本文將通過Three.js的介紹及示例帶我們走進3D的奇妙世界。
文章來源:宜信技術學院 & 宜信支付結算團隊技術分享第6期-支付結算部支付研發團隊前端研發高級工程師-劉琳《three.js – 走進3D的奇妙世界》
分享者:宜信支付結算部支付研發團隊前端研發高級工程師-劉琳
原文首發於支付結算團隊公號-“野指針”
隨着人們對用戶體驗越來越重視,Web開發已經不滿足於2D效果的實現,而把目標放到了更加炫酷的3D效果上。Three.js是用於實現web端3D效果的JS庫,它的出現讓3D應用開發更簡單,本文將通過Three.js的介紹及示例帶我們走進3D的奇妙世界。
一、Three.js相關概念
1.1 Three.JS
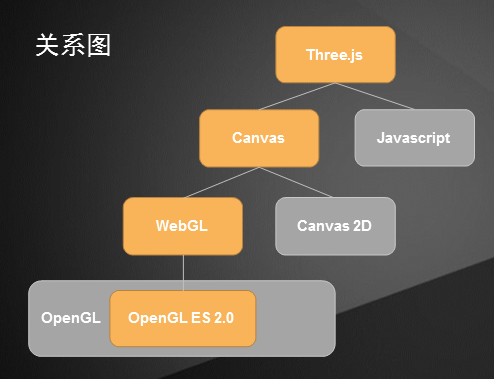
Three.JS是基於WebGL的Javascript開源框架,簡言之,就是能夠實現3D效果的JS庫。
1.2 WebGL
WebGL是一種Javascript的3D圖形接口,把JavaScript和OpenGL ES 2.0結合在一起。
1.3 OpenGL
OpenGL是開放式圖形標準,跨編程語言、跨平台,Javascript、Java 、C、C++ 、 python 等都能支持OpenG ,OpenGL的Javascript實現就是WebGL,另外很多CAD製圖軟件都採用這種標準。OpenGL ES 2.0是OpenGL的子集,針對手機、遊戲主機等嵌入式設備而設計。
1.4 Canvas
Canvas是HTML5的畫布元素,在使用Canvas時,需要用到Canvas的上下文,可以用2D上下文繪製二維的圖像,也可以使用3D上下文繪製三維的圖像,其中3D上下文就是指WebGL。
二、Three.js應用場景
利用Three.JS可以製作出很多酷炫的3D動畫,並且Three.js還可以通過鼠標、鍵盤、拖拽等事件形成交互,在頁面上增加一些3D動畫和3D交互可以產生更好的用戶體驗。
通過Three.JS可以實現全景視圖,這些全景視圖應用在房產、家裝行業能夠帶來更直觀的視覺體驗。在電商行業利用Three.JS可以實現產品的3D效果,這樣用戶就可以360度全方位地觀察商品了,給用戶帶來更好的購物體驗。另外,使用Three.JS還可以製作類似微信跳一跳那樣的小遊戲。隨着技術的發展、基礎網絡的建設,web3D技術還能得到更廣泛的應用。
三、主要組件
在Three.js中,有了場景(scene)、相機(camera)和渲染器(renderer) 這3個組建才能將物體渲染到網頁中去。
1)場景
場景是一個容器,可以看做攝影的房間,在房間中可以布置背景、擺放拍攝的物品、添加燈光設備等。
2)相機
相機是用來拍攝的工具,通過控制相機的位置和方向可以獲取不同角度的圖像。
3)渲染器
渲染器利用場景和相機進行渲染,渲染過程好比攝影師拍攝圖像,如果只渲染一次就是靜態的圖像,如果連續渲染就能得到動態的畫面。在JS中可以使用requestAnimationFrame實現高效的連續渲染。
3.1 常用相機
1)透視相機
透視相機模擬的效果與人眼看到的景象最接近,在3D場景中也使用得最普遍,這種相機最大的特點就是近大遠小,同樣大小的物體離相機近的在畫面上顯得大,離相機遠的物體在畫面上顯得小。透視相機的視錐體如上圖左側所示,從近端面到遠端面構成的區域內的物體才能显示在圖像上。
透視相機構造器
PerspectiveCamera( fov : Number, aspect : Number, near : Number, far : Number )
- fov — 攝像機視錐體垂直視野角度
- aspect — 攝像機視錐體長寬比
- near — 攝像機視錐體近端面
- far — 攝像機視錐體遠端面
2)正交相機
使用正交相機時無論物體距離相機遠或者近,在最終渲染的圖片中物體的大小都保持不變。正交相機的視錐體如上圖右側所示,和透視相機一樣,從近端面到遠端面構成的區域內的物體才能显示在圖像上。
正交相機構造器
OrthographicCamera( left : Number, right : Number, top : Number, bottom : Number, near : Number, far : Number )
- left — 攝像機視錐體左側面
- right — 攝像機視錐體右側面
- top — 攝像機視錐體上側面
- bottom — 攝像機視錐體下側面
- near — 攝像機視錐體近端面
- far — 攝像機視錐體遠端面
3.2 坐標系
在場景中,可以放物品、相機、燈光,這些東西放置到什麼位置就需要使用坐標系。Three.JS使用右手坐標系,這源於OpenGL默認情況下,也是右手坐標系。從初中、高中到大學的課堂上,教材中所涉及的幾何基本都是右手坐標系。
