系列博客,原文在筆者所維護的github上:,
點擊star加星不要吝嗇,星越多筆者越努力。
前言
For things I don’t know how to build, I don’t understand.
如果我不能親手搭建起來一個東西,那麼我就不能理解它。 — 美國物理學家理查德·費曼
在互聯網發達的今天,很多知識都可以從網絡上找到,但是網絡上的博客、文章的質量參差不齊,或者重點不明確,或者直接把別人的博客抄襲過來。這種狀況使得廣大的初學者們學習起來很困難,甚至誤入歧途,增加了學習曲線的陡峭程度。當然也有很多博主非常非常負責任,文章質量很高,只是連續度不夠,正看得過癮的時候,沒有後續章節了,無法形成知識體系。
初學者也可以選擇看一些教材或者理論書籍,但是,一個雞生蛋蛋生雞的問題出現了:如果你不懂,那麼看完了理論你還是不會懂;如果你懂了,那麼你就沒必要看理論。這也是很多教材或者理論書籍的缺憾。
筆者也看過吳恩達老師的課,理論知識講得由淺入深,還是非常清楚的,雖然代碼示例基本沒有,但仍然強烈建議大家去看。筆者的心得是:視頻可以事先緩存在手機中,利用一些時間片段就可以學習了。
社會上還有一些網課,在線講解深度學習的知識,筆者也參加了幾個團購,老師和助教一般都很負責任,最後可以回看錄像,下載PPT課件。這些課程一般偏重於工程項目,講解深度學習框架和工具的使用,即教大家如何使用工具建模、訓練等等,也是很有幫助的。但對於初學者來說,理解一個新概念可能需要前面很多個已有知識點的支撐,門檻過高,一下子就變得很沮喪。或者是知其然而不知其所以然,最後淪為調參工程師,職業發展受到了限制。
還是應了那句古話:授人以魚不如授人以漁。經歷了以上那些學習經歷,程序員出身的筆者迫切感覺到應該有一種新的學習體驗,在“做中學”,用寫代碼的方式把一些基礎的理論復現一遍,可以深刻理解其內涵,並能擴充其外延,使讀者得到舉一反三的泛化能力。
筆者總結了自身的學習經歷后,把深度學習的入門知識歸納成了9個步驟,簡稱為9步學習法:
- 基本概念
- 線性回歸
- 線性分類
- 非線性回歸
- 非線性分類
- 模型的推理與部署
- 深度神經網絡
- 卷積神經網絡
- 循環神經網絡
筆者看到過的很多書籍是直接從第7步起步的,其基本假設是讀者已經掌握了前面的知識。但是對於從零開始的初學者們,這種假設並不正確。
在後面的講解中,我們一般會使用如下方式進行:
- 提出問題:先提出一個與現實相關的假想問題,為了由淺入深,這些問題並不複雜,是實際的工程問題的簡化版本。
- 解決方案:用神經網絡的知識解決這些問題,從最簡單的模型開始,一步步到複雜的模型。
- 原理分析:使用基本的物理學概念或者數學工具,理解神經網絡的工作方式。
- 可視化理解:可視化是學習新知識的重要手段,由於我們使用了簡單案例,因此可以很方便地可視化。
原理分析和可視化理解也是本書的一個特點,試圖讓神經網絡是可以解釋的,而不是盲目地使用。
還有一個非常重要的地方,我們還有配套的Python代碼,除了一些必要的科學計算庫和繪圖庫,如NumPy和Matplotlib等,我們沒有使用任何已有的深度學習框架,而是帶領大家從零開始搭建自己的知識體系,從簡單到複雜,一步步理解深度學習中的眾多知識點。
對於沒有Python經驗的朋友來說,通過閱讀示例代碼,也可以起到幫助大家學習Python的作用,一舉兩得。隨着問題的難度加深,代碼也會增多,但是前後都有繼承關係的,最後的代碼會形成一個小的框架,筆者稱之為Mini-Framework,可以用搭積木的方式調用其中的函數來搭建深度學習的組件。
這些代碼都是由筆者親自編寫調試的,每章節都可以獨立運行,得到相關章節內所描述的結果,包括打印輸出和圖形輸出。
另外,為了便於理解,筆者繪製了大量的示意圖,數量是同類書籍的10倍以上。一圖頂萬字,相信大家會通過這些示意圖快速而深刻地理解筆者想要分享的知識點,使大家能夠從真正的“零”開始,對神經網絡、深度學習有基本的了解,並能動手實踐。
對於讀者的要求:
