾請求,流量忽高忽低
- 優化代碼即可省錢
- 更易運維
- 伸縮的好處利於降低運維難度
- 降低打包和部署複雜度
- 快速投入市場,持續優化
Azure Functions
以官方文檔的介紹:Azure Functions 允許你運行小段代碼(稱為“函數”)且不需要擔心應用程序基礎結構。 藉助 Azure Functions,雲基礎結構可以提供應用程序保持規模化運行所需的所有最新狀態的服務器。 函數由特定類型的事件“觸發”。 支持的觸發器包括對數據更改做出響應、對消息做出響應、按計劃運行,或者生成 HTTP 請求的結果。 雖然你始終可以直接針對大量服務編寫代碼,但使用綁定可以簡化與其他服務的集成。 使用綁定,你能夠以聲明方式訪問各種 Azure 服務和第三方服務。
Azure Functions包含如下功能:
- 無服務器應用程序:使用 Functions,可在 Microsoft Azure 上開發無服務器應用程序。
- 語言選擇:使用所選的 C#、Java、JavaScript、Python 和 PowerShell 編寫函數。
- 按使用付費定價模型:僅為運行代碼所用的時間付費。
- 自帶依賴項:Functions 支持 NuGet 和 NPM,允許你訪問你喜歡的庫。
- 集成的安全性:使用 OAuth 提供程序(如 Azure Active Directory、Facebook、Google、Twitter 和 Microsoft 帳戶)保護 HTTP 觸發的函數。
- 簡化的集成:輕鬆與 Azure 服務和軟件即服務 (SaaS) 產品/服務進行集成。
- 靈活開發:直接在門戶中編寫函數代碼,或者通過 GitHub、Azure DevOps Services 和其他受支持的開發工具設置持續集成和部署代碼。
- 有狀態無服務器體繫結構:使用 Durable Functions 協調無服務器應用程序。
- 開放源代碼:Functions 運行時是開源的,可在 GitHub 上找到。
大家看到了,Azure Functions雖然是來源於微軟Azure的技術,但是是使用MIT協議開源的,且已經貢獻給.NET Foundation。
所以,你可以使用Azure Functions來搭建(甚至定製)自己的Serverless計算平台。開源的不僅是Azure Functions框架本身,還包括了命令行工具(可以支持本地調試)和VSCode的擴展。當然,開發工具除了前面兩者,你還是可以使用宇宙第一的IDE:Visual Studio。
下面是相關開源的地址:
- 框架:https://github.com/Azure/azure-functions-host
- 命令行工具:https://github.com/Azure/azure-functions-core-tools
- VSCode擴展:https://github.com/Microsoft/vscode-azurefunctions
只有開源的框架還不行,還需要運行環境,正如大部分開源FaaS框架一樣,Azure Functions也把k8s作為運行環境。不過為了達到自動伸縮、不使用就不消耗資源的目標,還需要搭配其他中間件才能達到效果。
k8s和KEDA
眾所周知,Kubernetes已經成為最主流的PaaS平台,各大公有雲提供商都提供了k8s的服務,比如微軟Azure上的AKS或者阿里雲的ACK。
為了更好的理解為什麼k8s可以作為Serverless完美的運行環境,是需要對如下概念有一些深入的理解的:
- Pod和Deployment:Pod代表了運行函數的實例,而Deployment用於控制函數的實例數。
- HPA(Horizontal Pod Autoscaler):k8s內置的水平Pod自動伸縮器,其基於一些度量指標(比如內存、CPU等)來對Deployment的Pod實例數進行伸縮。
- Helm Charts:一個強大的打包、發布k8s應用的包管理器。我們開發好的函數在編譯為Docker Image之後,可以用Helm Charts來打包(當然也可以直接用k8s的yaml文件)。
k8s雖然提供了HPA,但是它無法基於更靈活的事件源來進行伸縮,也無法把Pod的實例數縮到0,或者由0伸到1。這個時候,就需要另外一個開源項目KEDA出場了(貢獻者來自微軟、AWS等大公司,以及很多社區志願者)。
KEDA:Kubernetes Event-driven Autoscaling。項目地址在:https://github.com/kedacore/keda。其具有如下特點:
- 事件驅動
- 輕而易舉實現自動伸縮
- 內置伸縮器
- 多種負載類型
- 社區開源項目
