Android音頻開發(1):基礎知識
導讀
人的說話頻率基本上為300Hz~3400Hz,但是人耳朵聽覺頻率基本上為20Hz~20000Hz。
對於人類的語音信號而言,實際處理一般經過以下步驟:
人嘴說話——>聲電轉換——>抽樣(模數轉換)——>量化(將数字信號用適當的數值表示)——>編碼(數據壓縮)——>
傳輸(網絡或者其他方式)
——> 解碼(數據還原)——>反抽樣(數模轉換)——>電聲轉換——>人耳聽聲。
- 抽樣率
實際中,人發出的聲音信號為模擬信號,想要在實際中處理必須為数字信號,即採用抽樣、量化、編碼的處理方案。
處理的第一步為抽樣,即模數轉換。
簡單地說就是通過波形採樣的方法記錄1秒鐘長度的聲音,需要多少個數據。
根據奈魁斯特(NYQUIST)採樣定理,用兩倍於一個正弦波的頻繁率進行採樣就能完全真實地還原該波形。
所以,對於聲音信號而言,要想對離散信號進行還原,必須將抽樣頻率定為40KHz以上。實際中,一般定為44.1KHz。
44.1KHz採樣率的聲音就是要花費44000個數據來描述1秒鐘的聲音波形。
原則上採樣率越高,聲音的質量越好,採樣頻率一般共分為22.05KHz、44.1KHz、48KHz三個等級。
22.05 KHz只能達到FM廣播的聲音品質,44.1KHz則是理論上的CD音質界限,48KHz則已達到DVD音質了。
- 碼率
對於音頻信號而言,實際上必須進行編碼。在這裏,編碼指信源編碼,即數據壓縮。如果,未經過數據壓縮,直接量化進行傳輸則被稱為PCM(脈衝編碼調製)。
要算一個PCM音頻流的碼率是一件很輕鬆的事情,採樣率值×採樣大小值×聲道數 bps。
一個採樣率為44.1KHz,採樣大小為16bit,雙聲道的PCM編碼的WAV文件,它的數據速率則為 44.1K×16×2 =1411.2 Kbps。
我們常說128K的MP3,對應的WAV的參數,就是這個1411.2 Kbps,這個參數也被稱為數據帶寬,它和ADSL中的帶寬是一個概念。將碼率除以8,就可以得到這個WAV的數據速率,即176.4KB/s。這表示存儲一秒鐘採樣率為44.1KHz,採樣大小為16bit,雙聲道的PCM編碼的音頻信號,需要176.4KB的空間,1分鐘則約為10.34M,這對大部分用戶是不可接受的,尤其是喜歡在電腦上聽音樂的朋友,要降低磁盤佔用
只有2種方法,
降低採樣指標或者壓縮。降低指標是不可取的,因此專家們研發了各種壓縮方案。最原始的有DPCM、ADPCM,其中最出名的為MP3。所以,採用了數據壓縮以後的碼率遠小於原始碼率。
一、發的主要應用有哪些?
音頻播放器,錄音機,語音電話,音視頻監控應用,音視頻直播應用,音頻編輯/處理軟件,藍牙耳機/音箱,等等。
二、頻開發的具體內容有哪些?
(1)音頻採集/播放
(2)音頻算法處理(去噪、靜音檢測、回聲消除、音效處理、功放/增強、混音/分離,等等)
(3)音頻的編解碼和格式轉換
(4)音頻傳輸協議的開發(SIP,A2DP、AVRCP,等等)
三、 音頻應用的難點在哪?
延時敏感、卡頓敏感、噪聲抑制(Denoise)、回聲消除(AEC)、靜音檢測(VAD)、混音算法,等等。
四、 音頻開發基礎概念有哪些?
