一.寫在前面
本系列中的內容來自對李宏毅老師的機器學習教程的理解和一些個人理解的筆記,主要用於之後方便查看複習。李宏毅老師的機器學習教程地址:https://www.bilibili.com/video/av35932863?from=search&seid=3902369523652897681。
二.機器學習概念
2.1人工智能、機器學習、深度學習這幾個概念的關係
要想理解清楚機器學習的基本概念,首先要明白機器學習在人工智能領域中所處的位置,再簡單明了些首先要明白人工智能、機器學習、深度學習這幾個概念的關係。三者關係如下圖2-1
圖2-1 人工智能、機器學習、深度學習三者關係
從圖可以直觀的看出,人工智能的範圍>機器學習的範圍>深度學習的範圍,而平時常說的神經網絡的這些有關概念則是屬於深度學習下的分支。再具體而言這三者的關係,其實人工智能是作為我們最終所要達到的目標,所謂的人工智能概念我覺的用之前某科學家提過的一種說法簡單理解一下就行,即當用一塊黑幕將計算機遮蓋起來,黑幕外的人無法區分所交互的對象是人還是計算機就算是達到了人工智能標準,再簡單點說就是使計算機做到過去只有人才能做到的事,其他更為深入的解釋歡迎查看百度詞條https://baike.baidu.com/item/人工智能/9180?fr=aladdin。而機器學習則是實現人工智能這一目標的手段,這說明還有其他手段有興趣的同學可以自行去了解一下,不過個人認為其餘的手段不是現在的主流研究方向吧。而深度學習則是作為機器學習下的一個重要分支。
2.2 理解機器學習
所謂機器學習概念,簡單的理解就是教會計算機學習,舉個具體的例子,當你給它看完貓的某一張圖片后,你告訴機器這是貓,當你給它看完一張狗的圖片后,你告訴它這是狗,不斷重複這一過程讓機器學習大量不同的貓狗照片,學習結束后給予機器一張全新的貓或狗的照片,機器能夠成功的識別出貓和狗。再進一步抽象的理解,我們可以發現這一過程十分類似於數學上求解函數表達式,即這個過程其實是在尋找一個函數f,當輸入某張貓的照片函數f的輸出為貓,當輸入某張狗的照片函數f的輸出為狗。再進一步具體而言整個機器學習框架可以理解為如圖2-2
圖2-2 機器學習框架描述
整個機器學習框架的步驟大體上分為三步:第一步定義一個函數池,其中有大量的備選函數f1、f2、f3…..fn;第二步對各個函數進行評價,這裏的話其實我們可以將每個函數理解為一個模型,所謂的評價的標準可以理解為對每個輸入照片各個模型所能識別出來的精確度,優秀的模型識別照片的準確度更高;第三部選出最優的函數fbest,即選出最優的模型。
2.3 理解機器學習的學習圖
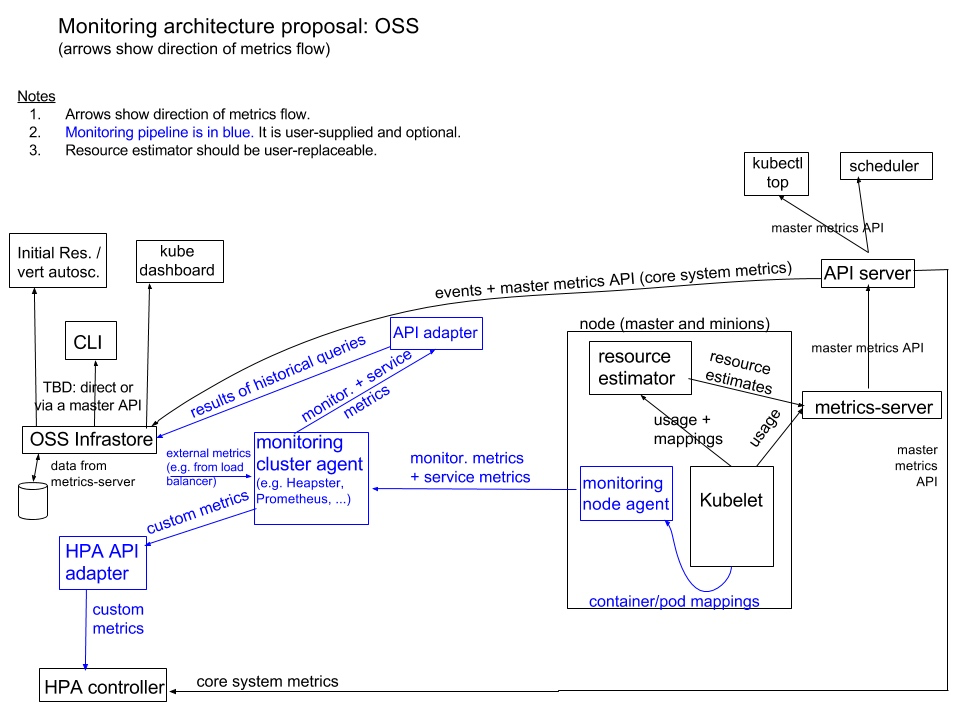
機器學習的學習圖如圖2-3,這張圖看起來很複雜,其實結構很清晰,主要分為三中顏色藍、橙、綠三種顏色,分別代表運用情景,所要解決問題的目標,以及解決問題用到的方法。
圖2-3 機器學習學習圖