上圖右側就是右手坐標系,五指併攏手指放平,指尖指向x軸的正方向,然後把四個手指垂直彎曲大拇指分開,併攏的四指指向y軸的正方向,大拇指指向的就是Z軸的正方向。
在Three.JS中提供了坐標軸工具(THREE.AxesHelper),在場景中添加坐標軸后,畫面會出現3條垂直相交的直線,紅色表示x軸,綠色表示y軸,藍色表示z軸(如下圖所示)。
3.3 示例代碼
/* 場景 */
var scene = new THREE.Scene();
scene.add(new THREE.AxesHelper(10)); // 添加坐標軸輔助線
/* 幾何體 */
// 這是自定義的創建幾何體方法,如果創建幾何體後續會介紹
var kleinGeom = createKleinGeom();
scene.add(kleinGeom); // 場景中添加幾何體
/* 相機 */
var camera = new THREE.PerspectiveCamera(45, width/height, 1, 100);
camera.position.set(5,10,25); // 設置相機的位置
camera.lookAt(new THREE.Vector3(0, 0, 0)); // 相機看向原點
/* 渲染器 */
var renderer = new THREE.WebGLRenderer({antialias:true});
renderer.setSize(width, height);
// 將canvas元素添加到body
document.body.appendChild(renderer.domElement);
// 進行渲染
renderer.render(scene, camera);
四、幾何體
計算機內的3D世界是由點組成,兩個點能夠組成一條直線,三個不在一條直線上的點就能夠組成一個三角形面,無數三角形面就能夠組成各種形狀的幾何體。
以創建一個簡單的立方體為例,創建簡單的立方體需要添加8個頂點和12個三角形的面,創建頂點時需要指定頂點在坐標系中的位置,添加面的時候需要指定構成面的三個頂點的序號,第一個添加的頂點序號為0,第二個添加的頂點序號為1…
創建立方體的代碼如下:
var geometry = new THREE.Geometry();
// 添加8個頂點
geometry.vertices.push(new THREE.Vector3(1, 1, 1));
geometry.vertices.push(new THREE.Vector3(1, 1, -1));
geometry.vertices.push(new THREE.Vector3(1, -1, 1));
geometry.vertices.push(new THREE.Vector3(1, -1, -1));
geometry.vertices.push(new THREE.Vector3(-1, 1, -1));
geometry.vertices.push(new THREE.Vector3(-1, 1, 1));
geometry.vertices.push(new THREE.Vector3(-1, -1, -1));
geometry.vertices.push(new THREE.Vector3(-1, -1, 1));
// 添加12個三角形的面
geometry.faces.push(new THREE.Face3(0, 2, 1));
geometry.faces.push(new THREE.Face3(2, 3, 1));
geometry.faces.push(new THREE.Face3(4, 6, 5));
geometry.faces.push(new THREE.Face3(6, 7, 5));
geometry.faces.push(new THREE.Face3(4, 5, 1));
geometry.faces.push(new THREE.Face3(5, 0, 1));
geometry.faces.push(new THREE.Face3(7, 6, 2));
geometry.faces.push(new THREE.Face3(6, 3, 2));
geometry.faces.push(new THREE.Face3(5, 7, 0));
geometry.faces.push(new THREE.Face3(7, 2, 0));
geometry.faces.push(new THREE.Face3(1, 3, 4));
geometry.faces.push(new THREE.Face3(3, 6, 4));
4.1 正面和反面
創建幾何體的三角形面時,指定了構成面的三個頂點,如: new THREE.Face3(0, 2, 1),如果把頂點的順序改成0,1,2會有區別嗎?