在音頻開發中,下面的這幾個概念經常會遇到。
1. 採樣率(samplerate)
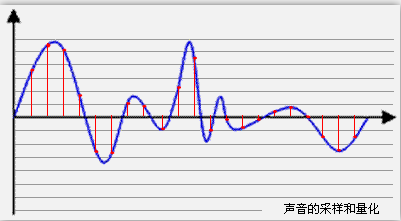
採樣就是把模擬信號数字化的過程,不僅僅是音頻需要採樣,所有的模擬信號都需要通過採樣轉換為可以用0101來表示的数字信號,示意圖如下所示:
藍色代表模擬音頻信號,紅色的點代表採樣得到的量化數值。
採樣頻率越高,紅色的間隔就越密集,記錄這一段音頻信號所用的數據量就越大,同時音頻質量也就越高。
根據奈奎斯特理論,採樣頻率只要不低於音頻信號最高頻率的兩倍,就可以無損失地還原原始的聲音。
通常人耳能聽到頻率範圍大約在20Hz~20kHz之間的聲音,為了保證聲音不失真,採樣頻率應在40kHz以上。常用的音頻採樣頻率有:8kHz、11.025kHz、22.05kHz、16kHz、37.8kHz、44.1kHz、48kHz、96kHz、192kHz等。
對採樣率為44.1kHz的AAC音頻進行解碼時,一幀的解碼時間須控制在23.22毫秒內。
通常是按1024個採樣點一幀
分析:
1. AAC
一個AAC原始幀包含某段時間內1024個採樣點相關數據。
用1024主要是因為AAC是用的1024點的mdct。
音頻幀的播放時間=一個AAC幀對應的採樣樣本的個數/採樣頻率(單位為s)
採樣率(samplerate)為 44100Hz,表示每秒 44100個採樣點,
所以,根據公式,
音頻幀的播放時長 = 一個AAC幀對應的採樣點個數 / 採樣頻率
則,當前一幀的播放時間 = 1024 * 1000/44100= 23.22 ms(單位為ms)
48kHz採樣率,
則,當前一幀的播放時間 = 1024 * 1000/48000= 21.333ms(單位為ms)
22.05kHz採樣率,
則,當前一幀的播放時間 = 1024 * 1000/22050= 46.439ms(單位為ms)
2. MP3
mp3 每幀均為1152個字節,
則:
每幀播放時長 = 1152 * 1000 / sample_rate
例如:sample_rate = 44100HZ時,
計算出的時長為26.122ms,
這就是經常聽到的mp3每幀播放時間固定為26ms的由來。
2. 量化精度(位寬)
上圖中,每一個紅色的採樣點,都需要用一個數值來表示大小,這個數值的數據類型大小可以是:4bit、8bit、16bit、32bit等等,位數越多,表示得就越精細,聲音質量自然就越好,當然,數據量也會成倍增大。
常見的位寬是:8bit 或者 16bit
3. 聲道數(channels)
由於音頻的採集和播放是可以疊加的,因此,可以同時從多個音頻源採集聲音,並分別輸出到不同的揚聲器,故聲道數一般表示聲音錄製時的音源數量或回放時相應的揚聲器數量。
單聲道(Mono)和雙聲道(Stereo)比較常見,顧名思義,前者的聲道數為1,後者為2
4. 音頻幀(frame)
是用於測量显示幀數的量度。所謂的測量單位為每秒显示幀數(Frames per Second,簡稱:FPS)或“赫茲”(Hz)。
音頻跟視頻很不一樣,視頻每一幀就是一張圖像,而從上面的正玄波可以看出,音頻數據是流式的,本身沒有明確的一幀幀的概念,在實際的應用中,為了音頻算法處理/傳輸的方便,一般約定俗成取2.5ms~60ms為單位的數據量為一幀音頻。
這個時間被稱之為“採樣時間”,其長度沒有特別的標準,它是根據編×××和具體應用的需求來決定的,我們可以計算一下一幀音頻幀的大小:
假設某通道的音頻信號是採樣率為8kHz,位寬為16bit,20ms一幀,雙通道,則一幀音頻數據的大小為:
int size = 8000 x 16bit x 0.02s x 2 = 5120 bit = 640 byte
五、常見的音頻編碼方式有哪些?
上面提到過,模擬的音頻信號轉換為数字信號需要經過採樣和量化,量化的過程被稱之為編碼,根據不同的量化策略,產生了許多不同的編碼方式,常見的編碼方式有:PCM 和 ADPCM,這些數據代表着無損的原始数字音頻信號,添加一些文件頭信息,就可以存儲為WAV文件了,它是一種由微軟和IBM聯合開發的用於音頻数字存儲的標準,可以很容易地被解析和播放。
我們在音頻開發過程中,會經常涉及到WAV文件的讀寫,以驗證採集、傳輸、接收的音頻數據的正確性。
六、常見的音頻壓縮格式有哪些?
首先簡單介紹一下音頻數據壓縮的最基本的原理:因為有冗餘信息,所以可以壓縮。
(1) 頻譜掩蔽效應: 人耳所能察覺的聲音信號的頻率範圍為20Hz~20KHz,在這個頻率範圍以外的音頻信號屬於冗餘信號。
(2) 時域掩蔽效應: 當強音信號和弱音信號同時出現時,弱信號會聽不到,因此,弱音信號也屬於冗餘信號。
下面簡單列出常見的音頻壓縮格式:
MP3,AAC,OGG,WMA,Opus,FLAC,APE,m4a,AMR,等等
七、Adndroid VoIP相關的開源應用有哪些 ?
imsdroid,sipdroid,csipsimple,linphone,WebRTC 等等
八、音頻算法處理的開源庫有哪些 ?
speex、ffmpeg,webrtc audio module(NS、VAD、AECM、AGC),等等
九、Android提供了哪些音頻開發相關的API?
音頻採集: MediaRecoder,AudioRecord
音頻播放: SoundPool,MediaPlayer,AudioTrack
音頻編解碼: MediaCodec
NDK API: OpenSL ES
十、音頻開發的延時標準是什麼?
ITU-TG.114規定,對於高質量語音可接受的時延是300ms。一般來說,如果時延在300~400ms,通話的交互性比較差,但還可以接受。時延大於400ms時,則交互通信非常困難。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!

