上一篇關於 WSGI 的硬核長文,不知道有多少同學,能夠從頭看到尾的,不管你們有沒有看得很過癮,反正我是寫得很爽,總有一種將一樣知識吃透了的錯覺。
今天我又給自己挖坑了,打算將 rpc 遠程調用的知識,好好地梳理一下,花了周末整整两天的時間。
什麼是RPC呢?
百度百科給出的解釋是這樣的:“RPC(Remote Procedure Call Protocol)——遠程過程調用協議,它是一種通過網絡從遠程計算機程序上請求服務,而不需要了解底層網絡技術的協議”。這個概念聽起來還是比較抽象,沒關係,繼續往後看,後面概念性的東西,我會講得足夠清楚,讓你完全掌握 RPC 的基礎內容。在後面的篇章中還會結合其在 OpenStack 中實際應用,一步一步揭開 rpc 的神秘面紗。
有的讀者,可能會問,為啥我舉的例子老是 OpenStack 里的東西呢?
因為每個人的業務中接觸的框架都不一樣(我主要接觸的就是 OpenStack 框架),我無法為每個人去定製寫一篇文章,但其技術原理都是一樣的。即使如此,我也會儘力將文章寫得通用,不會因為你沒接觸過 OpenStack 而成為你理解 rpc 的瓶頸。
01. 既 REST,何 RPC ?
在 OpenStack 里的進程間通信方式主要有兩種,一種是基於HTTP協議的RESTFul API方式,另一種則是RPC調用。
那麼這兩種方式在應用場景上有何區別呢?
有使用經驗的人,就會知道:
- 前者(RESTful)主要用於各組件之間的通信(如nova與glance的通信),或者說用於組件對外提供調用接口
- 而後者(RPC)則用於同一組件中各個不同模塊之間的通信(如nova組件中nova-compute與nova-scheduler的通信)。
關於OpenStack中基於RESTful API的通信方式主要是應用了WSGI,這個知識點,我在前一篇文章中,有深入地講解過,你可以點擊查看。
對於不熟悉 OpenStack 的人,也別擔心聽不懂,這樣吧,我給你提兩個問題:
- RPC 和 REST 區別是什麼?
- 為什麼要採用RPC呢?
第一個問題:RPC 和 REST 區別是什麼?
你一定會覺得這個問題很奇怪,是的,包括我,但是你在網絡上一搜,會發現類似對比的文章比比皆是,我在想可能很多初學者由於基礎不牢固,才會將不相干的二者拿出來對比吧。既然是這樣,那為了讓你更加了解陌生的RPC,就從你熟悉得不能再熟悉的 REST 入手吧。
01、所屬類別不同
REST,是Representational State Transfer 的簡寫,中文描述表述性狀態傳遞(是指某個瞬間狀態的資源數據的快照,包括資源數據的內容、表述格式(XML、JSON)等信息。)
REST 是一種軟件架構風格。 這種風格的典型應用,就是HTTP。其因為簡單、擴展性強的特點而廣受開發者的青睞。
而RPC 呢,是 Remote Procedure Call Protocol 的簡寫,中文描述是遠程過程調用,它可以實現客戶端像調用本地服務(方法)一樣調用服務器的服務(方法)。
RPC 是一種基於 TCP 的通信協議,按理說它和REST不是一個層面上的東西,不應該放在一起討論,但是誰讓REST這麼流行呢,它是目前最流行的一套互聯網應用程序的API設計標準,某種意義下,我們說 REST 可以其實就是指代 HTTP 協議。
02、使用方式不同
從使用上來看,HTTP 接口只關注服務提供方,對於客戶端怎麼調用並不關心。接口只要保證有客戶端調用時,返回對應的數據就行了。而RPC則要求客戶端接口保持和服務端的一致。
- REST 是服務端把方法寫好,客戶端並不知道具體方法。客戶端只想獲取資源,所以發起HTTP請求,而服務端接收到請求后根據URI經過一系列的路由才定位到方法上面去
- PRC是服務端提供好方法給客戶端調用,客戶端需要知道服務端的具體類,具體方法,然後像調用本地方法一樣直接調用它。
03、面向對象不同
從設計上來看,RPC,所謂的遠程過程調用 ,是面向方法的 ,REST:所謂的 Representational state transfer ,是面向資源的,除此之外,還有一種叫做 SOA,所謂的面向服務的架構,它是面向消息的,這個接觸不多,就不多說了。
04、序列化協議不同
接口調用通常包含兩個部分,序列化和通信協議。
通信協議,上面已經提及了,REST 是 基於 HTTP 協議,而 RPC 可以基於 TCP/UDP,也可以基於 HTTP 協議進行傳輸的。
常見的序列化協議,有:json、xml、hession、protobuf、thrift、text、bytes等,REST 通常使用的是 JSON或者XML,而 RPC 使用的是 JSON-RPC,或者 XML-RPC。
通過以上幾點,我們知道了 REST 和 RPC 之間有很明顯的差異。
第二個問題:為什麼要採用RPC呢?
