計算二進制形式中1的數量這種問題,在各種刷題網站上比較常見,以往都是選擇最笨的遍歷方法“矇混”過關。在了解Redis的過程中接觸到了variable precision SWAR算法(以下簡稱VP-SWAR算法),算法異常簡潔,是目前已知的同類方法中最快的。但如果對於位運算不是很熟悉的話,卻不一定容易理解,所以有必要記錄一下。
下面先看看VP-SWAR算法的完整實現,然後再逐行解釋。
public int vpSWAR(int i){ i = (i & 0x55555555) + ((i>>1) & 0x55555555); i = (i & 0x33333333) + ((i>>2) & 0x33333333); i = (i & 0x0F0F0F0F) + ((i>>4) & 0x0F0F0F0F); i = (i * 0x01010101) >> 24; return i; }
VP-SWAR算法分為四步,第一步
i = (i & 0x55555555) + ((i>>1) & 0x55555555);
第一步的作用是計算每兩位為一組的二進制形式包含1的個數。要理解這句話,我們需要從二進制的角度看看到底發生了什麼。首先, 0x55555555 的二進製表示為 0101 0101 0101 0101 0101 0101 0101 0101 ,這個数字的規律是基數位為1,偶數位為0。為簡單起見,我們只考慮兩位,總共有四種情況,即:
| i | b | i & b 結果 |
| 00 | 01 | 00 |
| 01 | 01 | 01 |
| 10 | 01 | 00 |
| 11 | 01 | 01 |
觀察發現, i & (0b01) 是i的基數位對應b的1位,i的偶數位對應着b的0位, i & (0b01) 的結果會將I的偶數位置為0,而基數位保持不變,得到的結果就是i的基數位包含1的個數。 (i >> 1) & 0x55555555 先將i右移一位,也就是將i的基數位對應b的0位,i的偶數位對應着b的1位,然後再與 0x55555555 按位與,計算出來的是i的偶數位包含1的個數。兩個計算結果相加就得到i每兩位為一組中包含的1的數量,我們最後需要的就是這每兩位一組的和。
第二步是在第一步的基礎上,計算每四位為一組包含1的個數。按照每2位為一組分組用到了 0x55555555 這個數,那麼自然的,按照每4位為一組分組自然就需要 0b0011 這種形式,這就是使用 0x33333333 的原因。理論上, i & (0b0011) 總共有16種情況,但是四位二進制位最多包含4個1,用二進製表示為 0b0100 ,所以經過第一步之後,i最多有5種取值,如下:
| i | b | i & b 結果 |
| 0000 | 0011 | 0000 |
| 0001 | 0011 | 0001 |
| 0010 | 0011 | 0010 |
| 0011 | 0011 | 0011 |
| 0100 | 0011 | 0000 |
觀察發現, i & (0b0011) 得到的是i的低兩位包含的1的個數, (i >> 2) & 0b0011 )得到的是i的高兩位包含的1的個數,兩個結果相加得到每四位包含的1的個數。注意,這裏並不是說任何數與 0b0011 按位與得到的都是低兩位包含的1的個數,這裏的前提是第一步的計算,因為經過第一步計算之後,每兩位包含多少個1已經記錄了下來,再和 0b0011 按位與才得到正確的結果。例如, 0x0010 & 0x 0011=0x0010 ,但是我們不能說 0x0010 包含兩個1,但是如果 0x0010 是經過第一步的計算得來,那才說明 0x0010 記錄原始數據低兩位有兩個1。
第三步在第二步基礎上,計算每8位有多少個1,由 0x01 和 0x0011 ,很自然想到 0x00001111 ,其對應的32位的十六進制數就是 0x0F0F0F0F 。
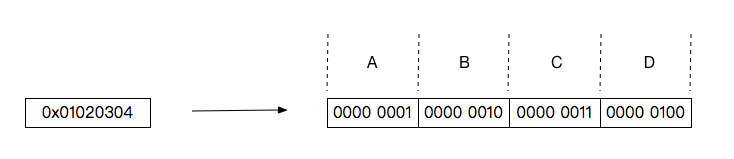
第四步就很有意思了,它不再是計算每16位包含1的個數,而是直接計算32位包含1的個數。對於32位的數來說,可以將其按每8位一組分為4組,分別用ABCD表示,例如 0x01020304 用這種形式表示為:
假設 0x01020304 是經過前三步計算之後得到的結果,那麼要計算其總共包含多少個1,只需計算A+B+C+D。而ABCD表示的是不同的位區間範圍,不能直接相加,該如何快速計算A+B+C+D的值呢?這裏又用到了移位運算,將B、C、D分別左移8位、16位、24位,使其分別與A對齊:
我們發現,將数字i分別左移0位、8位、16位、24位然後相加的結果,就是 i * 0x01010101 ,因為 i + (i << 8) + (i << 16) + (i << 24) = i * (1 + 1 << 8 + 1 << 16 + 1 << 24) = i * 0x01010101 。對於32位数字來說,左移之後超過32位的部分會被捨棄,低位補0,將左移之後得到的四個数字相加,結果的高8位的值就是原32位數包含的1的個數,要得到這個值,只需要將結果右移24位,將值放在低8位即可。
到這裏,整個算法就結束了,右移的結果就是1的數量。在Redis中,BITCOUNT命令同時使用了查表法和VP-SWAR這兩種方法。當要計算的位數小於128位時,使用查表法,否則使用VP-SWAR算法。其中查表法的做法是,程序先存一個256長度的表,按順序記錄從0-255(即 0b00000000 – 0b11111111) 數中二進制1的個數,然後對於輸入參數每8位查一次表。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!