通過下圖可以看到,按照0,2,1添加頂點是順時針方向的,而按0,1,2添加頂點則是逆時針方向的,通過添加頂點的方向就可以判斷當前看到的面是正面還是反面,如果頂點是逆時針方向添加,當前看到的面是正面,如果頂點是順時針方向添加,則當前面為反面。
下圖所看到的面就是反面。如果不好記,可以使用右手沿頂點添加的方向握住,大拇指所在的面就是正面,很像我們上學時學的電磁感應定律。
五、材質
創建幾何體時通過指定幾何體的頂點和三角形的面確定了幾何體的形狀,另外還需要給幾何體添加皮膚才能實現物體的效果,材質就像物體的皮膚,決定了物體的質感。常見的材質有如下幾種:
- 基礎材質:以簡單着色方式來繪製幾何體的材質,不受光照影響。
- 深度材質:按深度繪製幾何體的材質。深度基於相機遠近端面,離近端面越近就越白,離遠端面越近就越黑。
- 法向量材質:把法向量映射到RGB顏色的材質。
- Lambert材質:是一種需要光源的材質,非光澤表面的材質,沒有鏡面高光,適用於石膏等表面粗糙的物體。
- Phong材質:也是一種需要光源的材質,具有鏡面高光的光澤表面的材質,適用於金屬、漆面等反光的物體。
- 材質捕獲:使用存儲了光照和反射等信息的貼圖,然後利用法線方向進行採樣。優點是可以用很低的消耗來實現很多特殊風格的效果;缺點是僅對於固定相機視角的情況較好。
下圖是使用不同貼圖實現的效果:
六、光源
前面提到的光敏材質(Lambert材質和Phong材質)需要使用光源來渲染出3D效果,在使用時需要將創建的光源添加到場景中,否則無法產生光照效果。下面介紹一下常用的光源及特點。
6.1 點光源
點光源類似蠟燭放出的光,不同的是蠟燭有底座,點光源沒有底座,可以把點光源想象成懸浮在空中的火苗,點光源放出的光線來自同一點,且方向輻射向四面八方,點光源在傳播過程中有衰弱,如下圖所示,點光源在接近地面的位置,物體底部離點光源近,物體頂部離光源遠,照到物體頂部的光就弱些,所以頂部會比底部暗些。
6.2 平行光
平行光模擬的是太陽光,光源發出的所有光線都是相互平行的,平行光沒有衰減,被平行光照亮的整個區域接受到的光強是一樣的。
6.3 聚光燈
類似舞台上的聚光燈效果,光源的光線從一個錐體中射出,在被照射的物體上產生聚光的效果。聚光燈在傳播過程也是有衰弱的。
6.4 環境光
環境光是經過多次反射而來的光,環境光源放出的光線被認為來自任何方向,物體無論法向量如何,都將表現為同樣的明暗程度。
環境光通常不會單獨使用,通過使用多種光源能夠實現更真實的光效,下圖是將環境光與點光源混合后實現的效果,物體的背光面不像點光源那樣是黑色的,而是呈現出深褐色,更自然。
七、紋理
在生活中純色的物體還是比較少的,更多的是有凹凸不平的紋路或圖案的物體,要用Three.JS實現這些物體的效果,就需要使用到紋理貼圖。3D世界的紋理是由圖片組成的,將紋理添加在材質上以一定的規則映射到幾何體上,幾何體就有了帶紋理的皮膚。
7.1 普通紋理貼圖
在這個示例中使用上圖左側的地球紋理,在球形幾何體上進行貼圖就能製作出一個地球。
代碼如下:
/* 創建地球 */
function createGeom() {
// 球體
var geom = new THREE.SphereGeometry(1, 64, 64);
// 紋理
var loader = new THREE.TextureLoader();
var texture = loader.load('./earth.jpg');
// 材質
var material = new THREE.MeshLambertMaterial({
map: texture
});
var earth = new THREE.Mesh(geom, material);
return earth;
}
7.2 反面貼圖實現全景視圖
這個例子是通過在球形幾何體的反面進行紋理貼圖實現的全景視圖,實現原理是這樣的:創建一個球體構成一個球形的空間,把相機放在球體的中心,相機就像在一個球形的房間中,在球體的裏面(也就是反面)貼上圖片,通過改變相機拍攝的方向,就能看到全景視圖了。
材質默認是在幾何體的正面進行貼圖的,如果想要在反面貼圖,需要在創建材質的時候設置side參數的值為THREE.BackSide,代碼如下:
/* 創建反面貼圖的球形 */
// 球體
var geom = new THREE.SphereGeometry(500, 64, 64);
// 紋理
var loader = new THREE.TextureLoader();
var texture = loader.load('./panorama.jpg');
// 材質
var material = new THREE.MeshBasicMaterial({
map: texture,
side: THREE.BackSide
});
var panorama = new THREE.Mesh(geom, material);
7.3 凹凸紋理貼圖
凹凸紋理利用黑色和白色值映射到與光照相關的感知深度,不會影響對象的幾何形狀,隻影響光照,用於光敏材質(Lambert材質和Phong材質)。