那到底為何要使用 RPC,單純的依靠RESTful API不可以嗎?為什麼要搞這麼多複雜的協議,渣渣表示真的學不過來了。
關於這一點,以下幾點僅是我的個人猜想,僅供交流哈:
- RPC 和 REST 兩者的定位不同,REST 面向資源,更注重接口的規範,因為要保證通用性更強,所以對外最好通過 REST。而 RPC 面向方法,主要用於函數方法的調用,可以適合更複雜通信需求的場景。
- RESTful API客戶端與服務端之間採用的是同步機制,當發送HTTP請求時,客戶端需要等待服務端的響應。當然對於這一點是可以通過一些技術來實現異步的機制的。
- 採用RESTful API,客戶端與服務端之間雖然可以獨立開發,但還是存在耦合。比如,客戶端在發送請求的時,必須知道服務器的地址,且必須保證服務器正常工作。而 rpc + ralbbimq中間件可以實現低耦合的分佈式集群架構。
說了這麼多,我們該如何選擇這兩者呢?我總結了如下兩點,供你參考:
- REST 接口更加規範,通用適配性要求高,建議對外的接口都統一成 REST(也有例外,比如我接觸過 zabbix,其 API 就是基於 JSON-RPC 2.0協議的)。而組件內部的各個模塊,可以選擇 RPC,一個是不用耗費太多精力去開發和維護多套的HTTP接口,一個RPC的調用性能更高(見下條)
- 從性能角度看,由於HTTP本身提供了豐富的狀態功能與擴展功能,但也正由於HTTP提供的功能過多,導致在網絡傳輸時,需要攜帶的信息更多,從性能角度上講,較為低效。而RPC服務網絡傳輸上僅傳輸與業務內容相關的數據,傳輸數據更小,性能更高。
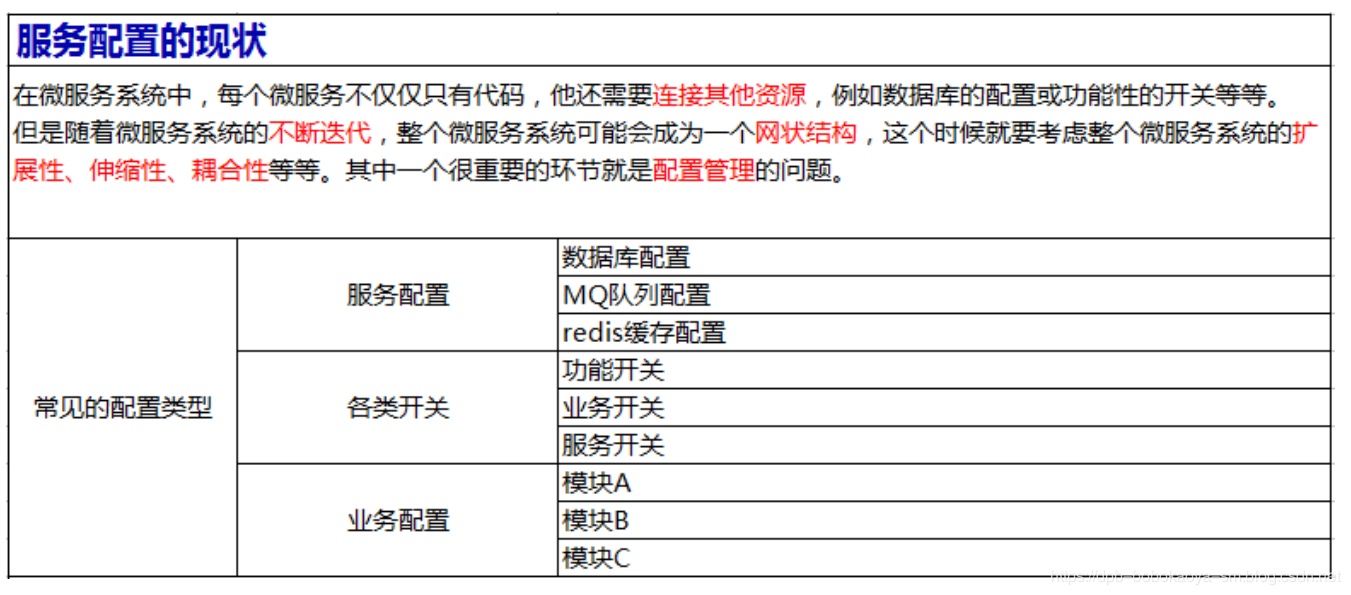
02. 實現遠程調用的三種方式
“遠程調用”意思就是:被調用方法的具體實現不在程序運行本地,而是在別的某個地方(分佈到各個服務器),調用者只想要函數運算的結果,卻不需要實現函數的具體細節。
01、基於 xml-rpc
Python實現 rpc,可以使用標準庫里的 SimpleXMLRPCServer,它是基於XML-RPC 協議的。
有了這個模塊,開啟一個 rpc server,就變得相當簡單了。執行以下代碼:
import SimpleXMLRPCServer
class calculate:
def add(self, x, y):
return x + y
def multiply(self, x, y):
return x * y
def subtract(self, x, y):
return abs(x-y)
def divide(self, x, y):
