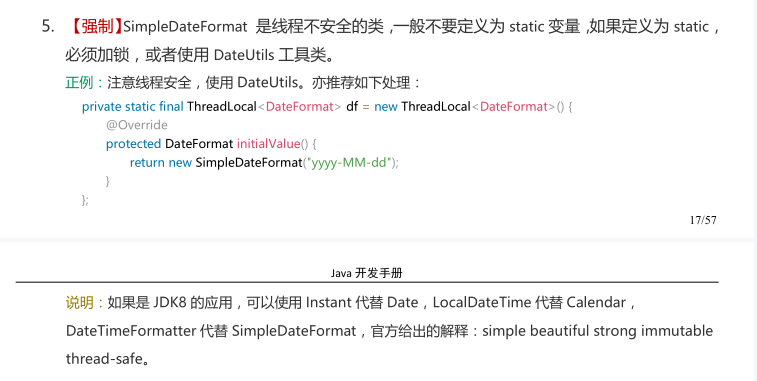
在JDK8之前,處理日期時間,我們主要使用3個類,Date、SimpleDateFormat和Calendar。
這3個類在使用時都或多或少的存在一些問題,比如SimpleDateFormat不是線程安全的,
比如Date和Calendar獲取到的月份是0到11,而不是現實生活中的1到12,關於這一點,《阿里巴巴Java開發手冊》中也有提及,因為很容易犯錯:
不過,JDK8推出了全新的日期時間處理類解決了這些問題,比如Instant、LocalDate、LocalTime、LocalDateTime、DateTimeFormatter,在《阿里巴巴Java開發手冊》中也推薦使用Instant、
LocalDateTime、DateTimeFormatter:
但我發現好多項目中其實並沒有使用這些類,使用的還是之前的Date、SimpleDateFormat和Calendar,所以本篇博客就講解下JDK8新推出的日期時間類,主要是下面幾個:
- Instant
- LocalDate
- LocalTime
- LocalDateTime
- DateTimeFormatter
1. Instant
1.1 獲取當前時間
既然Instant可以代替Date類,那它肯定可以獲取當前時間:
Instant instant = Instant.now();
System.out.println(instant);
輸出結果:
2020-06-10T08:22:13.759Z
細心的你會發現,這個時間比北京時間少了8個小時,如果要輸出北京時間,可以加上默認時區:
System.out.println(instant.atZone(ZoneId.systemDefault()));
輸出結果:
2020-06-10T16:22:13.759+08:00[Asia/Shanghai]
1.2 獲取時間戳
Instant instant = Instant.now();
// 當前時間戳:單位為秒
System.out.println(instant.getEpochSecond());
// 當前時間戳:單位為毫秒
System.out.println(instant.toEpochMilli());
輸出結果:
1591777752
1591777752613
當然,也可以通過System.currentTimeMillis()獲取當前毫秒數。
1.3 將long轉換為Instant
1)根據秒數時間戳轉換:
Instant instant = Instant.now();
System.out.println(instant);
long epochSecond = instant.getEpochSecond();
System.out.println(Instant.ofEpochSecond(epochSecond));
System.out.println(Instant.ofEpochSecond(epochSecond, instant.getNano()));
輸出結果:
2020-06-10T08:40:54.046Z
2020-06-10T08:40:54Z
2020-06-10T08:40:54.046Z
2)根據毫秒數時間戳轉換:
Instant instant = Instant.now();
System.out.println(instant);
long epochMilli = instant.toEpochMilli();
System.out.println(Instant.ofEpochMilli(epochMilli));
輸出結果:
2020-06-10T08:43:25.607Z
2020-06-10T08:43:25.607Z
1.4 將String轉換為Instant
String text = "2020-06-10T08:46:55.967Z";
Instant parseInstant = Instant.parse(text);
System.out.println("秒時間戳:" + parseInstant.getEpochSecond());
System.out.println("豪秒時間戳:" + parseInstant.toEpochMilli());
System.out.println("納秒:" + parseInstant.getNano());
輸出結果:
秒時間戳:1591778815
豪秒時間戳:1591778815967
納秒:967000000
如果字符串格式不對,比如修改成2020-06-10T08:46:55.967,就會拋出java.time.format.DateTimeParseException異常,如下圖所示:
2. LocalDate
2.1 獲取當前日期
使用LocalDate獲取當前日期非常簡單,如下所示:
LocalDate today = LocalDate.now();
System.out.println("today: " + today);
輸出結果:
today: 2020-06-10
不用任何格式化,輸出結果就非常友好,如果使用Date,輸出這樣的格式,還得配合SimpleDateFormat指定yyyy-MM-dd進行格式化,一不小心還會出個bug,比如去年年底很火的1個bug,我當時還是截了圖的:
這2個好友是2019/12/31關注我的,但我2020年1月2號查看時,卻显示成了2020/12/31,為啥呢?格式化日期時格式寫錯了,應該是yyyy/MM/dd,卻寫成了YYYY/MM/dd,剛好那周跨年,就显示成下一年,也就是2020年了,當時好幾個博主寫過文章解析原因,我這裏就不做過多解釋了。
划重點:都說到這了,給大家安利下我新註冊的公眾號「申城異鄉人」,歡迎大家關注,更多原創文章等着你哦,哈哈。
2.2 獲取年月日
LocalDate today = LocalDate.now();
int year = today.getYear();
int month = today.getMonthValue();
int day = today.getDayOfMonth();
System.out.println("year: " + year);
System.out.println("month: " + month);
System.out.println("day: " + day);
輸出結果:
year: 2020
month: 6
day: 10
獲取月份終於返回1到12了,不像java.util.Calendar獲取月份返回的是0到11,獲取完還得加1。
2.3 指定日期
