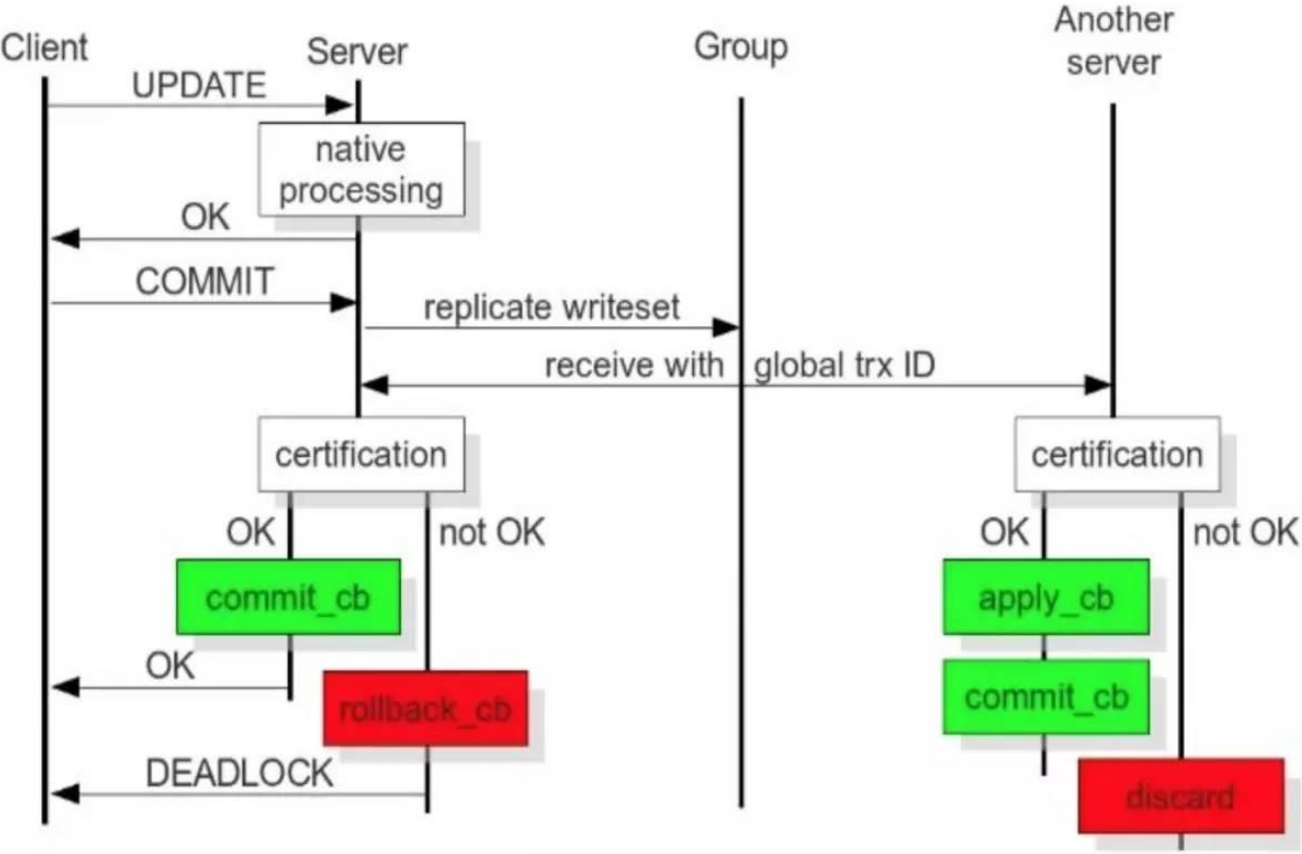
在《當我們在討論CQRS時,我們在討論些神馬》中,我們討論了當使用CQRS的過程中,需要關心的一些問題。其中與CQRS關聯最為緊密的模式莫過於Event Sourcing了,CQRS與ES的結合,為我們構造高性能、可擴展系統提供了基本思路。本文將介紹
Kanasz Robert在《Introduction to CQRS》中的示例項目Diary.CQRS。
獲取Diary.CQRS項目
該項目為Kanasz Robert為了介紹CQRS模式而寫的一個測試項目,原始項目可以通過訪問《Introduction to CQRS》來獲取,由於項目版本比較舊,沒有使用nuget管理程序包等,導致下載以後並不能正常運行,我下載了這個項目,升級到Visual Studio 2017,重新引用了StructMap框架(使用nuget),移除了Web層報錯的代碼,並上傳到博客園,可以從這裏下載:Diary.CQRS.rar
Diary.CQRS項目簡介
Diary.CQRS項目的場景為日記本管理,提供了新增、編輯、刪除、列表等功能,整個解決方案分為三個項目:
- Diary.CQRS:核心項目,完成了EventBus、CommandBus、Domain、Storage等功能,也是我們分析的重點。
- Diary.CQRS.Configuration:服務配置,通過ServiceLocator類進行依賴注入、服務查找功能。
- Diary.CQRS.Web:用戶界面,MVC項目。
這是一個很好的入門項目,功能簡單、結構清晰,概念覆蓋全面。如果CQRS是一個城堡,那麼Diary.CQRS則是打開第一重門的鑰匙,接下來讓我們一起推開這扇門吧。
Diary.CQRS.Web
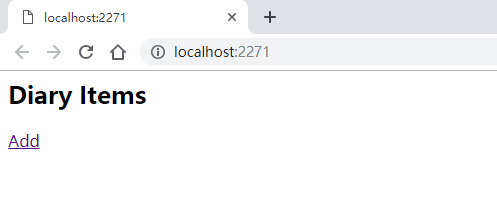
運行項目,最先看到的是一個Web頁面,如下圖:
很簡單,只有一個Add按鈕,當我們點擊以後,會進入添加的頁面:
我們填上一些內容,然後點擊Save按鈕,就會返回到列表頁,我們可以看到已添加的條目:
然後我們進行編輯操作,點擊列表中的Edit按鈕,跳轉到編輯頁面:
雖然頁面中显示的是Add,但確實是Edit頁面。我們編輯以後點擊Save按鈕,然後返回列表頁即可看到編輯后的內容。
在列表頁中,如果我們點擊Delete按鈕,則會刪除改條目。
到此為止,我們已經看到了這個項目的所有頁面,一個簡單的CURD操作。我們繼續看它的代碼(在HomeController中)。
Index:列表頁面
public ActionResult Index()
{
ViewBag.Model = ServiceLocator.ReportDatabase.GetItems();
return View();
}
通過ServiceLocator定位ReportDatabase,並從ReportDatabase中獲取所有條目。
Add:新增頁面
public ActionResult Add()
{
return View();
}
[HttpPost]
public ActionResult Add(DiaryItemDto item)
{
ServiceLocator.CommandBus.Send(new CreateItemCommand(Guid.NewGuid(), item.Title, item.Description, -1, item.From, item.To));
return RedirectToAction("Index");
}
兩個方法:
- Add()方法,處理Get請求,返回新增視圖;
- Add(DiaryItemDto item)方法,接收DiaryItemDto參數,處理Post請求,創建併發送CreateItemCommand命令,然後返回到Index頁面
Edit:編輯頁面
public ActionResult Edit(Guid id)
{
var item = ServiceLocator.ReportDatabase.GetById(id);
var model = new DiaryItemDto()
{
Description = item.Description,
From = item.From,
Id = item.Id,
Title = item.Title,
To = item.To,
Version = item.Version
};
return View(model);
}
[HttpPost]
public ActionResult Edit(DiaryItemDto item)
{
ServiceLocator.CommandBus.Send(new ChangeItemCommand(item.Id, item.Title, item.Description, item.From, item.To, item.Version));
return RedirectToAction("Index");
}
仍然是兩個方法:
- Edit(Guid id)方法,接收Guid作為參數,並從ReportDatabase中獲取數據,構建dto對象返回給頁面
- Edit(DiaryItemDto item)方法,接收DiaryItemDto對象,處理Post請求,接收到請求以後根據dto對象創建ChangeItemCommand命令,然後返回到Index頁面
Delete:刪除操作
public ActionResult Delete(Guid id)
{
var item = ServiceLocator.ReportDatabase.GetById(id);
ServiceLocator.CommandBus.Send(new DeleteItemCommand(item.Id, item.Version));
return RedirectToAction("Index");
}
對於刪除操作來說,它沒有視圖頁面,接收到請求以後,先獲取該記錄,創建併發送DeleteImteCommand命令,然後返回到Index頁面
題外話:對於改變數據狀態的操作,使用Get請求是不可取的,可能存在安全隱患
通過上面的代碼,你會發現所有的操作都是從ServiceLocator發起的,通過它我們能夠定位到CommandBus和ReportDatabase,從而進行相應的操作,我們在接下來會介紹ServiceLocator類。
Diary.CQRS.Configuration
Diary.CQRS.Configuration 項目中定義了ServiceLocator類,這個類的作用是完成IoC容器的服務註冊、服務定位功能。例如我們可以通過ServiceLocator獲取到CommandBus實例、獲取ReportDatabase實例。
服務註冊
ServiceLocator使用StructureMap作為依賴注入框架,提供了服務註冊、服務導航的功能。ServiceLocator類通過靜態構造函數完成對服務註冊和服務實例化工作:
static ServiceLocator()
{
if (!_isInitialized)
{
lock (_lockThis)
{
ContainerBootstrapper.BootstrapStructureMap();
_commandBus = ObjectFactory.GetInstance<ICommandBus>();
_reportDatabase = ObjectFactory.GetInstance<IReportDatabase>();
_isInitialized = true;
}
}
}
首先調用ContainerBootstrapper.BootstrapStructureMap()方法,這個方法裡面包含了對將服務添加到容器的代碼;然後使用容器創建CommandBus和ReportDatabase的實例。
- CommandBus:命令總線,對應Command操作,用來發送命令,程序中需要定義相應的命令處理器,從而完成具體的操作。
- ReportDatabase:報表數據庫,對應Query操作,用來獲取數據。
ServiceLocator的重要之處在於對外暴露了兩個至關重要的實例,分別處理CQRS中的Command和Query。
為什麼沒有Event相關操作呢?到目前為止我們還沒有涉及到,因為對於UI層來說,用戶的意圖都是通過Command表示的,而數據的狀態變化才會觸發Event。
Diary.CQRS
在ServiceLocator中定義了獲取CommandBus和ReportDatabase的方法,我們順着這兩個對象繼續分析。
CommandBus
在基於消息的系統設計中,我們常會看到總線的身影,Command也是一種消息,所以使用總線是再合適不過的了。CommandBus就是我們在Diary.CQRS項目中用到的一種消息總線。
在Diary.CQRS中,它被定義在Messaging目錄,在這個目錄下面,還有與Event相關的EventBus,我們稍後再進行介紹。
CommandBus實現ICommandBus接口,ICommandBus接口的定義如下:
public interface ICommandBus
{
void Send<T>(T command) where T : Command;
}
它只包含了Send方法,用來將命令發送到對應的處理程序。
CommandBus是ICommand的實現,具體代碼如下:
public class CommandBus:ICommandBus
{
private readonly ICommandHandlerFactory _commandHandlerFactory;
public CommandBus(ICommandHandlerFactory commandHandlerFactory)
{
_commandHandlerFactory = commandHandlerFactory;
}
public void Send<T>(T command) where T : Command