return x/y
obj = calculate()
server = SimpleXMLRPCServer.SimpleXMLRPCServer(("localhost", 8088))
# 將實例註冊給rpc server
server.register_instance(obj)
print "Listening on port 8088"
server.serve_forever()
有了 rpc server,接下來就是 rpc client,由於我們上面使用的是 XML-RPC,所以 rpc clinet 需要使用xmlrpclib 這個庫。
import xmlrpclib
server = xmlrpclib.ServerProxy("http://localhost:8088")
然後,我們通過 server_proxy 對象就可以遠程調用之前的rpc server的函數了。
>> server.add(2, 3)
5
>>> server.multiply(2, 3)
6
>>> server.subtract(2, 3)
1
>>> server.divide(2, 3)
0
SimpleXMLRPCServer是一個單線程的服務器。這意味着,如果幾個客戶端同時發出多個請求,其它的請求就必須等待第一個請求完成以後才能繼續。
若非要使用 SimpleXMLRPCServer 實現多線程併發,其實也不難。只要將代碼改成如下即可。
from SimpleXMLRPCServer import SimpleXMLRPCServer
from SocketServer import ThreadingMixIn
class ThreadXMLRPCServer(ThreadingMixIn, SimpleXMLRPCServer):pass
class MyObject:
def hello(self):
return "hello xmlprc"
obj = MyObject()
server = ThreadXMLRPCServer(("localhost", 8088), allow_none=True)
server.register_instance(obj)
print "Listening on port 8088"
server.serve_forever()
02、基於json-rpc
SimpleXMLRPCServer 是基於 xml-rpc 實現的遠程調用,上面我們也提到 除了 xml-rpc 之外,還有 json-rpc 協議。
那 python 如何實現基於 json-rpc 協議呢?