LocalDate specifiedDate = LocalDate.of(2020, 6, 1);
System.out.println("specifiedDate: " + specifiedDate);
輸出結果:
specifiedDate: 2020-06-01
如果確定月份,推薦使用另一個重載方法,使用枚舉指定月份:
LocalDate specifiedDate = LocalDate.of(2020, Month.JUNE, 1);
2.4 比較日期是否相等
LocalDate localDate1 = LocalDate.now();
LocalDate localDate2 = LocalDate.of(2020, 6, 10);
if (localDate1.equals(localDate2)) {
System.out.println("localDate1 equals localDate2");
}
輸出結果:
localDate1 equals localDate2
2.5 獲取日期是本周/本月/本年的第幾天
LocalDate today = LocalDate.now();
System.out.println("Today:" + today);
System.out.println("Today is:" + today.getDayOfWeek());
System.out.println("今天是本周的第" + today.getDayOfWeek().getValue() + "天");
System.out.println("今天是本月的第" + today.getDayOfMonth() + "天");
System.out.println("今天是本年的第" + today.getDayOfYear() + "天");
輸出結果:
Today:2020-06-11
Today is:THURSDAY
今天是本周的第4天
今天是本月的第11天
今天是本年的第163天
2.6 判斷是否為閏年
LocalDate today = LocalDate.now();
System.out.println(today.getYear() + " is leap year:" + today.isLeapYear());
輸出結果:
2020 is leap year:true
3. LocalTime
3.1 獲取時分秒
如果使用java.util.Date,那代碼是下面這樣的:
Date date = new Date();
int hour = date.getHours();
int minute = date.getMinutes();
int second = date.getSeconds();
System.out.println("hour: " + hour);
System.out.println("minute: " + minute);
System.out.println("second: " + second);
輸出結果:
注意事項:這幾個方法已經過期了,因此強烈不建議在項目中使用:
如果使用java.util.Calendar,那代碼是下面這樣的:
Calendar calendar = Calendar.getInstance();
// 12小時制
int hourOf12 = calendar.get(Calendar.HOUR);
// 24小時制
int hourOf24 = calendar.get(Calendar.HOUR_OF_DAY);
int minute = calendar.get(Calendar.MINUTE);
int second = calendar.get(Calendar.SECOND);
int milliSecond = calendar.get(Calendar.MILLISECOND);
System.out.println("hourOf12: " + hourOf12);
System.out.println("hourOf24: " + hourOf24);
System.out.println("minute: " + minute);
System.out.println("second: " + second);
System.out.println("milliSecond: " + milliSecond);
輸出結果:
注意事項:獲取小時時,有2個選項,1個返回12小時制的小時數,1個返回24小時制的小時數,因為現在是晚上8點,所以calendar.get(Calendar.HOUR)返回8,而calendar.get(Calendar.HOUR_OF_DAY)返回20。
如果使用java.time.LocalTime,那代碼是下面這樣的:
LocalTime localTime = LocalTime.now();
System.out.println("localTime:" + localTime);
int hour = localTime.getHour();
int minute = localTime.getMinute();
int second = localTime.getSecond();
System.out.println("hour: " + hour);
System.out.println("minute: " + minute);
System.out.println("second: " + second);
輸出結果:
可以看出,LocalTime只有時間沒有日期。
4. LocalDateTime
4.1 獲取當前時間
LocalDateTime localDateTime = LocalDateTime.now();
System.out.println("localDateTime:" + localDateTime);
輸出結果:
localDateTime: 2020-06-11T11:03:21.376
4.2 獲取年月日時分秒
LocalDateTime localDateTime = LocalDateTime.now();
System.out.println("localDateTime: " + localDateTime);
System.out.println("year: " + localDateTime.getYear());
System.out.println("month: " + localDateTime.getMonthValue());
System.out.println("day: " + localDateTime.getDayOfMonth());
System.out.println("hour: " + localDateTime.getHour());