首先是藍色部分,即運用情景從圖中可以看出有supervise learning、semi-supervise learning、transer learning、unsupervised learning、reinforcement learning,看到這麼多運用情景不經想問一個問題,為什麼會有這麼多運用場景的劃分?原因其實很簡單,從前面的對機器學習的介紹中我們可以發現,機器學習的過程中是需要大量的帶標籤的數據,所謂帶標籤的數據就是指給出了輸入數據的正確結果,比如說輸入一張貓的圖片,這個貓就是這張圖片的標籤,但其實當數據量巨大的時候,給每個數據標上標籤是需要消耗大量時間的,所以由輸入的數據是否帶有標籤就產生了不同的運用場景。
supervise learning 即監督學習,訓練所使用的數據均帶標籤,即告訴機器輸入數據的正確答案。semi-supervise learning 即半監督學習,訓練中的數據有一部分帶標籤,其餘數據不帶標籤交給機器自己學習。transer learning 即遷移學習 訓練數據中有一部分帶標籤,剩下的數據來自其他模型帶標籤或不帶標籤的數據,舉個例子我們做貓和狗的分類,我們有少量的已經有標籤的貓和狗的數據,還有大量的可能是帶標籤或不帶標籤的其他動物的數據,將這些數據也交由機器學習。unsupervised learning 即無監督學習,訓練中的數據均不帶標籤。reinforcement learning 即強化學習,這種學習方式與前面的學習方式均有所不同,前面的學習方式中均為告訴機器輸入數據的正確答案或者直接將數據交由機器,在強化學習中數據均不帶標籤,它是通評價告訴機器這次學習的結果,舉個例子阿爾法狗,當它完成一次棋局對戰最終取得勝利,則給與機器較高的評價,讓機器自身進行調整,雖然機器本身並不知道自己到底哪下的好,但知道這麼下贏了。
其次是橙色部分,即所要解決問題的目標,分為regression和classification以及structured learning。regression即所要解決的問題的解是個數值,比方說預測某日pm2.5的值;classification即所要解決的問題為分類問題,包括二分類即回答是或者否,比方說判斷郵件是否為垃圾郵件,多分類對輸入的數據進行多個類別分類,比方說判斷輸入的文章屬於哪個板塊是娛樂版塊還是體育板塊還是金融板塊等等;structured learning即所要解決的問題是結構化的,比方說輸入一段語言判斷語言的內容。
最後是綠色部分,這一塊的話還記的我在2.2中說過的函數池嗎,所謂的函數其實就是模型,我們可以使用不同的模型來解決不同的問題,這些模型有linear model即線性模型、non-linear model 即非線性模型,非線性模型中就包括之前提到的深度學習還有一些非線性模型。
三.寫在最後
這一部分主要是對機器學習要有個整體的大概理解,包括理解機器學習的整體框架的大致模樣,尤其是要明白框架中所說的函數其實就是模型的概念,再由就是要對為何要這樣劃分學習圖有自己的理解,至於是否要記住學習圖的內容倒是其次。
【精選推薦文章】
自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"