答案是很多,很多web框架其自身都自己實現了json-rpc,但我們要獨立這些框架之外,要尋求一種較為乾淨的解決方案,我查找到的選擇有兩種
第一種是 jsonrpclib
pip install jsonrpclib -i https://pypi.douban.com/simple
第二種是 python-jsonrpc
pip install python-jsonrpc -i https://pypi.douban.com/simple
先來看第一種 jsonrpclib
它與 Python 標準庫的 SimpleXMLRPCServer 很類似(因為它的類名就叫做 SimpleJSONRPCServer ,不明真相的人真以為它們是親兄弟)。或許可以說,jsonrpclib 就是仿照 SimpleXMLRPCServer 標準庫來進行編寫的。
它的導入與 SimpleXMLRPCServer 略有不同,因為SimpleJSONRPCServer分佈在jsonrpclib庫中。
服務端
from jsonrpclib.SimpleJSONRPCServer import SimpleJSONRPCServer
server = SimpleJSONRPCServer(('localhost', 8080))
server.register_function(lambda x,y: x+y, 'add')
server.serve_forever()
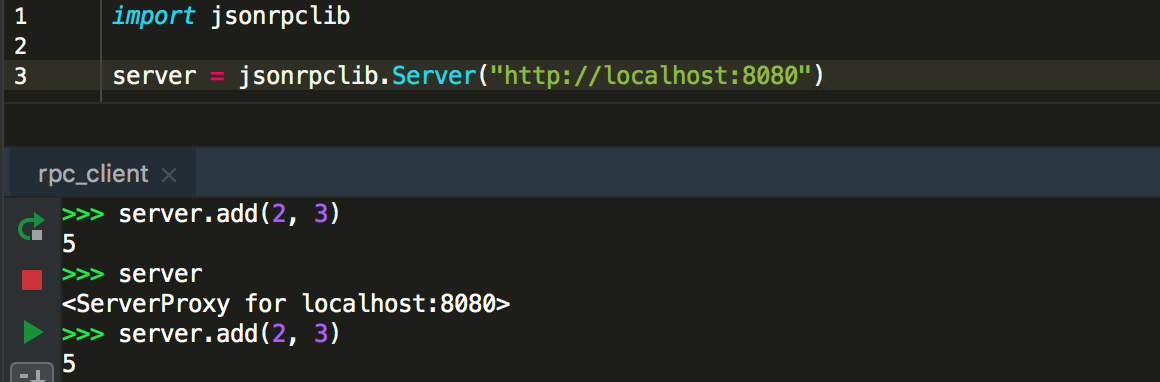
客戶端
import jsonrpclib
server = jsonrpclib.Server("http://localhost:8080")
再來看第二種python-jsonrpc,寫起來貌似有些複雜。
服務端
import pyjsonrpc
class RequestHandler(pyjsonrpc.HttpRequestHandler):
@pyjsonrpc.rpcmethod
def add(self, a, b):
"""Test method"""
return a + b
http_server = pyjsonrpc.ThreadingHttpServer(
server_address=('localhost', 8080),
RequestHandlerClass=RequestHandler
)
print "Starting HTTP server ..."
print "URL: http://localhost:8080"
http_server.serve_forever()
客戶端
import pyjsonrpc
http_client = pyjsonrpc.HttpClient(
url="http://localhost:8080/jsonrpc"
)
還記得上面我提到過的 zabbix API,因為我有接觸過,所以也拎出來講講。zabbix API 也是基於 json-rpc 2.0協議實現的。
因為內容較多,這裏只帶大家打個,zabbix 是如何調用的:直接指明要調用 zabbix server 的哪個方法,要傳給這個方法的參數有哪些。
03、基於 zerorpc
以上介紹的兩種rpc遠程調用方式,如果你足夠細心,可以發現他們都是http+rpc 兩種協議結合實現的。
接下來,我們要介紹的這種(zerorpc),就不再使用走 http 了。
zerorpc 這個第三方庫,它是基於TCP協議、 ZeroMQ 和 MessagePack的,速度相對快,響應時間短,併發高。zerorpc 和 pyjsonrpc 一樣,需要額外安裝,雖然SimpleXMLRPCServer不需要額外安裝,但是SimpleXMLRPCServer性能相對差一些。
pip install zerorpc -i https://pypi.douban.com/simple
服務端代碼
import zerorpc
class caculate(object):
def hello(self, name):
return 'hello, {}'.format(name)
def add(self, x, y):
return x + y
def multiply(self, x, y):
return x * y
def subtract(self, x, y):
return abs(x-y)
def divide(self, x, y):
return x/y
s = zerorpc.Server(caculate())
s.bind("tcp://0.0.0.0:4242")
s.run()
客戶端
import zerorpc
c = zerorpc.Client()
c.connect("tcp://127.0.0.1:4242")
客戶端除了可以使用zerorpc框架實現代碼調用之外,它還支持使用“命令行”的方式調用。
客戶端可以使用命令行,那服務端是不是也可以呢?
