在本人的博客里,分享了有關中值模糊的O(1)算法,詳見:任意半徑中值濾波(擴展至百分比濾波器)O(1)時間複雜度算法的原理、實現及效果 ,這裏的算法的執行時間和參數是無關的。整體來說,雖然速度也很快,但是在某些特殊情況下我們還是需要更快的速度。特別是對於小半徑的中值,我們有理由去對其進一步的優化的。本文我們進一步探討這個問題。
一、3*3中值模糊
首先我們來看看半徑為1的中值,此時涉及到的領域為3*3,共9個像素,那麼最傳統的實現方式就是對9個像素直接進行排序,這裏我們直接使用系統的排序函數qsort,一種簡單的代碼如下所示:
int __cdecl ComparisonFunction(const void *X, const void *Y) // 一定要用__cdecl這個標識符
{ unsigned char Dx = *(unsigned char *)X; unsigned char Dy = *(unsigned char *)Y; if (Dx < Dy) return -1; else if (Dx > Dy) return +1; else
return 0; } void MedianBlur3X3_Ori(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride) { int Channel = Stride / Width; if (Channel == 1) { unsigned char Array[9]; for (int Y = 1; Y < Height - 1; Y++) { unsigned char *LineP0 = Src + (Y - 1) * Stride + 1; unsigned char *LineP1 = LineP0 + Stride; unsigned char *LineP2 = LineP1 + Stride; unsigned char *LinePD = Dest + Y * Stride + 1; for (int X = 1; X < Width - 1; X++) { Array[0] = LineP0[X - 1]; Array[1] = LineP0[X]; Array[2] = LineP0[X + 1]; Array[3] = LineP1[X - 1]; Array[4] = LineP1[X]; Array[5] = LineP2[X + 1]; Array[6] = LineP2[X - 1]; Array[7] = LineP2[X]; Array[8] = LineP2[X + 1]; qsort(Array, 9, sizeof(unsigned char), &ComparisonFunction); LinePD[X] = Array[4]; } } } else { unsigned char ArrayB[9], ArrayG[9], ArrayR[9]; for (int Y = 1; Y < Height - 1; Y++) { unsigned char *LineP0 = Src + (Y - 1) * Stride + 3; unsigned char *LineP1 = LineP0 + Stride; unsigned char *LineP2 = LineP1 + Stride; unsigned char *LinePD = Dest + Y * Stride + 3; for (int X = 1; X < Width - 1; X++) { ArrayB[0] = LineP0[-3]; ArrayG[0] = LineP0[-2]; ArrayR[0] = LineP0[-1]; ArrayB[1] = LineP0[0]; ArrayG[1] = LineP0[1]; ArrayR[1] = LineP0[2]; ArrayB[2] = LineP0[3]; ArrayG[2] = LineP0[4]; ArrayR[2] = LineP0[5]; ArrayB[3] = LineP1[-3]; ArrayG[3] = LineP1[-2]; ArrayR[3] = LineP1[-1]; ArrayB[4] = LineP1[0]; ArrayG[4] = LineP1[1]; ArrayR[4] = LineP1[2]; ArrayB[5] = LineP1[3]; ArrayG[5] = LineP1[4]; ArrayR[5] = LineP1[5]; ArrayB[6] = LineP2[-3]; ArrayG[6] = LineP2[-2]; ArrayR[6] = LineP2[-1]; ArrayB[7] = LineP2[0]; ArrayG[7] = LineP2[1]; ArrayR[7] = LineP2[2]; ArrayB[8] = LineP2[3]; ArrayG[8] = LineP2[4]; ArrayR[8] = LineP2[5]; qsort(ArrayB, 9, sizeof(unsigned char), &ComparisonFunction); qsort(ArrayG, 9, sizeof(unsigned char), &ComparisonFunction); qsort(ArrayR, 9, sizeof(unsigned char), &ComparisonFunction); LinePD[0] = ArrayB[4]; LinePD[1] = ArrayG[4]; LinePD[2] = ArrayR[4]; LineP0 += 3; LineP1 += 3; LineP2 += 3; LinePD += 3; } } } }