{
var handler = _commandHandlerFactory.GetHandler<T>();
if (handler!=null)
{
handler.Execute(command);
}
else
{
throw new Exception();
}
}
}
在CommandBus中,顯式依賴ICommandHandlerFactory類,通過構造函數進行注入。那麼 _commandHandlerFactory 的作用是什麼呢?我們在Send方法中可以看到,通過 _commandHandlerFactory 可以獲取到與Command對應的CommandHandler(命令處理程序),在程序的設計上,每一個Command都會有一個對應的CommandHandler,而手工判斷類型、實例化處理程序顯然不符合使用習慣,此處採用工廠模式來獲取命令處理程序。
當獲取到與Command對應的CommandHandler后,調用handler的Execute方法,執行該命令。
截止目前為止,我們又接觸了三個概念:CommandHandlerFactory、CommandHandler、Command:
- CommandHandlerFactory:命令處理程序工廠,通過GetHandler方法獲取到與命令對應的處理程序
- CommandHandler:命令處理程序,用於執行對應的命令
- Command:命令,描述用戶的意圖、並包含與意圖相關的數據
CommandHandlerFactory
使用簡單工廠模式,用來獲取與命令對應的處理程序。它的代碼在Utils文件夾中,它的作用是提供一種獲取Handler的方式,所以它只能作為工具存在。
接口定義如下:
public interface ICommandHandlerFactory
{
ICommandHandler<T> GetHandler<T>() where T : Command;
}
只有GetHandler一個方法,它的實現是 StructureMapCommandHandlerFactory,即通過StructureMap作為依賴注入框架來實現的,代碼也比較簡單,這裏不再貼出來了。
Command和CommandHandler
命令是代表用戶的意圖、並包含與意圖相關的數據,比如用戶想要添加一條數據,這便是一個意圖,於是就有了CreateItemCommand,用戶要在界面上填寫添加操作必須的數據,於是就有了命令的屬性。
關於命令的定義如下:
public interface ICommand
{
Guid Id { get; }
}
public class Command : ICommand
{
public Guid Id { get; private set; }
public int Version { get; set; }
public Command(Guid id, int version)
{
Id = id;
Version = version;
}
}
命令處理程序,它的作用是處理與它相對應的命令,處理CQRS的核心,接口定義如下:
public interface ICommandHandler<TCommand> where TCommand : Command
{
void Execute(TCommand command);
}
它接收command作為參數,執行該命令的處理邏輯。每一個命令都有一個與之對應的處理程序。
我們再重新梳理一下流程,首先用戶要新增一個數據,點擊保存按鈕后,生成CreateItemCommand命令,隨後這個命令被發送到CommandBus中,CommandBus通過CommandHandlerFactory找到該Command的處理程序,此時在CommandBus的Send方法中,我們有一個Command和CommandHandler,然後調用CommandHandler的Execute方法,即完成了該方法的處理。至此,Command的處理流程完結。
CreateItemCommand和CreateItemCommandHandler
我們來看一下CreateItemCommand的代碼:
public class CreateItemCommand : Command
{
public string Title { get; internal set; }
public string Description { get; internal set; }
public DateTime From { get; internal set; }
public DateTime To { get; internal set; }
public CreateItemCommand(Guid aggregateId, string title,
string description, int version, DateTime from, DateTime to)
: base(aggregateId, version)
{