是的,通過 Github 上的文檔幾個 demo 可以體驗到這個第三方庫做真的是優秀。
比如我們可以用下面這個命令,創建一個rpc server,後面這個 time Python 標準庫中的 time 模塊,zerorpc 會將 time 註冊綁定以供client調用。
zerorpc --server --bind tcp://127.0.0.1:1234 time
在客戶端,就可以用這條命令來遠程調用這個 time 函數。
zerorpc --client --connect tcp://127.0.0.1:1234 strftime %Y/%m/%d
03. 往rpc中引入消息中間件
經過了上面的學習,我們已經學會了如何使用多種方式實現rpc遠程調用。
通過對比,zerorpc 可以說是脫穎而出,一支獨秀。
但為何在 OpenStack 中,rpc client 不直接 rpc 調用 rpc server ,而是先把 rpc 調用請求發給 RabbitMQ ,再由訂閱者(rpc server)來取消息,最終實現遠程調用呢?
為此,我也做了一番思考:
OpenStack 組件繁多,在一個較大的集群內部每個組件內部通過rpc通信頻繁,如果都採用rpc直連調用的方式,連接數會非常地多,開銷大,若有些 server 是單線程的模式,超時會非常的嚴重。
OpenStack 是複雜的分佈式集群架構,會有多個 rpc server 同時工作,假設有 server01,server02,server03 三個server,當 rpc client 要發出rpc請求時,發給哪個好呢?這是問題一。
你可能會說輪循或者隨機,這樣對大家都公平。這樣的話還會引出另一個問題,倘若請求剛好發到server01,而server01剛好不湊巧,可能由於機器或者其他因為導致服務沒在工作,那這個rpc消息可就直接失敗了呀。要知道做為一個集群,高可用是基本要求,如果出現剛剛那樣的情況其實是很尷尬的。這是問題二。
集群有可能根據實際需要擴充節點數量,如果使用直接調用,耦合度太高,不利於部署和生產。這是問題三。
引入消息中間件,可以很好的解決這些問題。
解決問題一:消息只有一份,接收者由AMQP的負載算法決定,默認為在所有Receiver中均勻發送(round robin)。
解決問題二:有了消息中間件做緩衝站,client 可以任性隨意的發,server 都掛掉了?沒有關係,等 server 正常工作后,自己來消息中間件取就行了。
解決問題三:無論有多少節點,它們只要認識消息中間件這一个中介就足夠了。
04. 消息隊列你應該知道什麼?
由於後面,我將實例講解 OpenStack 中如何將 rpc 和 mq broker 結合使用。
而在此之前,你必須對消息隊列的一些基本知識有個概念。
首先,RPC只是定義了一個通信接口,其底層的實現可以各不相同,可以是 socket,也可以是今天要講的 AMQP。
AMQP(Advanced Message Queuing Protocol)是一種基於隊列的可靠消息服務協議,作為一種通信協議,AMQP同樣存在多個實現,如Apache Qpid,RabbitMQ等。
以下是 AMQP 中的幾個必知的概念:
-
Publisher:消息發布者
-
Receiver:消息接收者,在RabbitMQ中叫訂閱者:Subscriber。
-
Queue:用來保存消息的存儲空間,消息沒有被receiver前,保存在隊列中。
-
Exchange:用來接收Publisher發出的消息,根據Routing key 轉發消息到對應的Message Queue中,至於轉到哪個隊列里,這個路由算法又由exchange type決定的。
exchange type:主要四種描述exchange的類型。
direct:消息路由到滿足此條件的隊列中(queue,可以有多個): routing key = binding key
topic:消息路由到滿足此條件的隊列中(queue,可以有多個):routing key 匹配 binding pattern. binding pattern是類似正則表達式的字符串,可以滿足複雜的路由條件。
fanout:消息路由到多有綁定到該exchange的隊列中。
-
binding :binding是用來描述exchange和queue之間的關係的概念,一個exchang可以綁定多個隊列,這些關係由binding建立。前面說的binding key /binding pattern也是在binding中給出。
在網上找了個圖,可以很清晰地描述幾個名詞的關係。
關於AMQP,有幾下幾點值得注意:
- 每個receiver/subscriber 在接收消息前都需要創建binding。
- 一個隊列可以有多個receiver,隊列里的一個消息只能發給一個receiver。
- 一個消息可以被發送到一個隊列中,也可以被發送到多個多列中。多隊列情況下,一個消息可以被多個receiver收到並處理。Openstack RPC中這兩種情況都會用到。
05. OpenStack中如何使用RPC?
前面鋪墊了那麼久,終於到了講真實應用的場景。在生產中RPC是如何應用的呢?