代碼很簡潔和清晰,我們沒有處理邊緣的那一圈像素,這無關精要,我們編譯后測試,結果如下所示:
1920*1080大小的24位圖像,平均用時1280ms,灰度圖像平均用時460ms,這相當的慢,無法接受。
下面我們稍微對其進行下提速。
對於9個數據的排序,我們可以對其進行特殊的處理,因為數據的個數是確定的,按照理論分析,沒有必要進行大規模的比較,實際只需要進行19次比較就可以了。修改后算法如下所示:
inline void Swap(int &X, int &Y) { X ^= Y; Y ^= X; X ^= Y; } void MedianBlur3X3_Faster(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride) { int Channel = Stride / Width; if (Channel == 1) { for (int Y = 1; Y < Height - 1; Y++) { unsigned char *LineP0 = Src + (Y - 1) * Stride + 1; unsigned char *LineP1 = LineP0 + Stride; unsigned char *LineP2 = LineP1 + Stride; unsigned char *LinePD = Dest + Y * Stride + 1; for (int X = 1; X < Width - 1; X++) { int Gray0, Gray1, Gray2, Gray3, Gray4, Gray5, Gray6, Gray7, Gray8; Gray0 = LineP0[X - 1]; Gray1 = LineP0[X]; Gray2 = LineP0[X + 1]; Gray3 = LineP1[X - 1]; Gray4 = LineP1[X]; Gray5 = LineP2[X + 1]; Gray6 = LineP2[X - 1]; Gray7 = LineP2[X]; Gray8 = LineP2[X + 1]; if (Gray1 > Gray2) Swap(Gray1, Gray2); if (Gray4 > Gray5) Swap(Gray4, Gray5); if (Gray7 > Gray8) Swap(Gray7, Gray8); if (Gray0 > Gray1) Swap(Gray0, Gray1); if (Gray3 > Gray4) Swap(Gray3, Gray4); if (Gray6 > Gray7) Swap(Gray6, Gray7); if (Gray1 > Gray2) Swap(Gray1, Gray2); if (Gray4 > Gray5) Swap(Gray4, Gray5); if (Gray7 > Gray8) Swap(Gray7, Gray8); if (Gray0 > Gray3) Swap(Gray0, Gray3); if (Gray5 > Gray8) Swap(Gray5, Gray8); if (Gray4 > Gray7) Swap(Gray4, Gray7); if (Gray3 > Gray6) Swap(Gray3, Gray6); if (Gray1 > Gray4) Swap(Gray1, Gray4); if (Gray2 > Gray5) Swap(Gray2, Gray5); if (Gray4 > Gray7) Swap(Gray4, Gray7); if (Gray4 > Gray2) Swap(Gray4, Gray2); if (Gray6 > Gray4) Swap(Gray6, Gray4); if (Gray4 > Gray2) Swap(Gray4, Gray2); LinePD[X] = Gray4; } } } else { for (int Y = 1; Y < Height - 1; Y++) { unsigned char *LineP0 = Src + (Y - 1) * Stride + 3; unsigned char *LineP1 = LineP0 + Stride; unsigned char *LineP2 = LineP1 + Stride; unsigned char *LinePD = Dest + Y * Stride + 3; for (int X = 1; X < Width - 1; X++) { int Blue0, Blue1, Blue2, Blue3, Blue4, Blue5, Blue6, Blue7, Blue8; int Green0, Green1, Green2, Green3, Green4, Green5, Green6, Green7, Green8; int