- 學過高等數學中的線性代數與微分
- 有編程基礎,可以不會Python語言,因為可以從示例代碼中學得
- 思考 + 動手的學習模式
可以幫助讀者達到的水平:
- 可以判斷哪些任務是機器學習可以實現的,哪些是科學幻想,不說外行話
- 深刻了解神經網絡和深度學習的基本理論
- 培養舉一反三的解決實際問題的能力
- 得到自學更複雜模型和更高級內容的能力
- 對於天資好的讀者,可以培養研發新模型的能力
符號約定
| 符號 | 含義 |
|---|---|
| \(x\) | 訓練用樣本值 |
| \(x_1\) | 第一個樣本或樣本的第一個特徵值,在上下文中會有說明 |
| \(x_{12},x_{1,2}\) | 第1個樣本的第2個特徵值 |
| \(X\) | 訓練用多樣本矩陣 |
| \(y\) | 訓練用樣本標籤值 |
| \(y_1\) | 第一個樣本的標籤值 |
| \(Y\) | 訓練用多樣本標籤矩陣 |
| \(z\) | 線性運算的結果值 |
| \(Z\) | 線性運算的結果矩陣 |
| \(Z1\) | 第一層網絡的線性運算結果矩陣 |
| \(\sigma\) | 激活函數 |
| \(a\) | 激活函數結果值 |
| \(A\) | 激活函數結果矩陣 |
| \(A1\) | 第一層網絡的激活函數結果矩陣 |
| \(w\) | 權重參數值 |
| \(w_{12},w_{1,2}\) | 權重參數矩陣中的第1行第2列的權重值 |
| \(w1_{12},w1_{1,2}\) | 第一層網絡的權重參數矩陣中的第1行第2列的權重值 |
| \(W\) | 權重參數矩陣 |
| \(W1\) | 第一層網絡的權重參數矩陣 |
| \(b\) | 偏移參數值 |
| \(b_1\) | 偏移參數矩陣中的第1個偏移值 |
| \(b2_1\) | 第二層網絡的偏移參數矩陣中的第1個偏移值 |
| \(B\) | 偏移參數矩陣(向量) |
| \(B1\) | 第一層網絡的偏移參數矩陣(向量) |
| \(X^T\) | X的轉置矩陣 |
| \(X^{-1}\) | X的逆矩陣 |
| \(loss,loss(w,b)\) | 單樣本誤差函數 |
| \(J, J(w,b)\) | 多樣本損失函數 |
1.3 神經網絡的基本工作原理簡介
1.3.1 神經元細胞的數學模型
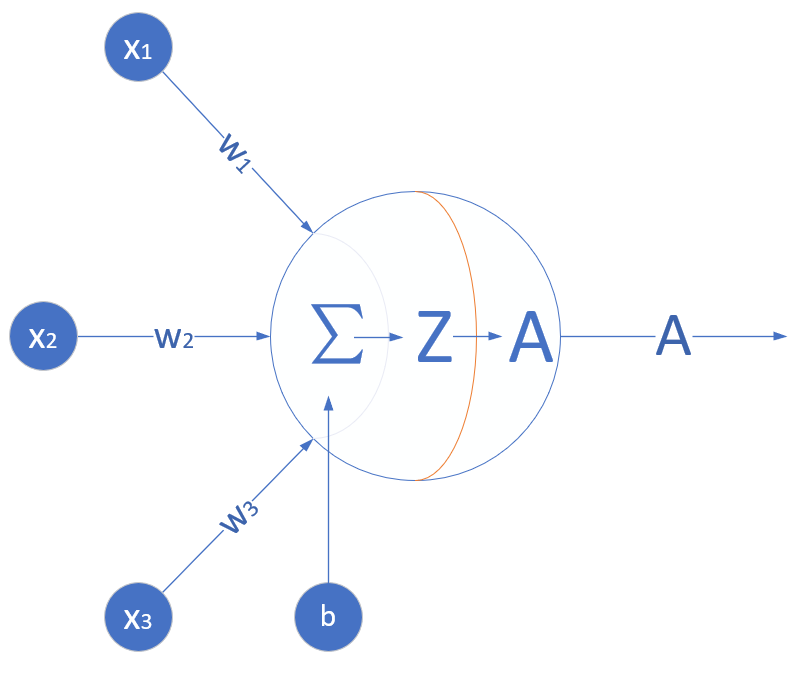
神經網絡由基本的神經元組成,圖1-13就是一個神經元的數學/計算模型,便於我們用程序來實現。
圖1-13 神經元計算模型
輸入 input
(x1,x2,x3) 是外界輸入信號,一般是一個訓練數據樣本的多個屬性,比如,我們要預測一套房子的價格,那麼在房屋價格數據樣本中,x1可能代表了面積,x2可能代表地理位置,x3可能朝向。另外一個例子是,假設(x1,x2,x3)分別代表了(紅,綠,藍)三種顏色,而此神經元用於識別輸入的信號是暖色還是冷色。
權重 weights
(w1,w2,w3) 是每個輸入信號的權重值,以上面的 (x1,x2,x3) 的例子來說,x1的權重可能是0.92,x2的權重可能是0.2,x3的權重可能是0.03。當然權重值相加之後可以不是1。
偏移 bias
還有個b是怎麼來的?一般的書或者博客上會告訴你那是因為\(y=wx+b\),b是偏移值,使得直線能夠沿Y軸上下移動。這是用結果來解釋原因,並非b存在的真實原因。從生物學上解釋,在腦神經細胞中,一定是輸入信號的電平/電流大於某個臨界值時,神經元細胞才會處於興奮狀態,這個b實際就是那個臨界值。亦即當:
\[w_1 \cdot x_1 + w_2 \cdot x_2 + w_3 \cdot x_3 >= t\]
時,該神經元細胞才會興奮。我們把t挪到等式左側來,變成\((-t)\),然後把它寫成b,變成了:
\[w_1 \cdot x_1 + w_2 \cdot x_2 + w_3 \cdot x_3 + b >= 0\]
於是b誕生了!