其他模型我不太清楚,在 OpenStack 中的應用模型是這樣的
至於為什麼要如此設計,前面我已經給出了自己的觀點。
接下來,就是源碼解讀 OpenStack ,看看其是如何通過rpc進行遠程調用的。如若你對此沒有興趣(我知道很多人對此都沒有興趣,所以不浪費大家時間),可以直接跳過這一節,進入下一節。
目前Openstack中有兩種RPC實現,一種是在oslo messaging,一種是在openstack.common.rpc。
openstack.common.rpc是舊的實現,oslo messaging是對openstack.common.rpc的重構。openstack.common.rpc在每個項目中都存在一份拷貝,oslo messaging即將這些公共代碼抽取出來,形成一個新的項目。oslo messaging也對RPC API 進行了重新設計,對多種 transport 做了進一步封裝,底層也是用到了kombu這個AMQP庫。(注:Kombu 是Python中的messaging庫。Kombu旨在通過為AMQ協議提供慣用的高級接口,使Python中的消息傳遞盡可能簡單,併為常見的消息傳遞問題提供經過驗證和測試的解決方案。)
關於oslo_messaging庫,主要提供了兩種獨立的API:
- oslo.messaging.rpc(實現了客戶端-服務器遠程過程調用)
- oslo.messaging.notify(實現了事件的通知機制)
因為 notify 實現是太簡單了,所以這裏我就不多說了,如果有人想要看這方面內容,可以收藏我的博客(http://python-online.cn) ,我會更新補充 notify 的內容。
OpenStack RPC 模塊提供了 rpc.call,rpc.cast, rpc.fanout_cast 三種 RPC 調用方法,發送和接收 RPC 請求。
- rpc.call 發送 RPC 同步請求並返回請求處理結果。
- rpc.cast 發送 RPC 異步請求,與 rpc.call 不同之處在於,不需要請求處理結果的返回。
- rpc.fanout_cast 用於發送 RPC 廣播信息無返回結果
rpc.call 和 rpc.rpc.cast 從實現代碼上看,他們的區別很小,就是call調用時候會帶有wait_for_reply=True參數,而cast不帶。
要了解 rpc 的調用機制呢,首先要知道 oslo_messaging 的幾個概念
-
transport:RPC功能的底層實現方法,這裡是rabbitmq的消息隊列的訪問路徑
transport 就是定義你如何訪連接消息中間件,比如你使用的是 Rabbitmq,那在 nova.conf中應該有一行transport_url的配置,可以很清楚地看出指定了 rabbitmq 為消息中間件,並配置了連接rabbitmq的user,passwd,主機,端口。
transport_url=rabbit://user:passwd@host:5672
def get_transport(conf, url=None, allowed_remote_exmods=None):
return _get_transport(conf, url, allowed_remote_exmods,
transport_cls=RPCTransport)
-
target:指定RPC topic交換機的匹配信息和綁定主機。
target用來表述 RPC 服務器監聽topic,server名稱和server監聽的exchange,是否廣播fanout。
class Target(object):
def __init__(self, exchange=None, topic=None, namespace=None,
version=None, server=None, fanout=None,
legacy_namespaces=None):
self.exchange = exchange
self.topic = topic
self.namespace = namespace
self.version = version
self.server = server
self.fanout = fanout
self.accepted_namespaces = [namespace] + (legacy_namespaces or [])
rpc server 要獲取消息,需要定義target,就像一個門牌號一樣。
rpc client 要發送消息,也需要有target,說明消息要發到哪去。
-
endpoints:是可供別人遠程調用的對象
RPC服務器暴露出endpoint,每個 endpoint 包涵一系列的可被遠程客戶端通過 transport 調用的方法。直觀理解,可以參考nova-conductor創建rpc server的代碼,這邊的endpoints就是 nova/manager.py:ConductorManager()
-
dispatcher:分發器,這是 rpc server 才有的概念 只有通過它 server 端才知道接收到的rpc請求,要交給誰處理,怎麼處理?