Red0, Red1, Red2, Red3, Red4, Red5, Red6, Red7, Red8; Blue0 = LineP0[-3]; Green0 = LineP0[-2]; Red0 = LineP0[-1]; Blue1 = LineP0[0]; Green1 = LineP0[1]; Red1 = LineP0[2]; Blue2 = LineP0[3]; Green2 = LineP0[4]; Red2 = LineP0[5]; Blue3 = LineP1[-3]; Green3 = LineP1[-2]; Red3 = LineP1[-1]; Blue4 = LineP1[0]; Green4 = LineP1[1]; Red4 = LineP1[2]; Blue5 = LineP1[3]; Green5 = LineP1[4]; Red5 = LineP1[5]; Blue6 = LineP2[-3]; Green6 = LineP2[-2]; Red6 = LineP2[-1]; Blue7 = LineP2[0]; Green7 = LineP2[1]; Red7 = LineP2[2]; Blue8 = LineP2[3]; Green8 = LineP2[4]; Red8 = LineP2[5]; if (Blue1 > Blue2) Swap(Blue1, Blue2); if (Blue4 > Blue5) Swap(Blue4, Blue5); if (Blue7 > Blue8) Swap(Blue7, Blue8); if (Blue0 > Blue1) Swap(Blue0, Blue1); if (Blue3 > Blue4) Swap(Blue3, Blue4); if (Blue6 > Blue7) Swap(Blue6, Blue7); if (Blue1 > Blue2) Swap(Blue1, Blue2); if (Blue4 > Blue5) Swap(Blue4, Blue5); if (Blue7 > Blue8) Swap(Blue7, Blue8); if (Blue0 > Blue3) Swap(Blue0, Blue3); if (Blue5 > Blue8) Swap(Blue5, Blue8); if (Blue4 > Blue7) Swap(Blue4, Blue7); if (Blue3 > Blue6) Swap(Blue3, Blue6); if (Blue1 > Blue4) Swap(Blue1, Blue4); if (Blue2 > Blue5) Swap(Blue2, Blue5); if (Blue4 > Blue7) Swap(Blue4, Blue7); if (Blue4 > Blue2) Swap(Blue4, Blue2); if (Blue6 > Blue4) Swap(Blue6, Blue4); if (Blue4 > Blue2) Swap(Blue4, Blue2); if (Green1 > Green2) Swap(Green1, Green2); if (Green4 > Green5) Swap(Green4, Green5); if (Green7 > Green8) Swap(Green7, Green8); if (Green0 > Green1) Swap(Green0, Green1); if (Green3 > Green4) Swap(Green3, Green4); if (Green6 > Green7) Swap(Green6, Green7); if (Green1 > Green2) Swap(Green1, Green2); if (Green4 > Green5) Swap(Green4, Green5); if (Green7 > Green8) Swap(Green7, Green8); if (Green0 > Green3) Swap(Green0, Green3); if (Green5 > Green8) Swap(Green5, Green8); if (Green4 > Green7) Swap(Green4, Green7); if (Green3 > Green6) Swap(Green3, Green6); if (Green1 > Green4) Swap(Green1, Green4); if (Green2 > Green5) Swap(Green2, Green5); if (Green4 > Green7) Swap(Green4, Green7); if (Green4 > Green2) Swap(Green4, Green2); if (Green6 > Green4) Swap(Green6, Green4); if (Green4 > Green2) Swap(Green4, Green2); if (Red1 > Red2) Swap(Red1, Red2); if (Red4 > Red5) Swap(Red4, Red5); if (Red7 > Red8) Swap(Red7, Red8); if (Red0 > Red1) Swap(Red0, Red1); if (Red3 > Red4) Swap(Red3, Red4); if (Red6 > Red7) Swap(Red6, Red7); if (Red1 > Red2) Swap(Red1, Red2); if (Red4 > Red5) Swap(Red4, Red5); if (Red7 > Red8) Swap(Red7, Red8); if (Red0 > Red3) Swap(Red0, Red3); if (Red5 > Red8) Swap(Red5, Red8); if (Red4 > Red7) Swap(Red4, Red7); if (Red3 > Red6) Swap(Red3, Red6); if (Red1 > Red4) Swap(Red1, Red4); if (Red2 > Red5) Swap(Red2, Red5); if (Red4 > Red7) Swap(Red4, Red7); if (Red4 > Red2) Swap(Red4, Red2); if (Red6 > Red4) Swap(Red6, Red4); if (Red4 > Red2) Swap(Red4, Red2); LinePD[0] = Blue4; LinePD[1] = Green4; LinePD[2] = Red4; LineP0 += 3; LineP1 += 3; LineP2 += 3; LinePD += 3; } } } }
看上去代碼的行數多了,但是實際上執行速度回更快,我們測試的結果如下:
1920*1080大小的24位圖像,平均用時155ms,灰度圖像平均用時45ms,比之前的原始實現速度要快了近10倍。
而在任意半徑中值濾波(擴展至百分比濾波器)O(1)時間複雜度算法的原理、實現及效果一文中的算法,採用了SSE優化,同樣大小的圖耗時為:
1920*1080大小的24位圖像,平均用時260ms,灰度圖像平均用時160ms,比上述的C語言版本要慢。
早期有朋友曾提示我在手機上使用Neon可以做到16MB的圖像半徑為1的中值模糊可以做到20ms,我真的一點也不敢相信。總覺得不太可思議。16MB可是4000*4000的大小啊,我用上述C的代碼處理起來要242ms,比手機端還慢了10倍。
經過朋友提醒,在https://github.com/ARM-software/ComputeLibrary/blob/master/src/core/NEON/kernels/NEMedian3x3Kernel.cpp#L113上看到了相關的Neon代碼,驚奇的發現他和我上面的C代碼幾乎完全一樣。但是就是這一點代碼提醒了我。
inline void sort(uint8x8_t &a, uint8x8_t &b) { const uint8x8_t min = vmin_u8(a, b); const uint8x8_t max = vmax_u8(a, b); a = min; b = max; }
真是一語驚醒夢中人啊,這麼簡單的優化我怎麼沒想到呢。
我們自己看看上面的C代碼,每個像素的9次比較雖然不能用SIMD指令做,但是多個像素的比較之間是相互不關聯的,因此,這樣我就可以一次性處理16個像素了,改成SSE優化的方式也就很簡單了:
inline void _mm_sort_ab(__m128i &a, __m128i &b) { const __m128i min = _mm_min_epu8(a, b); const __m128i max = _mm_max_epu8(a, b); a = min; b = max; } void MedianBlur3X3_SSE(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride) { int Channel = Stride / Width; int BlockSize = 16, Block = ((Width - 2)* Channel) / BlockSize; for (int Y = 1; Y < Height - 1; Y++) { unsigned char *LineP0 = Src + (Y - 1) * Stride + Channel; unsigned char *LineP1 = LineP0 + Stride; unsigned char *LineP2 = LineP1 + Stride; unsigned char *LinePD = Dest + Y * Stride + Channel; for (int X = 0; X < Block * BlockSize; X += BlockSize, LineP0 += BlockSize, LineP1 += BlockSize, LineP2 += BlockSize, LinePD += BlockSize) { __m128i P0 = _mm_loadu_si128((__m128i *)(LineP0 - Channel)); __m128i P1 = _mm_loadu_si128((__m128i *)(LineP0 - 0)); __m128i P2 = _mm_loadu_si128((__m128i *)(LineP0 + Channel)); __m128i P3 = _mm_loadu_si128((__m128i *)(LineP1 - Channel)); __m128i P4 = _mm_loadu_si128((__m128i *)(LineP1 - 0)); __m128i P5 = _mm_loadu_si128((__m128i *)(LineP1 + Channel)); __m128i P6 = _mm_loadu_si128((__m128i *)(LineP2 - Channel)); __m128i P7 = _mm_loadu_si128((__m128i *)(LineP2 - 0)); __m128i P8 = _mm_loadu_si128((__m128i *)(LineP2 + Channel)); _mm_sort_ab(P1, P2); _mm_sort_ab(P4, P5); _mm_sort_ab(P7, P8); _mm_sort_ab(P0, P1); _mm_sort_ab(P3, P4); _mm_sort_ab(P6, P7); _mm_sort_ab(P1, P2); _mm_sort_ab(P4, P5); _mm_sort_ab(P7, P8); _mm_sort_ab(P0, P3); _mm_sort_ab(P5, P8); _mm_sort_ab(P4, P7); _mm_sort_ab(P3, P6); _mm_sort_ab(P1, P4); _mm_sort_ab(P2, P5); _mm_sort_ab(P4, P7); _mm_sort_ab(P4, P2); _mm_sort_ab(P6, P4); _mm_sort_ab(P4, P2); _mm_storeu_si128((__m128i *)LinePD, P4); } for (int X = Block * BlockSize; X < (Width - 2) * Channel; X++, LinePD++) { // DO Something
} } }
注意到上面我已經把灰度和彩色圖像的代碼寫成同一個方式處理了,這是因為對於彩色圖像,3個通道之間的處理時毫無聯繫的。同時我們前面的Swap2個變量的過程時完全可以通過Min和Max兩個算子實現的,我們按下F5測試運行,驚人的速度出現了:
1920*1080大小的24位圖像,平均用時3ms,灰度圖像平均用時1ms,比上述的C語言版本快了近40倍。
順便也測試了下16MB的圖像,結果平均只需要7.5ms。真是太厲害了。
二、5*5中值模糊
對於5*5的中值模糊,優化的方式還是一樣的,但是5*5共計25個像素,理論上需要131次比較,其他的過程類似,測試基於SSE的方式,5*5的中值1920*1080大小的24位圖像,平均用時40ms,灰度圖像平均用時20ms,雖慢了很多,但是還是O(1)那裡的速度快。
三、蒙塵和划痕
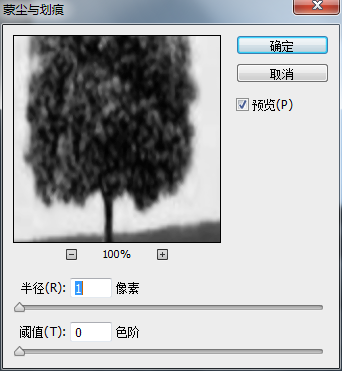
在這裏提Photoshop的這個算法也許並不是很合適,但是我也是在研究中值模糊時順便把這個算法給攻破的,當我們打開蒙塵和划痕界面時,發現其有半徑和閾值兩個參數,細心比價,如果閾值設置為0,則相同半徑設置時其結果圖像和雜色里的中間值算法的結果一模一樣,這也可以從蒙塵和划痕算法和中間值同樣都放在雜色菜單下可以看出端倪。
通過上述分析,我們可以肯定蒙塵和划痕算法是基於中值模糊的,實際上,PS里很多算法都是基於中值模糊的,特別是那些有平滑度參數的算法^_^。經過多次測試,我們得到的該算法的結果就是如下:
if (Median – Src) > Threshold
Dest = Median
else
Dest = Src
對於彩色圖像,不是用彩色圖的中值,而是用其亮度值作為唯一的判斷標準,如果用彩色的中值作為標準來判斷每個分量的,很容易出現過多的噪點,因為有可能會出現Blue分量改變,而Red不變的情況,或其他類似現象。
蒙塵和划痕的一個作用是去除噪點,特別的,我覺得他在小半徑的時候更為有用,小半徑中值不會改變原圖太多,加上這個閾值則可以很容易去除噪點,同時,基本不會出現新的模糊問題。比如下面這個圖。
原圖 半徑為1的中值模糊
半徑為1,閾值取20時的蒙塵和划痕 半徑為2,閾值取20時的蒙塵和划痕
由以上幾圖,可以明顯的看出,帶閾值的蒙塵和划痕在抑制了噪音的同時對原圖其他細節基本沒有破壞,因此,是一種比較合適的初級的預處理算法,既然是預處理,那麼其效率就非常重要了,因此本文的快速3*3模糊的作用也就是相當有用。
本文相關算法代碼下載地址:https://files.cnblogs.com/files/Imageshop/MedianBlur3X3.rar。
本人的SSE算法優化合集DEMO:測試Demo:http://files.cnblogs.com/files/Imageshop/SSE_Optimization_Demo.rar。
【精選推薦文章】
如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
想要讓你的商品在網路上成為最夯、最多人討論的話題?
網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師"嚨底家"!!