一、導語
如何省去企業上門(現場)搜集客戶需求的環節,節約企業人力和時間成本,將客戶的業務定製需求直接上傳至雲數據庫?雲開發為我們提供了這個便利!
二、需求背景
作為一名XX公司IT萌萌新,這段時間對小程序開發一直有非常濃厚的興趣,並且感慨於“雲開發·不止於快”的境界。近期工作中,剛好碰見業務部門的一個需求,目的是節約上門跟客戶收集業務定製資料的時間,以往是每變更一次,就需要上門一次,碰見地域較遠的,費時費力,且往往要求幾天內完成上線,時間非常緊迫。因此,結合一直以來對雲開發的各種優勢的了解,我說服公司領導通過小程序·雲開發來實現。
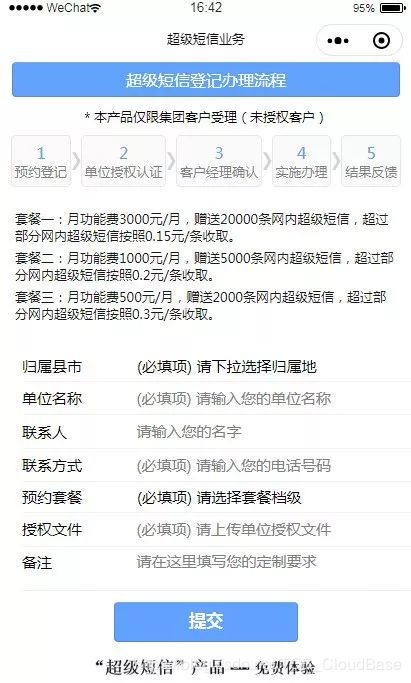
下面是其中一項業務定製界面的展示:
(1)業務對業務流程有簡單說明;
(2)相關業務介紹;
(3)不同客戶輸入個性化需求;
(4)雲存儲後台實現需求表單的收集。
得力於雲開發提供的API和WeUI庫的便利,本項目在我在極短的時間內就實現了比較理想的效果 。接下來,我就從本項目入手,講講我是如何依靠小程序·雲開發將想法快速實現的,其實我也是剛入門沒多久,只是想分享一下自身在學習小程序開發項目中的一些知識點和體會,代碼可能略為粗糙,邏輯也有待優化,歡迎大家在評論區多多交流。
三、開發過程
1、組件
主要使用了官方WeUI擴展能力的一些組件庫來實現主要功能。
核心的WeUI庫主要有 Msg、Picker、圖片的Upload等(以快為目的,節省自己寫CSS樣式的時間,也方便0基礎的同學上手,這裏又體會到了小程序開發的便捷)。
2、實現代碼
本次雲開發包括雲數據庫、雲存儲兩大功能:
(1)雲數據庫
雲數據庫的主要就是搜集客戶提交上來的表單信息,包括客戶的聯繫方式和選擇的業務類型等,並存儲在雲數據庫中,方便業務經理搜集需求。
我們來看簡單的實現過程:
首先是表單,用到了 form 表單組件以及它的 bindsubmit 方法,在 wxml 中放置 form 表單:
<form bindsubmit="formSubmit">
<view class="form">
<view class="section">
<picker bindchange="bindPickerGsd" mode="selector" value="{{indexGsd}}" range="{{arrayGsd}}">
<view class="picker">歸屬縣市</view>
<view class="picker-content" >{{arrayGsd[indexGsd]?arrayGsd[indexGsd]:"(必填項) 請下拉選擇歸屬地"}}</view>
</picker>
</view>
<!---中間部分詳見代碼--->
</view>
<view class="footer">
<button class="dz-btn" formType="submit" loading="{{formStatus.submitting}}" disabled="{{formStatus.submitting}}" bindtap="openSuccess">提交</button>
</view>
</form>表單中除了普通的文本輸入,增加有下拉列表的實現(畢竟客戶有時候是比較懶的)。
來看一下具體代碼:
bindPickerGsd: function (e) {
console.log('歸屬地已選擇,攜帶值為', e.detail.value)
console.log('歸屬地選擇:', this.data.arrayGsd[e.detail.value])
this.setData({
indexGsd: e.detail.value
})
this.data.formData.home_county = this.data.arrayGsd[e.detail.value]
},最後表單上傳到雲數據庫:
// 表單提交
formSubmit: function (e) {
var minlength = '';
var maxlength = '';
console.log("表單內容",e)
var that = this;
var formData = e.detail.value;
var result = this.wxValidate.formCheckAll(formData);
console.log("表單提交formData", formData);
console.log("表單提交result", result)
wx.showLoading({
title: '發布中...',
})
const db = wx.cloud.database()
db.collection('groupdata').add({
data: {
time: getApp().getNowFormatDate(),
home_county: this.data.formData.home_county,
group_name: formData.group_name,
contact_name: formData.contact_name,
msisdn: formData.msisdn,
product_name: this.data.formData.product_name,
word: formData.word,
},
success: res => {
wx.hideLoading()
console.log('發布成功', res)
},
fail: err => {
wx.hideLoading()
wx.showToast({
icon: 'none',
title: '網絡不給力....'
})
console.error('發布失敗', err)
}
})
},(2)雲存儲
因為業務的定製需要填單客戶所在單位的授權證明材料,因此需要提單人(使用人)上傳證明文件,因此增加了使用雲存儲的功能。
核心代碼:
promiseArr.push(new Promise((reslove,reject)=>{
wx.cloud.uploadFile({
cloudPath: "groupdata/" + group_name + "/" + app.getNowFormatDate() +suffix,
filePath:filePath
}).then(res=>{
console.log("授權文件上傳成功")
})
reslove()
}).catch(err=>{
console.log("授權文件上傳失敗",err)
})
因為涉及到不同頁面的數據傳遞,即將表單頁面的group_name作為雲存儲的文件夾用於存儲該客戶在表單中上傳的圖片,因此還需要用到getCurrentPages()來進行頁面間的數據傳遞
var pages = getCurrentPages();
var prePage = pages[pages.length - 2];//pages.length就是該集合長度 -2就是上一個活動的頁面,也即是跳過來的頁面
var group_name = prePage.data.formData.group_name.value//取上頁data里的group_name數據用於標識授權文件所存儲文件夾的名稱
3、待進一步優化
基於時間關係,本次版本僅對需求進行了簡單實現,作為公司一個可靠的項目,還需要關注”客戶隱私”、“數據安全”,以及更人性化的服務。比如:
(1)提單人確認和認證過程
可靠性:增加驗證碼驗證(防止他人冒名登記),以及公司受理業務有個客戶本人提交憑證。
(2)訂閱消息
受理成功后,可以給客戶進行處理結果的反饋,增強感知。
(3)人工客服
進行在線諮詢等。
四、總結
在本次項目開發中,我深刻體會到了雲開發的“快”,特別是雲數據庫的增刪查改功能非常方便。雲開發提供的種種便利,讓我在有新創意的時候,可以迅速採用小程序雲開發快速實現,省時省力,還能免費使用騰訊雲服務器,推薦大家嘗試!
源碼地址
如果你想要了解更多關於雲開發CloudBase相關的技術故事/技術實戰經驗,請掃碼關注【騰訊云云開發】公眾號~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※試算大陸海運運費!