使用mybatis逆向工程的時候,delete方法的使用姿勢不對,導致表被清空了,在生產上一刷新后發現表裡沒數據了,一股涼意從腳板心直衝天靈蓋。
於是開發了一個攔截器,並寫下這篇文章記錄並分享。
這鍋只能自己背了
你用過 mybatis 逆向工程(mybatis-generator-maven-plugin)生成相關文件嗎?
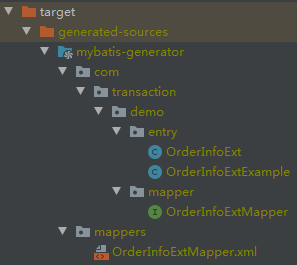
就像這樣式兒的:
可以看到逆向工程幫我們生成了實體類、Mapper 接口和 Mapper.xml。
用起來真的很方便,我用了好幾年了,但是前段時間翻車了。
具體是怎麼回事呢,我給大家擺一下。
先說一下需求吧。就是在做一次借據數據遷移的過程中,要先通過 A 服務的接口拿到所有的借據和對應的還款計劃數據,然後再對這些借據進行核查,如果不滿足某些添加,就需要從表中刪除借據和對應的還款計劃。
借據和對應的還款計劃存放在兩張表中,用借據號來關聯。
而上線之後,我在一片歡聲笑語中把還款計劃表清空了,而這個必現的問題,在測試階段同學還沒有測試出來。
事情發生后我趕緊找到了 DBA 協助修複數據:
是怎麼回事呢,為了模擬這個場景,我在本地創建了兩張表,訂單表(orderInfo)和訂單擴展表(orderInfoExt),他們之間用訂單號進行關聯:
僅僅是做演示,所以兩張表是非常簡單的,
我們假設現在表裡面的這條訂單號為 2020060666666 的數據經過判斷是錯誤數據,我當時寫的代碼體現在單元測試裏面是這樣的:
看出問題了嗎?
第 42 行用的 example 對象還是 OrderInfo 的 example。而真正的 OrderInfoExt 對象的 exampleExt 對象沒有進行任何賦值的操作。
為什麼會出現這樣的烏龍呢?
都怪 idea 太智能了!(強行找個借口)
我只需要打一個 ex 然後回個車…. example 就出現在代碼裏面了。
而這種沒有參數的 example 傳進去,在 mapper.xml 裏面是這樣處理的:
執行一下,看看效果:
看到 delete from order_info_ext 語句。你說你慌不慌?
當然在線上的服務器肯定是看不到執行的 SQL 的,但是當報警短信一條一條接着來的時候,當連上數據庫一看錶,發現數據沒了的時候。
你說你慌不慌?
反正我一刷新后發現表裡沒數據了,一股涼意從腳板心直衝天靈蓋。這種時候都還是要小小的心慌一下,先大喊一聲“卧槽!數據怎麼沒了?”
然後趕緊報備,準備找 DBA 撈數據吧。
還好,本次誤刪不影響正常業務。
數據恢復過程就不說了,聊一下這事發生后我的一點思考吧。
哦,對了,還得說一下測試同學為什麼沒有發現這個問題。這個問題確實是一個必現的問題,測試案例上也寫了這個測試點。
但是測試同學查看數據的時候用的是 select 語句,查詢條件給的是確實需要被刪除的數據 。
然後分別在兩個表裡面執行后發現:數據確實是沒了。
是的,是數據確實是沒了。整個表都乾淨了。
看着測試妹子驚慌失措的樣子,我還能怎麼說呢?
這鍋,不甩了,我自己背下來吧。
重新審視逆向工程
我們先看看逆向工程幫我們生成的接口:
我相信用過 mybatis 逆向工程的朋友們,一看到這幾個接口就知道了:喲,這都是老朋友了。
當我再去重新審視這些接口的時候我會發現其實還有會有一些問題的。
比如 delete 這樣的高危語句我們還是需要盡量的手寫 xml。
比如 updateByExample 同樣存在由於誤操作沒有 where 條件,導致全表更新的情況。
比如 select 語句是查出了整個對象,但是有時間我們可能只需要對象裏面的某個值而已。
比如 select 語句針對大表、關鍵表操作的時候,不能從代碼的角度限定 SQL 必須帶上索引字段查詢。
上面的這些問題我們怎麼處理呢?
我的建議是不要使用 mybatis 的逆向工程,全都手寫。
開個玩笑。我們肯定不能因噎廢食,何況逆向工程確實是幫我們做了很多工作,極大的方便我們這樣的 CRUD Boy 進行 CRUD。
所以,我想 mybatis 的逆向工程肯定是有什麼配置來控制生成哪些接口的,別問為什麼,問就是直覺。
因為要是讓我去開發這樣的一個插件,我肯定也會提供對應的開關配置。
我現在的想法是不讓它給我生成 delete 相關的接口,這個接口用起來我心裏害怕。
所以怎麼配置呢?