在client端,是這樣指定要調用哪個方法的。
而在server端,是如何知道要執行這個方法的呢?這就是dispatcher 要乾的事,它從 endpoint 里找到這個方法,然後執行,最後返回。
-
Serializer:在 python 對象和message(notification) 之間數據做序列化或是反序列化的基類。
主要方法有四個:
- deserialize_context(ctxt) :對字典變成 request contenxt.
- deserialize_entity(ctxt, entity) :對entity做反序列化,其中ctxt是已經deserialize過的,entity是要處理的。
- serialize_context(ctxt) :將Request context變成字典類型
- serialize_entity(ctxt, entity) :對entity做序列化,其中ctxt是已經deserialize過的,entity是要處理的。
-
executor:服務的運行方式,單線程或者多線程
每個notification listener都和一個executor綁定,來控制收到的notification如何分配。默認情況下,使用的是blocking executor(具體特性參加executor一節)
oslo_messaging.get_notification_listener(transport, targets, endpoints, executor=’blocking’, serializer=None, allow_requeue=False, pool=None)
rpc server 和rpc client 的四個重要方法
reset():Reset service.start():該方法調用后,server開始poll,從transport中接收message,然後轉發給dispatcher.該message處理過程一直進行,直到stop方法被調用。executor決定server的IO處理策略。可能會是用一個新進程、新協程來做poll操作,或是直接簡單的在一個循環中註冊一個回調。同樣,executor也決定分配message的方式,是在一個新線程中dispatch或是….. *stop():當調用stop之後,新的message不會被處理。但是,server可能還在處理一些之前沒有處理完的message,並且底層driver資源也還一直沒有釋放。wait():在stop調用之後,可能還有message正在被處理,使用wait方法來阻塞當前進程,直到所有的message都處理完成。之後,底層的driver資源會釋放。
06. 模仿OpenStack寫rpc調用
模仿是一種很高效的學習方法,我這裏根據 OpenStack 的調用方式,抽取出核心內容,寫成一個簡單的 demo,有對 OpenStack 感興趣的可以了解一下,大部分人也可以直接跳過這章節。
以下代碼不能直接運行,你還需要配置 rabbitmq 的連接方式,你可以寫在配置文件中,通過 get_transport 從cfg.CONF 中讀取,也可以直接將其寫成url的格式做成參數,傳給 get_transport 。
簡單的 rpc client
#coding=utf-8
import oslo_messaging
from oslo_config import cfg
# 創建 rpc client
transport = oslo_messaging.get_transport(cfg.CONF, url="")
target = oslo_messaging.Target(topic='test', version='2.0')
client = oslo_messaging.RPCClient(transport, target)
# rpc同步調用
client.call(ctxt, 'test', arg=arg)
簡單的 rpc server
#coding=utf-8
from oslo_config import cfg
import oslo_messaging
import time
# 定義endpoint類
class ServerControlEndpoint(object):
target = oslo_messaging.Target(namespace='control',
version='2.0')
def __init__(self, server):
self.server = server
def stop(self, ctx):
if self.server:
self.server.stop()
class TestEndpoint(object):
def test(self, ctx, arg):
return arg
# 創建rpc server
transport = oslo_messaging.get_transport(cfg.CONF, url="")
target = oslo_messaging.Target(topic='test', server='server1')
endpoints = [
ServerControlEndpoint(None),
TestEndpoint(),
]
server = oslo_messaging.get_rpc_server(transport, target,endpoints,executor='blocking')
try:
server.start()
while True:
time.sleep(1)
except KeyboardInterrupt:
print("Stopping server")
server.stop()
server.wait()
以上,就是本期推送的全部內容,周末两天沒有出門,都在寫這篇文章。真的快掏空了我自己,不過寫完后真的很暢快。
【精選推薦文章】
智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
帶您來看台北網站建置,台北網頁設計,各種案例分享
廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益