如果只用上圖左上角的磚牆圖片進行貼圖的話,就像一張牆紙貼在上面,視覺效果很差,為了增強立體感,可以使用上圖左下角的凹凸紋理,給物體增加凹凸不平的效果。
凹凸紋理貼圖使用方式的代碼如下:
// 紋理加載器
var loader = new THREE.TextureLoader();
// 紋理
var texture = loader.load( './stone.jpg');
// 凹凸紋理
var bumpTexture = loader.load( './stone-bump.jpg');
// 材質
var material = new THREE.MeshPhongMaterial( {
map: texture,
bumpMap: bumpTexture
} );
7.4 法線紋理貼圖
法線紋理也是通過影響光照實現凹凸不平視覺效果的,並不會影響物體的幾何形狀,用於光敏材質(Lambert材質和Phong材質)。上圖左下角的法線紋理圖片的RGB值會影響每個像素片段的曲面法線,從而改變物體的光照效果。
使用方式的代碼如下:
// 紋理
var texture = loader.load( './metal.jpg');
// 法線紋理
var normalTexture = loader.load( './metal-normal.jpg');
var material = new THREE.MeshPhongMaterial( {
map: texture,
normalMap: normalTexture
} );
7.5 環境貼圖
環境貼圖是將當前環境作為紋理進行貼圖,能夠模擬鏡面的反光效果。在進行環境貼圖時需要使用立方相機在當前場景中進行拍攝,從而獲得當前環境的紋理。立方相機在拍攝環境紋理時,為避免反光效果的小球出現在環境紋理的畫面上,需要將小球設為不可見。
環境貼圖的主要代碼如下:
/* 立方相機 */
var cubeCamera = new THREE.CubeCamera( 1, 10000, 128 );
/* 材質 */
var material = new THREE.MeshBasicMaterial( {
envMap: cubeCamera.renderTarget.texture
});
/* 鏡面反光的球體 */
var geom = new THREE.SphereBufferGeometry( 10, 32, 16 );
var ball = new THREE.Mesh( geom, material );
// 將立方相機添加到球體
ball.add( cubeCamera );
scene.add( ball );
// 立方相機生成環境紋理前將反光小球隱藏
ball.visible = false;
// 更新立方相機,生成環境紋理
cubeCamera.update( renderer, scene );
balls.visible = true;
// 渲染
renderer.render(scene, camera);
八、加載外部3D模型
Three.JS已經內置了很多常用的幾何體,如:球體、立方體、圓柱體等等,但是在實際使用中往往需要用到一些特殊形狀的幾何體,這時可以使用3D建模軟件製作出3D模型,導出obj、json、gltf等格式的文件,然後再加載到Three.JS渲染出效果。
上圖的椅子是在3D製圖軟件繪製出來的,chair.mtl是導出的材質文件,chair.obj是導出的幾何體文件,使用材質加載器加載材質文件,加載完成后得到材質對象,給幾何體加載器設置材質,加載后得到幾何體對象,然後再創建場景、光源、攝像機、渲染器等進行渲染,這樣就等得到如圖的效果。主要的代碼如下:
// .mtl材質文件加載器
var mtlLoader = new THREE.MTLLoader();
// .obj幾何體文件加載器
var objLoader = new THREE.OBJLoader();
mtlLoader.load('./chair.mtl', function (materials) {
objLoader.setMaterials(materials)
.load('./chair.obj', function (obj) {
scene.add(obj);
…
});
});
九、說明
以上內容對Three.JS的基本使用進行了介紹,文中涉及到的示例源碼已上傳到github,感興趣的同學可以下載查看,下載地址:https://github.com/liulinsp/three-demo。使用時如果有不清楚的地方可以查看Three.JS的官方文檔:https://threejs.org/docs/index.html。
作者:劉琳
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【精選推薦文章】
自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"