我們去它的 DTD 文件裏面找一下嘛:
這個文件不長,一共也才 213 行,你能發現這一塊東西:
你用腳指頭想也能知道,這就是我們要找的開關配置。從 DTD 文件的描述中來看,這個幾個參數是配置在 table 標籤裏面的。
我們去試一下:
果然是這樣的。然後我們進行相關配置如下:
再生成一下:
果然,delete 相關的接口沒了。
然後我們程序中真的需要 delete 操作的時候,再自己去手寫 xml 文件。
那你自己寫的 xml 文件也忘記寫 where 條件了這麼辦?
這個月工資別領了。自己好好反思反思。
當然,就算你真的忘記寫了,下面這個攔截器還能給你兜個底,幫你一把。
mybatis 攔截器使用
其實這個方案是我想到的第一個方案。導致上面問題的原因很簡單嘛,就是執行了delete 語句卻沒有 where 條件。
那麼我們可以攔截到這個 SQL 語句,然後對其進行兩個判斷:
是否是 delete 語句。 如果是,是否包含 where 條件。
那麼問題來了,我們怎麼去攔截到這個 SQL 呢?
答案就是我們可以開發一個 mybatis 插件呀,就像分頁插件那樣。
插件,聽起來很高端的樣子,其實他就是個攔截器。實現起來非常簡單。
先去官網上看一下:
中文:https://mybatis.org/mybatis-3/zh/configuration.html#plugins
英文:https://mybatis.org/mybatis-3/configuration.html
在官網上,對於插件這一模塊的描述是這樣的:
通過 MyBatis 提供的強大機制,使用插件是非常簡單的,只需實現 Interceptor 接口,並指定想要攔截的方法簽名即可。
正如官網說的這樣,插件開發、使用起來是非常簡單的。只需要三步:
1.實現 Interceptor 接口。
2.指定想要攔截的方法簽名。
3.配置這個插件。
mybatis 插件開發
基於上面這三步,大家先看一下我們這插件怎麼寫,以及這個插件的效果。
先說明一下本文涉及到的源碼 mybatis 版本是 3.4.0。
本文用攔截器的目的是判斷 delete 語句中是否有 where 條件。所以,開發出來的插件長這樣:
再來一個複製粘貼直接運行版本:
@Slf4j
@Intercepts({
@Signature(type = Executor.class, method = "update",
args = {MappedStatement.class, Object.class}),
})
public class CheckSQLInterceptor implements Interceptor {
private static String SQL_WHERE = "where";
@Override
public Object intercept(Invocation invocation) throws Throwable {
//獲取方法的第0個參數,也就是MappedStatement。@Signature註解中的args中的順序
MappedStatement mappedStatement = (MappedStatement) invocation.getArgs()[0];
//獲取sql命令操作類型
SqlCommandType sqlCommandType = mappedStatement.getSqlCommandType();
final Object[] queryArgs = invocation.getArgs();
final Object parameter = queryArgs[1];
BoundSql boundSql = mappedStatement.getBoundSql(parameter);
String sql = boundSql.getSql();
if (SqlCommandType.DELETE.equals(sqlCommandType)) {
//格式化sql
sql = sql.replace("\n", "");
if (!sql.toLowerCase().contains(SQL_WHERE)) {
sql = sql.replace(" ", "");
log.info("刪除語句中沒有where條件,sql為:{}", sql);
throw new Exception("刪除語句中沒有where條件");
}
}
return invocation.proceed();
}
@Override
public Object plugin(Object o) {
return Plugin.wrap(o, this);
}
@Override
public void setProperties(Properties properties) {
}
}
再把插件註冊上(註冊插件還有其他的方法,後面會講到,這裏只是展示Bean注入的方式):
我們先看看配上插件后的執行效果:
可以看到日誌中輸出了:
刪除語句中沒有where條件,sql為:delete from order_info_ext
並拋出了異常。
這樣,我們的擴展表的數據就保住了。在測試階段,測試同學就一定能扯出來問題,瞟一眼日誌就明白了。
就算測試同學忘記測試了,在生產上也不會執行成功,拋出異常后還會有報警短信通知到相應的開發負責人,及時登上服務器去處理。
功能實現了,確實是非常的簡單。
我們再說回代碼,你說說看:當你拿到上面這段代碼后,最迷惑的地方是哪裡?
其中的邏輯是很簡單的了。 沒有什麼特別的地方,我想大多數人拿到這段代碼迷惑的地方在於這個地方吧:
這個 @Intercepts 裏面的 @Signature 裏面為什麼要這樣配置?