- 支持Azure Functions
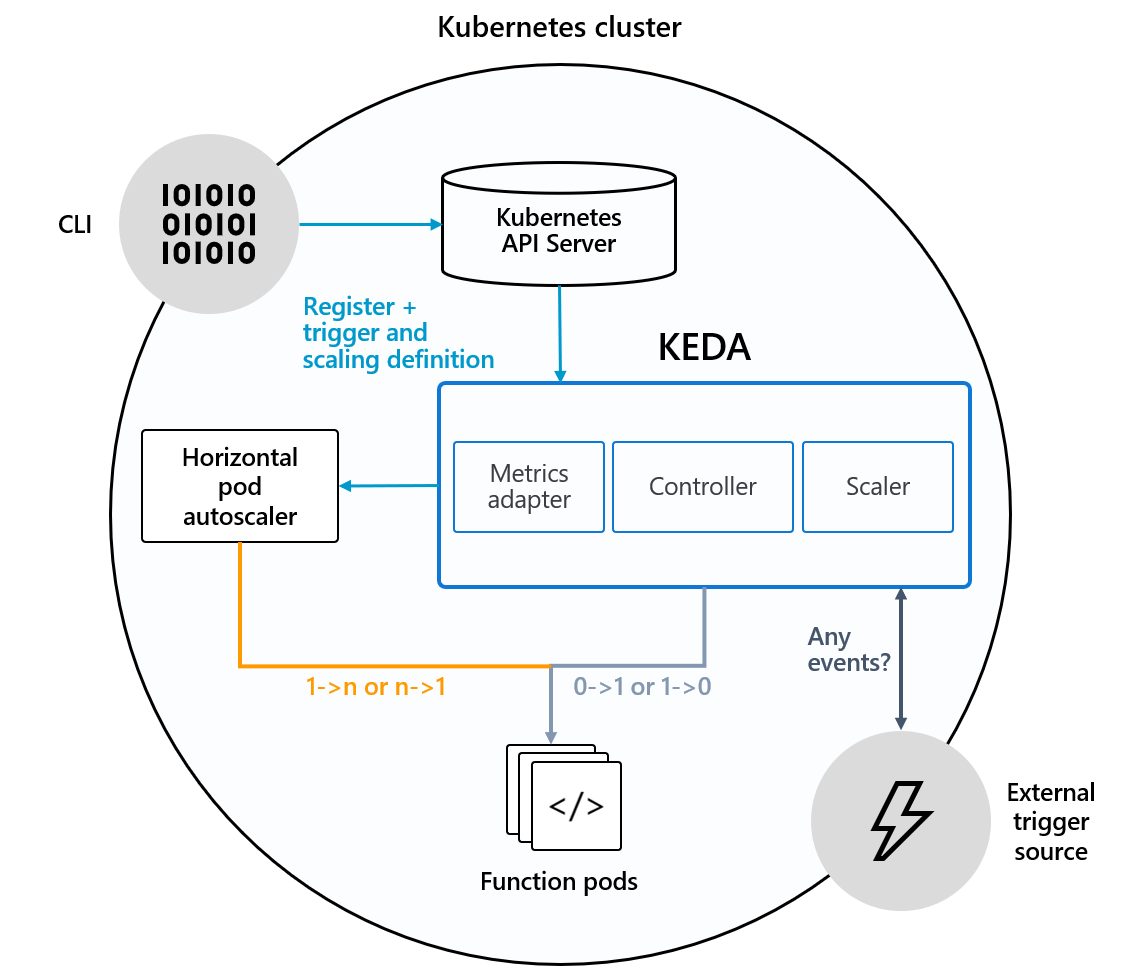
KEDA的架構如下圖所示:
從這個架構圖,我們看到KEDA包含了3個組件,Metric Adapter給k8s的HPA提供度量指標讓其進行1-n/n-1的伸縮,Controller控制Pod進行1-0/0-1的伸縮,Scaler偵聽配置的觸發器所觸發的事件。
且支持的伸縮器涵蓋了大部分主流雲組件或中間件:
- Apache Kafka
- AWS CloudWatch
- AWS Kinesis Stream
- AWS SQS Queue
- Azure Blob Storage
- Azure Event Hubs
- Azure Monitor
- Azure Service Bus
- Azure Storage Queue
- External
- GCP Pub/Sub
- Huawei Cloudeye
- Liiklus Topic
- MySQL
- NATS Streaming
- PostgreSQL
- Prometheus
- RabbitMQ Queue
- Redis List
演示
既然Azure Functions是開源技術,為了驗證技術中立性,在演示過程中特意選擇了阿里雲的ACK作為運行環境(Kubernetes託管版),並使用RabbitMQ作為伸縮觸發器。
同時,我們採用C#/.NET Core來作為函數的開發語言。為什麼用這個選擇,是因為有第三方對AWS Lambda上的支持的語言進行了性能測試,得到的結論是.NET Core的C#和F#語言性能最高:
來源:https://read.acloud.guru/comparing-aws-lambda-performance-of-node-js-python-java-c-and-go-29c1163c2581
環境準備
首先,需要到阿里雲上創建一個k8s集群,創建的選項截圖如下:
通過如下命令來部署KEDA到k8s:
helm repo add kedacore https://kedacore.github.io/charts
kubectl create namespace keda
helm install keda kedacore/keda --namespace keda
通過如下命令來部署RabbitMQ到k8s:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install rabbitmq --set rabbitmq.password=PASSWORD,service.type=LoadBalancer bitnami/rabbitmq
這裏需要注意(當然也可能是我打開方式不對),阿里雲的ACK不能自動創建pv,所以rabbitmq部署後會有問題,所以需要到阿里雲的ACK的控制面板裏面手動創建pv,並重建rabbitmq所需的同名pvc。
創建Azure Functions項目
訪問:https://github.com/Azure/azure-functions-core-tools,安裝命令行工具。
在命令行中輸入:
func init --docker
來初始化一個帶有Dockerfile的Azure Functions項目,worker runtime選擇dotnet。
在命令行中輸入:
func function create
來創建一個函數,template選擇QueueTrigger,輸入你想要的函數名稱。
使用你喜歡的編輯器(比如VSCode)打開項目文件夾,修改csproj文件中的PackageReference為如下內容:
<ItemGroup>
<PackageReference Include="Microsoft.NET.Sdk.Functions" Version="3.0.3" />
<PackageReference Include="Microsoft.Azure.WebJobs.Extensions.RabbitMQ" Version="0.2.2029-beta" />
</ItemGroup>
修改函數代碼為如下內容:
[FunctionName("MyMqFunction")]
public static void Run(
[RabbitMQTrigger("queue", ConnectionStringSetting = "RabbitMqConnection")] string inputMessage,