Title = title;
Description = description;
From = from;
To = to;
}
}
它繼承自Command基類,繼承后即擁有了Id和Version屬性,然後又定義了幾個其它的屬性。它只包含數據,與該命令對應的處理程序叫做CreateItemCommandHandler,代碼如下:
public class CreateItemCommandHandler : ICommandHandler<CreateItemCommand>
{
private IRepository<DiaryItem> _repository;
public CreateItemCommandHandler(IRepository<DiaryItem> repository)
{
_repository = repository;
}
public void Execute(CreateItemCommand command)
{
if (command == null)
{
throw new Exception();
}
if (_repository == null)
{
throw new Exception();
}
var aggregate = new DiaryItem(command.Id, command.Title, command.Description, command.From, command.To);
aggregate.Version = -1;
_repository.Save(aggregate, aggregate.Version);
}
}
這才是我們要分析的核心,在Handler中,我們看到了Repository,看到了DiaryItem聚合:
- IRepository :倉儲類,代表數據的儲存方式,通過倉儲能夠進行數據操作
- DiaryItem:領域對象,聚合根,所有數據狀態的變更只能通過聚合根來修改
在上面的代碼中,由於是新增,所以聚合的版本為-1,然後調用倉儲的Save方法進行保存。我們繼續往下扒,看看倉儲和聚合的實現。
Repository
對於Repository的定義,仍然先看一下接口中的定義,代碼如下:
public interface IRepository<T> where T : AggregateRoot, new()
{
void Save(AggregateRoot aggregate, int expectedVersion);
T GetById(Guid id);
}
在倉儲中只有兩個方法:
- Save(AggregateRoot aggregate, int expectedVersion):保存期望版本的聚合根
- GetById(Guid id):根據聚合根Id獲取聚合根
關於IRepository的實現,代碼在Repository.cs中,我們拆開來進行介紹:
private readonly IEventStorage _eventStorage;
private static object _lock = new object();
public Repository(IEventStorage eventStorage)
{
_eventStorage = eventStorage;
}
首先是它的構造函數,強依賴IEventStorage,通過構造函數注入。EventStorage是事件的儲存倉庫,有個更為熟知的名字EventStore,我們稍後進行介紹。
public T GetById(Guid id)
{
IEnumerable<Event> events;
var memento = _eventStorage.GetMemento<BaseMemento>(id);
if (memento != null)
{
events = _eventStorage.GetEvents(id).Where(e => e.Version >= memento.Version);
}
else
{
events = _eventStorage.GetEvents(id);
}
var obj = new T();
if (memento != null)
{
((IOriginator)obj).SetMemento(memento);
}
obj.LoadsFromHistory(events);
return obj;
}
GetById(Guid id)方法通過Id獲取一個聚合對象,獲取一個聚合對象有以下幾個步驟:
通過這幾個步驟以後,我們得到了一個最新狀態的聚合根對象。
public void Save(AggregateRoot aggregate, int expectedVersion)
{
if (aggregate.GetUncommittedChanges().Any())
{
lock (_lock)
{
var item = new T();
if (expectedVersion != -1)
{
item = GetById(aggregate.Id);