我們先看看 @Intercepts 註解:
裏面是個數組,可以配置多個 Signature。所以,其實這樣配置也是可以的:
關鍵的地方在於 @Signature 怎麼配置:
這個問題,我們放到下一節去討論。
mybatis插件的原理
上面一小節我們知道了對於開發插件而言,難點在於 @Signature 怎麼配置。
其實這也不能叫難點,只能說你不知道能配置什麼,比較茫然而已。這一小節就來回答這個問題。
要知道怎麼配置就必須要了解mybatis 這四大對象:Executor、ParameterHandler 、ResultSetHandler 、StatementHandler 。
官網上說:
MyBatis 允許你在映射語句執行過程中的某一點進行攔截調用。默認情況下,MyBatis 允許使用插件來攔截的方法調用包括:
Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed)
ParameterHandler (getParameterObject, setParameters)
ResultSetHandler (handleResultSets, handleOutputParameters)
StatementHandler (prepare, parameterize, batch, update, query)
那官網上說的這四大對象分別是拿來幹啥用的呢?
Executor:Mybatis 的執行器,用於進行增刪改查的操作。
ParameterHandler :參數處理器,用於處理 SQL 語句中的參數對象。
ResultSetHandler:結果處理器,用於處理 SQL 語句的返回結果。
StatementHandler :數據庫的處理對象,用於執行SQL語句
知道攔截的四大對象了,我們就可以先揭秘一下上面的這個註解配置的是啥了:
type 字段存放的是 class 對象,其取值範圍就是上面說的四大對象。
method 字段存放的是 class 對象的具體方法。
args 存放的是具體方法的參數。
看到這幾個參數你想到了什麼?有沒有條件反射式的想到反射?如果沒有的話你再咂摸咂摸,看看能不能品出一點反射的味道。
本文用攔截器的目的是判斷 delete 語句中是否有 where 條件,因此經過上面的分析,Executor 對象就能滿足我們的需求。
所以在本文示例中 @Signature 的 type 字段就是 Executor.class。
那 method 字段我們放哪個方法呢?放 delete 嗎?
這就得看看 Executor 對象的方法有哪些:
可以看到其中並沒有 delete 方法,和 SQL 執行相關的,看起來只有 query和 update。
但是,我們可以大膽猜測一下呀:delete 也是一種 update。
接着去求證一下就行:
可以看到 delete 方法確實是調用了 update 方法。
所以在本文案例中 @Signature 的 method 字段放的是 update 方法。
已經知道具體的方法了,那 args 放的就是方法的入參,所以這段配置就是這樣來的:
真的,我覺得這屬於手摸手教學系列了。經過這個簡單的案例,我希望大家能做到一通百通。
接下來帶大家看看我們常用的分頁插件 pageHelper 是怎麼做的吧。
其實你用腳指頭也能想到,分頁插件肯定是攔截的查詢方法,我們只是需要去驗證一下就可以。
引入 pageHelper 后可以看到 Interceptor 的多了兩個實現:
我們看一下 PageInterceptor 方法吧:
對吧,攔截了兩個 query 方法,一個參數是 4 個,一個參數是 6 個:
同時,在 intercept 的實現裏面有一部分是這樣寫的:
4 個參數和 6 個參數是做了單獨處理的,至於為什麼要這樣處理,至於為什麼要攔截兩個 query 方法,說起來又是一個很長的故事了。
詳細的可以看看這個鏈接: https://github.com/pagehelper/Mybatis-PageHelper/blob/master/wikis/zh/Interceptor.md
好了,還是那句話:如果要寫出好的 mybatis 插件,必須知道 @Signature 怎麼去配置。配置后能攔截哪些東西,你心裏應該是有點數的。
mybatis插件的原理
前面我們知道攔截器怎麼寫了,接下來簡單的分析一波原理。
前幾天我看到一個觀點是說看開源框架的源碼建議從 mybatis 看起。我是很贊成這個觀點的,確實是優雅,而容易看懂。能品出很多設計模式的使用。
一句話總結 mybatis插件的原理就是:動態代理加上責任鏈。
先看一下 Plugin 類的動態代理:
標號為 ① 的地方一看就知道,InvocationHandler,JDK 動態代理,沒啥說的。
標號為 ② 的地方是 wrap 方法,生成 Plugin 代理對象。
標號為 ③ 的地方是 invoker 方法,圈起來的目的是想說是在這裏判斷當前方法是否是需要被攔截的方法。如果是則用代理對象走攔截器邏輯,如果不是則用目標對象,走正常邏輯。
給大家看一下這個地方的 debug 效果:
一個平平無奇的 if 判斷,是攔截器的關鍵。為什麼這個地方多說了幾句呢?
因為其實這就是細節的地方。當面試的時候面試官問你:mybatis 是怎麼判斷是否需要攔截這個方法的時候你能答上來。說明你是真的看過源碼。
責任鏈是怎麼體現的呢?