System.out.println("minute: " + localDateTime.getMinute());
System.out.println("second: " + localDateTime.getSecond());
輸出結果:
4.3 增加天數/小時
LocalDateTime localDateTime = LocalDateTime.now();
System.out.println("localDateTime: " + localDateTime);
LocalDateTime tomorrow = localDateTime.plusDays(1);
System.out.println("tomorrow: " + tomorrow);
LocalDateTime nextHour = localDateTime.plusHours(1);
System.out.println("nextHour: " + nextHour);
輸出結果:
localDateTime: 2020-06-11T11:13:44.979
tomorrow: 2020-06-12T11:13:44.979
nextHour: 2020-06-11T12:13:44.979
LocalDateTime還提供了添加年、周、分鐘、秒這些方法,這裏就不一一列舉了:
4.4 減少天數/小時
LocalDateTime localDateTime = LocalDateTime.now();
System.out.println("localDateTime: " + localDateTime);
LocalDateTime yesterday = localDateTime.minusDays(1);
System.out.println("yesterday: " + yesterday);
LocalDateTime lastHour = localDateTime.minusHours(1);
System.out.println("lastHour: " + lastHour);
輸出結果:
localDateTime: 2020-06-11T11:20:38.896
yesterday: 2020-06-10T11:20:38.896
lastHour: 2020-06-11T10:20:38.896
類似的,LocalDateTime還提供了減少年、周、分鐘、秒這些方法,這裏就不一一列舉了:
4.5 獲取時間是本周/本年的第幾天
LocalDateTime localDateTime = LocalDateTime.now();
System.out.println("localDateTime: " + localDateTime);
System.out.println("DayOfWeek: " + localDateTime.getDayOfWeek().getValue());
System.out.println("DayOfYear: " + localDateTime.getDayOfYear());
輸出結果:
localDateTime: 2020-06-11T11:32:31.731
DayOfWeek: 4
DayOfYear: 163
5. DateTimeFormatter
JDK8中推出了java.time.format.DateTimeFormatter來處理日期格式化問題,《阿里巴巴Java開發手冊》中也是建議使用DateTimeFormatter代替SimpleDateFormat。
5.1 格式化LocalDate
LocalDate localDate = LocalDate.now();
System.out.println("ISO_DATE: " + localDate.format(DateTimeFormatter.ISO_DATE));
System.out.println("BASIC_ISO_DATE: " + localDate.format(DateTimeFormatter.BASIC_ISO_DATE));
System.out.println("ISO_WEEK_DATE: " + localDate.format(DateTimeFormatter.ISO_WEEK_DATE));
System.out.println("ISO_ORDINAL_DATE: " + localDate.format(DateTimeFormatter.ISO_ORDINAL_DATE));
輸出結果:
如果提供的格式無法滿足你的需求,你還可以像以前一樣自定義格式:
LocalDate localDate = LocalDate.now();
System.out.println("yyyy/MM/dd: " + localDate.format(DateTimeFormatter.ofPattern("yyyy/MM/dd")));
輸出結果:
yyyy/MM/dd: 2020/06/11
5.2 格式化LocalTime
LocalTime localTime = LocalTime.now();
System.out.println(localTime);
System.out.println("ISO_TIME: " + localTime.format(DateTimeFormatter.ISO_TIME));
System.out.println("HH:mm:ss: " + localTime.format(DateTimeFormatter.ofPattern("HH:mm:ss")));
輸出結果:
14:28:35.230
ISO_TIME: 14:28:35.23
HH:mm:ss: 14:28:35
5.3 格式化LocalDateTime
LocalDateTime localDateTime = LocalDateTime.now();
System.out.println(localDateTime);
System.out.println("ISO_DATE_TIME: " + localDateTime.format(DateTimeFormatter.ISO_DATE_TIME));
System.out.println("ISO_DATE: " + localDateTime.format(DateTimeFormatter.ISO_DATE));
輸出結果:
2020-06-11T14:33:18.303
ISO_DATE_TIME: 2020-06-11T14:33:18.303
ISO_DATE: 2020-06-11
6. 類型相互轉換
6.1 Instant轉Date
JDK8中,Date新增了from()方法,將Instant轉換為Date,代碼如下所示:
Instant instant = Instant.now();
System.out.println(instant);
Date dateFromInstant = Date.from(instant);
System.out.println(dateFromInstant);
輸出結果:
2020-06-11T06:39:34.979Z
Thu Jun 11 14:39:34 CST 2020
6.2 Date轉Instant
JDK8中,Date新增了toInstant方法,將Date轉換為Instant,代碼如下所示:
Date date = new Date();
Instant dateToInstant = date.toInstant();
System.out.println(date);
System.out.println(dateToInstant);
輸出結果:
Thu Jun 11 14:46:12 CST 2020
2020-06-11T06:46:12.112Z
6.3 Date轉LocalDateTime
Date date = new Date();
Instant instant = date.toInstant();
LocalDateTime localDateTimeOfInstant = LocalDateTime.ofInstant(instant, ZoneId.systemDefault());
System.out.println(date);
System.out.println(localDateTimeOfInstant);
輸出結果:
Thu Jun 11 14:51:07 CST 2020
2020-06-11T14:51:07.904
6.4 Date轉LocalDate
Date date = new Date();
Instant instant = date.toInstant();
LocalDateTime localDateTimeOfInstant = LocalDateTime.ofInstant(instant, ZoneId.systemDefault());
LocalDate localDate = localDateTimeOfInstant.toLocalDate();
System.out.println(date);
System.out.println(localDate);
輸出結果:
Thu Jun 11 14:59:38 CST 2020
2020-06-11
可以看出,Date是先轉換為Instant,再轉換為LocalDateTime,然後通過LocalDateTime獲取LocalDate。
6.5 Date轉LocalTime
Date date = new Date();
Instant instant = date.toInstant();
LocalDateTime localDateTimeOfInstant = LocalDateTime.ofInstant(instant, ZoneId.systemDefault());
LocalTime toLocalTime = localDateTimeOfInstant.toLocalTime();
System.out.println(date);
System.out.println(toLocalTime);
輸出結果:
Thu Jun 11 15:06:14 CST 2020
15:06:14.531
可以看出,Date是先轉換為Instant,再轉換為LocalDateTime,然後通過LocalDateTime獲取LocalTime。
6.6 LocalDateTime轉Date
LocalDateTime localDateTime = LocalDateTime.now();
Instant toInstant = localDateTime.atZone(ZoneId.systemDefault()).toInstant();
Date dateFromInstant = Date.from(toInstant);
System.out.println(localDateTime);
System.out.println(dateFromInstant);
輸出結果:
2020-06-11T15:12:11.600
Thu Jun 11 15:12:11 CST 2020
6.7 LocalDate轉Date
LocalDate today = LocalDate.now();
LocalDateTime localDateTime = localDate.atStartOfDay();
Instant toInstant = localDateTime.atZone(ZoneId.systemDefault()).toInstant();
Date dateFromLocalDate = Date.from(toInstant);
System.out.println(dateFromLocalDate);
輸出結果:
Thu Jun 11 00:00:00 CST 2020
6.8 LocalTime轉Date
LocalDate localDate = LocalDate.now();
LocalTime localTime = LocalTime.now();
LocalDateTime localDateTime = LocalDateTime.of(localDate, localTime);
Instant instantFromLocalTime = localDateTime.atZone(ZoneId.systemDefault()).toInstant();
Date dateFromLocalTime = Date.from(instantFromLocalTime);
System.out.println(dateFromLocalTime);
輸出結果:
Thu Jun 11 15:24:18 CST 2020
7. 總結
JDK8推出了全新的日期時間類,如Instant、LocaleDate、LocalTime、LocalDateTime、DateTimeFormatter,設計比之前更合理,也是線程安全的。
《阿里巴巴Java開發規範》中也推薦使用Instant代替Date,LocalDateTime 代替 Calendar,DateTimeFormatter 代替 SimpleDateFormat。
因此,如果條件允許,建議在項目中使用,沒有使用的,可以考慮升級下。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益