if (item.Version != expectedVersion)
{
throw new Exception();
}
}
_eventStorage.Save(aggregate);
}
}
}
Save方法,用來保存一個聚合根對象。在這個方法中,參數expectedVersion表示期望的版本,這裏約定-1為新增的聚合根,當聚合根為新增的時候,會直接調用EventStorage中的Save方法。
關於expectedVersion參數,我們可以理解為對併發的控制,只有當expectedVersion與GetById獲取到的聚合根對象的版本相同時才能進行保存操作。
在介紹Repository類的時候,我們接觸了兩個新的概念:EventStorage和AggregateRoot,接下來我們分別進行介紹。
AggregateRoot
AggregateRoot是聚合根,他表示一組強關聯的領域對象,所有對象的狀態變更只能通過聚合根來完成,這樣可以保證數據的一致性,以及減少併發衝突。應用到EventSourcing模式中,聚合根的好處也是很明顯的,我們所有對數據狀態的變更都通過聚合根完成,而每次變更,聚合根都會生成相應的事件,在進行事件回放的時候,又通過聚合根來完成歷史事件的加載。由此我們可以看到,聚合根對象應該具備生成事件、重放事件的能力。
我們來看看聚合根基類的定義,在Domain文件夾中:
public abstract class AggregateRoot : IEventProvider{
// ......
}
首先這是一個抽象類,實現了IEventProvider接口,該接口的定義如下:
public interface IEventProvider
{
void LoadsFromHistory(IEnumerable<Event> history);
IEnumerable<Event> GetUncommittedChanges();
}
它定義了兩個方法,我們分別進行說明:
- LoadsFromHistory()方法:加載歷史事件,還原聚合根的最新狀態,我們在Repository中已經用過這個方法。
- GetUncommittedChanges()方法:獲取未提交的事件。一個命令可能造成聚合根發生多次更改,每次更改都會產生一個事件,這些事件被暫時的保存在聚合根對象中,通過該方法可以獲取到未提交的事件列表。
為了實現這個接口,聚合根中定義了 List<Event> _changes對象,用來臨時存儲所有未提交的事件,該對象在構造函數中進行初始化。
AggregateRoot中對於該事件的實現如下:
public void LoadsFromHistory(IEnumerable<Event> history)
{
foreach (var e in history)
{
ApplyChange(e, false);
}
Version = history.Last().Version;
EventVersion = Version;
}
public IEnumerable<Event> GetUncommittedChanges()
{
return _changes;
}
LoadsFromHistory方法遍歷歷史事件,並調用ApplyChange方法更新聚合根的狀態,在完成更新後設置版本號為最後一個事件的版本。GetUncommittedChanges方法比較簡單,返回對象的_changes事件列表。
接下來我們看看ApplyChange方法,該方法有兩個實現,代碼如下:
protected void ApplyChange(Event @event)
{
ApplyChange(@event, true);
}
protected void ApplyChange(Event @event, bool isNew)
{
dynamic d = this;
d.Handle(Converter.ChangeTo(@event, @event.GetType()));
if (isNew)
{
_changes.Add(@event);
}
}
這兩個方法定義為protected,只能被子類訪問。我們可以理解為,ApplyChange(Event @event)方法為簡化操作,對第二個參數進行了默認為true的操作,然後調用ApplyChange(Event @event, bool isNew)方法。
在ApplyChange(Event @event, bool isNew)方法中,調用了聚合根的Handle方法,用來處理事件。如果isNew參數為true,則將事件添加到change列表中,如果為false,則認為是在進行事件回放,所以不進行事件的添加。
需要注意的是,聚合根的Handle方法,與EventHandler不同,當Event產生以後,首先由它對應的聚合根進行處理,因此聚合根要具備處理該事件的能力,如何具備呢?聚合根要實現IHandle接口,該接口的定義如下:
public interface IHandle<TEvent> where TEvent:Event
{
void Handle(TEvent e);
}
這裏可以看出,IHandle接口是泛型的,它只對一個具體的Event類型生效,在代碼上的體現如下:
public class DiaryItem : AggregateRoot,
IHandle<ItemCreatedEvent>,
IHandle<ItemRenamedEvent>,
IHandle<ItemFromChangedEvent>,
IHandle<ItemToChangedEvent>,
IHandle<ItemDescriptionChangedEvent>,
IOriginator
{
//......
}
最後,聚合根還定義了清除所有事件的方法,代碼如下:
public void MarkChangesAsCommitted()
{
_changes.Clear();
}
MarkChangesAsCommitted()方法用來清空事件列表。
Event
終於到我們今天的另外一個核心內容了,Event是ES中的一等公民,所有的狀態變更最終都以Event的形式進行存儲,當我們要查看聚合根最新狀態的時候,可以通過事件回放來獲取。我們來看看Event的定義:
public interface IEvent
{
Guid Id { get; }
}
IEvent接口定義了一個事件必須擁有唯一的Id進行標識。然後Event實現了IEvent接口:
public class Event:IEvent
{
public int Version;
public Guid AggregateId { get; set; }
public Guid Id { get; private set; }
}
可以看到,除了Id屬性外,還添加了兩個字段Version和AggregateId。AggregateId表示該事件關聯的聚合根Id,通過該Id可以獲取到唯一的聚合根對象;Version表示事件發生時該事件的版本,每次產生新的事件,Version都會進行累加。
從而可以知道,在EventStorage中,聚合根Id對應的所有Event中的Version是順序累加的,按照Version進行排序可以得到事件發生的先後順序。
EventStorage
顧名思義,EventStorage是用來存儲Event的地方。在Diary.CQRS中,EventStorage的定義如下:
public interface IEventStorage
{
IEnumerable<Event> GetEvents(Guid aggregateId);
void Save(AggregateRoot aggregate);
T GetMemento<T>(Guid aggregateId) where T : BaseMemento;
void SaveMemento(BaseMemento memento);
}
- GetEvents(Guid aggregateId):根據聚合根Id獲取該聚合根的所有事件
- Save(AggregateRoot aggregate):保存方法,入參為聚合根對象,在實現上則是獲取聚合根中所有未提交的事件,隨後對這些事件進行處理
- GetMemento():獲取快照
- SaveMemento():存儲快照
Diary.CQRS中使用InMemory的方式實現了EventStorage,屬性和構造函數如下:
private List<Event> _events;
private List<BaseMemento> _mementoes;
private readonly IEventBus _eventBus;
public InMemoryEventStorage(IEventBus eventBus)
{
_events = new List<Event>();
_mementoes = new List<BaseMemento>();
_eventBus = eventBus;
}
- _events:事件列表,內存中存儲事件的位置,所有事件最終都會存儲在該列表中
- _mementoes:快照列表,用於存儲聚合根的某個事件版本的狀態
- _eventBus:事件總線,用於發布任務
當Event生成后,它並沒有馬上存入EventStorage,而是在Repository显示調用Save方法時,倉儲將存儲權交給了EventStorage,EventStorage是事件倉庫,事件倉儲在存儲時進行了如下操作:
- 獲取聚合根中所有未提交的Event,同時獲取到聚合根當前的版本號
- 遍歷未提交Event列表,根據聚合根版本號自動為Event生成版本號,保持自增長的特性;
- 生成聚合根快照。示例中每3個版本生成一次,並保持到事件倉儲中。
- 將任務添加到事件倉庫中。
- 再次遍歷未提交Event列表,此時將進行任務發布,調用事件總線的Publish方法進行發布。
Save方法的代碼如下:
public void Save(AggregateRoot aggregate)