就是這個地方: org.apache.ibatis.plugin.InterceptorChain
你看又學到一招,mybatis 裏面的設計模式還有責任鏈。
我們看一下 pluginAll 方法的調用方:
這個地方就體現出之前官網說的了:
插件是作用於這四大對象的:Executor、ParameterHandler 、ResultSetHandler 、StatementHandler 。
上面框起來的這四個框,就是插件調用的地方。
那麼插件在什麼時候被加載,或者說什麼是被註冊上的呢?
還是回到攔截鏈這個類上去:
pluginAll 方法我們已經知道有哪些地方調用了。這個方法裏面其實還有兩個考點。
第一就是 interceptor 這個 List 集合的定義,用了 final 修飾。所以要注意 final 修飾基本類型和引用類型的區別,被 final 修飾的引用類型變量內部的內容是可以發生變化的。
第二就是 getInterceptors 返回的是一個不可修改的 List 。所以,要對集合 interceptors 進行修改,只能通過 addInterceptor 方法進行元素添加,保證了這個集合是可控的。
所以,我們只需要知道哪裡調用了 addInterceptor 方法,哪裡就是插件被註冊的地方。
一個是 SqlSessionFactoryBean ,一個是 XMLConfigBuilder。
使用 XML 配置是這樣的:
熟悉 mybatis 的朋友們肯定知道,無非就是對於標籤的解析而已。
解析到 plugins 標籤,則進入 pluginElement 方法中,在這個方法裏面調用 addInterceptor:
本文沒有使用 XML 的形式配置,所以我們主要看一下 SqlSessionFactoryBean。
怎麼看呢?
不要盲目的走入源碼,加個斷點看調用鏈,跟着調用鏈去走就很清晰了。
在這個地方加一個斷點:
然後 debug 起來,你就可以看到整個調用鏈了:
然後我們根據上面的調用鏈,我們就可以找到源頭了:
在 MybatisAutoConfiguration 的構造方法裏面初始化了 interceptors。
而 interceptorsProvider.getIfAvailable() 方法也解釋了為什麼我們只需要在程序裏面這樣注入我們的攔截器就可以被找到了:
對 getIfAvailable 方法不熟悉的朋友可以去補一下這塊的知識,我這裏只是給大家看一下這個方法上的註釋:
當然,你這樣去注入的話有可能會不生效,你就會大罵一聲:寫的什麼垃圾玩意,配置上了也不對呀。
別著急呀,我還沒說完呢。你看看是不是有自定義的 SqlSessionFactory 在項目里。
看一下注入 SqlSessionFactory 的源碼上面的那個註解了嗎?
@ConditionalOnMissingBean ,看名字也知道了,當你的項目裏面沒有自定義的 SqlSessionFactory 的時候,才會由源碼給你注入,這個時候才會正在的註冊上插件:
如果你有自定義的 SqlSessionFactory,那麼請手動調用 factory.setPlugins 方法。
所以,總結一下插件的三種配置方法:
1.xml方式配置。
2.如果沒有自定義 SqlSessionFactory 直接 @Bean 注入攔截器即可。
3.如果有自定義 SqlSessionFactory 需要在自定義的地方手動調用 factory.setPlugins 方法。
其實我嘗試過第四種方法,在application.properties 裏面配置:
這種配置方式才是符合 SpringBoot 思想的配置。才是真正的絲滑,潤物無聲的絲滑。
可惜,我配置上后,點擊到對應的源碼地方一看:
它調用的是 getInterceptors 方法,我就知道肯定是有問題了:
果然,運行起來會報這樣的錯誤: Failed to bind properties under 'mybatis.configuration.interceptors' to java.util.List<org.apache.ibatis.plugin.Interceptor>
找了一圈原因,最後發現了這個 issue:
github.com/mybatis/spring-boot-starter/issues/180
這個“奇異博士”頭像的用戶提出了和我一樣的問題:
然後下面的回答是這樣的:
別問,問就是不支持。請使用 @Bean 的方式。
最後說一句(求關注)
點個“贊”吧,周更很累的,不要白嫖我,需要一點正反饋。
才疏學淺,難免會有紕漏,如果你發現了錯誤的地方,還請你指出來,我對其加以修改。
感謝您的閱讀,我堅持原創,十分歡迎並感謝您的關注。
我是 why,一個被代碼耽誤的文學創作者,不是大佬,但是喜歡分享,是一個又暖又有料的四川好男人。
歡迎關注我的微信公眾號:why技術。在這裏我會分享一些java技術相關的知識,用匠心敲代碼,對每一行代碼負責。偶爾也會荒腔走板的聊一聊生活,寫一寫書評、影評。感謝你的關注,願你我共同進步。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※網頁設計最專業,超強功能平台可客製化