[RabbitMQ(QueueName = "downstream", ConnectionStringSetting = "RabbitMqConnection")] out string outputMessage,
ILogger log)
{
Thread.Sleep(5000);
outputMessage = inputMessage;
log.LogInformation($"RabittMQ output binding function sent message: {outputMessage}");
}
這個函數從一個名為”queue“的隊列中讀取inputMessage,延遲5秒后,把消息存儲到名為”downstream”的隊列中。
打開local.settings.json文件,在Values節點下添加RabbitMqConnection:
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "dotnet",
"RabbitMqConnection":"amqp://user:PASSWORD@rabbitmq.default.svc.cluster.local:5672"
},
這裏RabbitMQ的地址使用了k8s內部的默認Service地址,為了方便本地調試,你可以獲取到RabbitMQ在k8s的公網IP后,給這個域名添加host配置。
在命令行中輸入:
func start
就可以進行本地調試了。調試無誤,就可以進行發布到k8s的工作了。
以上示例代碼可以在這裏找到:https://github.com/heavenwing/AzFuncOnK8S
發布函數到k8s並驗證伸縮能力
考慮到我用的阿里雲拉取Docker Hub比較慢,所以我是編譯出Docker Image后,push到了阿里雲的鏡像倉庫當中。 另外,我這裏還遇到一個問題,就是能在AKS中正常運行的Docker Image在ACK中無法正常運行,出現”Access to the path ‘/proc/1/map_files’ is denied”的錯誤,我的臨時解決辦法是修改Dockerfile文件,添加WORKDIR命令。
在把Docker Image推送到鏡像倉庫后,可以在命令行中輸入:
func kubernetes deploy --name azfunconk8s --image-name registry.cn-chengdu.aliyuncs.com/zygcloud/azfunconk8s:latest --dry-run > deploy-funcs.yaml
得到部署的yaml文件后,我們需要對ScaledObject進行一點修改,為rabbitmq的trigger配置添加queueLength,根據需要配置maxReplicaCount屬性,如下所示:
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: azfunconk8s
namespace: default
labels:
deploymentName: azfunconk8s
spec:
scaleTargetRef:
deploymentName: azfunconk8s
maxReplicaCount: 20
triggers:
- type: rabbitmq
metadata:
type: rabbitMQTrigger
queueName: queue
name: inputMessage
host: RabbitMqConnection
queueLength: "20"
現在就可以把函數部署到k8s了,在命令行中輸入:
kubectl apply -f .\deploy\deploy-funcs.yaml
這個時候應該可以看到k8s出現了名為azfunconk8s的Deployment,且需要實例和運行實例數都是為0:
另外寫一個小程序,往RabbitMQ的queue隊列裏面放一些測試消息,經過30秒(默認pollingInterval時間)那麼就會看到這個Deployment的所需實例數在提高,一直提高到你設置的maxReplicaCount。等隊列中的消息處理完成,又會看到所需實例數在降低,等沒有消息需要處理之後過上5分鐘(默認cooldownPeriod時間),所需實例數就會變為0。
紅包
能看到這裏的小夥伴都是愛學習的,應該紅包獎勵,不過當然是需要回答問題的。
問:KEDA解決的是非http的觸發器伸縮,那麼什麼東西可以解決http觸發器伸縮問題?
在我的公眾號中輸入答案,獲取支付寶紅包口令,數量有限先答對先得。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※聚甘新



.jpg)