{
var uncommittedChanges = aggregate.GetUncommittedChanges();
var version = aggregate.Version;
foreach (var @event in uncommittedChanges)
{
version++;
if (version > 2)
{
if (version % 3 == 0)
{
var originator = (IOriginator)aggregate;
var memento = originator.GetMemento();
memento.Version = version;
SaveMemento(memento);
}
}
@event.Version = version;
_events.Add(@event);
}
foreach (var @event in uncommittedChanges)
{
var desEvent = Converter.ChangeTo(@event, @event.GetType());
_eventBus.Publish(desEvent);
}
}
至此Event的處理流程就算完結了。此時所有的操作都是在主庫完成的,當事件被發布以後,訂閱了該事件的所有Handler都將會被觸發。
在Diary.CQRS項目中,EventHandler都被用來處理ReportDatabase了。
ReportDatabase
當你使用ES模式時,都存在一個嚴重問題,那就是數據查詢的問題。當用戶進行數據檢索是,必然會使用各種查詢條件,然而無論那種事件倉庫都很難滿足複雜查詢。為了解決此問題,ReportDatabase就顯得格外重要。
ReportDatabase的作用被定義為獲取數據、應對數據查詢、生成報表等,它的結構與主庫不同,可以根據不同的業務場景進行定義。
ReportDatabase的數據不是通過業務邏輯進行更新的,它通過訂閱Event進行更新。在本示例中ReportDatabase實現的很簡單,接口定義如下:
public interface IReportDatabase
{
DiaryItemDto GetById(Guid id);
void Add(DiaryItemDto item);
void Delete(Guid id);
List<DiaryItemDto> GetItems();
}
實現上,通過內存中維護一個列表,每次接收到事件以後,都對相應數據進行更新,此處不在貼出。
EventHandler、EventHandlerFactory和EventBus
在上文中已經介紹過Event,而針對Event的處理,實現邏輯上與Command非常相似,唯一的區別是,命令只可以有一個對應的處理程序,而事件則可以有多個處理程序。所以在EventHandlerFactory中獲取處理程序的方法返回了EventHandler列表,代碼如下:
public IEnumerable<IEventHandler<T>> GetHandlers<T>() where T : Event
{
var handlers = GetHandlerType<T>();
var lstHandlers = handlers.Select(handler => (IEventHandler<T>)ObjectFactory.GetInstance(handler)).ToList();
return lstHandlers;
}
在EventBus中,如果一個事件沒有處理程序也不會引發錯誤,如果有一個或多個處理程序,則會以此調用他們的Handle方法,代碼如下:
public void Publish<T>(T @event) where T : Event
{
var handlers = _eventHandlerFactory.GetHandlers<T>();
foreach (var eventHandler in handlers)
{
eventHandler.Handle(@event);
}
}
總結
Diary.CQRS是一個典型的CQRS+ES演示項目,通過對該項目的分析,我們能了解到Command、AggregateRoot、Event、EventStorage、ReportDatabase的基礎知識,了解他們相互關係,尤其是如何進行事件存儲、如何進行事件回放的內容。
另外,我們發現在使用CQRS+ES的過程中,項目的複雜度增加了很多,我們不可避免的要使用EventStore、Messaging等架構,從而影響那些不了解CQRS的團隊成員的加入,因此在應用到實際項目的時候,要適可而止,慎重選擇,避免過度設計。
由於這是一個示例,項目代碼中存在很多不夠嚴謹的地方,大家在學習的過程中應進行甄別。
由於本人的知識有限,如果內容中存在不準確或錯誤的地方,還請不吝賜教!
【精選推薦文章】
自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"