求和計算 sum
\[ \begin{aligned} Z &= w_1 \cdot x_1 + w_2 \cdot x_2 + w_3 \cdot x_3 + b \\ &= \sum_{i=1}^m(w_i \cdot x_i) + b \end{aligned} \]
在上面的例子中m=3。我們把\(w_i \cdot x_i\)變成矩陣運算的話,就變成了:
\[Z = W \cdot X + b\]
激活函數 activation
求和之後,神經細胞已經處於興奮狀態了,已經決定要向下一個神經元傳遞信號了,但是要傳遞多強烈的信號,要由激活函數來確定:
\[A=\sigma{(Z)}\]
如果激活函數是一個階躍信號的話,會像繼電器開合一樣咔咔的開啟和閉合,在生物體中是不可能有這種裝置的,而是一個漸漸變化的過程。所以一般激活函數都是有一個漸變的過程,也就是說是個曲線,如圖1-14所示。
圖1-14 激活函數圖像
至此,一個神經元的工作過程就在電光火石般的一瞬間結束了。
小結
- 一個神經元可以有多個輸入。
- 一個神經元只能有一個輸出,這個輸出可以同時輸入給多個神經元。
- 一個神經元的w的數量和輸入的數量一致。
- 一個神經元只有一個b。
- w和b有人為的初始值,在訓練過程中被不斷修改。
- 激活函數不是必須有的,亦即A可以等於Z。
- 一層神經網絡中的所有神經元的激活函數必須一致。
1.3.2 神經網絡的訓練過程
單層神經網絡模型
這是一個單層的神經網絡,有m個輸入 (這裏m=3),有n個輸出 (這裏n=2)。在神經網絡中,\(b\) 到每個神經元的權值來表示實際的偏移值,亦即\((b_1,b_2)\),這樣便於矩陣運算。也有些人把 \(b\) 寫成\(x_0\),其實是同一個效果,即把偏移值看做是神經元的一個輸入。
- \((x_1,x_2,x_3)\)是一個樣本數據的三個特徵值
- \((w_{11},w_{21},w_{31})\)是\((x_1,x_2,x_3)\)到\(n1\)的權重
- \((w_{12},w_{22},w_{32})\)是\((x_1,x_2,x_3)\)到\(n2\)的權重
- \(b_1\)是\(n1\)的偏移
- \(b_2\)是\(n2\)的偏移
圖1-15 單層神經網絡模型
從圖1-15大家可以看到,同一個特徵 \(x_1\),對於\(n1、n2\)來說,權重是不相同的,因為\(n1、n2\)是兩個神經元,它們完成不同的任務(特徵識別)。我們假設\(x_1,x_2,x_3\)分別代表紅綠藍三種顏色,而 \(n1,n2\) 分別用於識別暖色和冷色,那麼 \(x_1\) 到 \(n1\) 的權重,肯定要大於 \(x_1\) 到 \(n2\) 的權重,因為\(x_1\)代表紅色,是暖色。
而對於\(n1\)來說,\(x_1,x_2,x_3\)輸入的權重也是不相同的,因為它要對不同特徵有選擇地接納。如同上面的例子,\(n1\) 對於代表紅色的 \(x_1\),肯定是特別重視,權重值較高;而對於代表藍色的 \(x_3\),盡量把權重值降低,才能有正確的輸出。
訓練流程
從真正的“零”開始學習神經網絡時,我沒有看到過任何一個流程圖來講述訓練過程,大神們寫書或者博客時都忽略了這一點,圖1-16是一個簡單的流程圖。
圖1-16 神經網絡訓練流程圖
前提條件
- 首先是我們已經有了訓練數據;
- 我們已經根據數據的規模、領域,建立了神經網絡的基本結構,比如有幾層,每一層有幾個神經元;
- 定義好損失函數來合理地計算誤差。
步驟
假設我們有表1-1所示的訓練數據樣本。
表1-1 訓練樣本示例
| Id | x1 | x2 | x3 | Y |
|---|---|---|---|---|
| 1 | 0.5 | 1.4 | 2.7 | 3 |
| 2 | 0.4 | 1.3 | 2.5 | 5 |
| 3 | 0.1 | 1.5 | 2.3 | 9 |
| 4 | 0.5 | 1.7 | 2.9 | 1 |
其中,x1,x2,x3是每一個樣本數據的三個特徵值,Y是樣本的真實結果值:
- 隨機初始化權重矩陣,可以根據高斯分佈或者正態分佈等來初始化。這一步可以叫做“猜”,但不是瞎猜;
- 拿一個或一批數據作為輸入,帶入權重矩陣中計算,再通過激活函數傳入下一層,最終得到預測值。在本例中,我們先用Id-1的數據輸入到矩陣中,得到一個A值,假設A=5;
- 拿到Id-1樣本的真實值Y=3;
- 計算損失,假設用均方差函數 \(Loss = (A-Y)^2=(5-3)^2=4\);
- 根據一些神奇的數學公式(反向微分),把Loss=4這個值用大喇叭喊話,告訴在前面計算的步驟中,影響A=5這個值的每一個權重矩陣,然後對這些權重矩陣中的值做一個微小的修改(當然是向著好的方向修改,這一點可以用數學家的名譽來保證);
- 用Id-2樣本作為輸入再次訓練(goto 2);
- 這樣不斷地迭代下去,直到以下一個或幾個條件滿足就停止訓練:損失函數值非常小;準確度滿足了要求;迭代到了指定的次數。
訓練完成后,我們會把這個神經網絡中的結構和權重矩陣的值導出來,形成一個計算圖(就是矩陣運算加上激活函數)模型,然後嵌入到任何可以識別/調用這個模型的應用程序中,根據輸入的值進行運算,輸出預測值。
1.3.3 神經網絡中的矩陣運算
圖1-17是一個兩層的神經網絡,包含隱藏層和輸出層,輸入層不算做一層。
圖1-17 神經網絡中的各種符號約定
\[ z1_1 = x_1 \cdot w1_{1,1}+ x_2 \cdot w1_{2,1}+b1_1 \]
\[ z1_2 = x_1 \cdot w1_{1,2}+ x_2 \cdot w1_{2,2}+b1_2 \]
\[ z1_3 = x_1 \cdot w1_{1,3}+ x_2 \cdot w1_{2,3}+b1_3 \]
變成矩陣運算:
\[ z1_1= \begin{pmatrix} x_1 & x_2 \end{pmatrix} \begin{pmatrix} w1_{1,1} \\ w1_{2,1} \end{pmatrix} +b1_1 \]
\[ z1_2= \begin{pmatrix} x_1 & x_2 \end{pmatrix} \begin{pmatrix} w1_{1,2} \\ w1_{2,2} \end{pmatrix} +b1_2 \]
\[ z1_3= \begin{pmatrix} x_1 & x_2 \end{pmatrix} \begin{pmatrix} w1_{1,3} \\ w1_{2,3} \end{pmatrix} +b1_3 \]
再變成大矩陣:
\[ Z1 = \begin{pmatrix} x_1 & x_2 \end{pmatrix} \begin{pmatrix} w1_{1,1}&w1_{1,2}&w1_{1,3} \\ w1_{2,1}&w1_{2,2}&w1_{2,3} \\ \end{pmatrix} +\begin{pmatrix} b1_1 & b1_2 & b1_3 \end{pmatrix} \]
最後變成矩陣符號:
\[Z1 = X \cdot W1 + B1\]
然後是激活函數運算:
\[A1=a(Z1)\]
同理可得:
\[Z2 = A1 \cdot W2 + B2\]
注意:損失函數不是前向計算的一部分。
1.3.4 神經網絡的主要功能
回歸(Regression)或者叫做擬合(Fitting)
單層的神經網絡能夠模擬一條二維平面上的直線,從而可以完成線性分割任務。而理論證明,兩層神經網絡可以無限逼近任意連續函數。圖1-18所示就是一個兩層神經網絡擬合複雜曲線的實例。
圖1-18 回歸/擬合示意圖
所謂回歸或者擬合,其實就是給出x值輸出y值的過程,並且讓y值與樣本數據形成的曲線的距離盡量小,可以理解為是對樣本數據的一種骨架式的抽象。
以圖1-18為例,藍色的點是樣本點,從中可以大致地看出一個輪廓或骨架,而紅色的點所連成的線就是神經網絡的學習結果,它可以“穿過”樣本點群形成中心線,盡量讓所有的樣本點到中心線的距離的和最近。
分類(Classification)
如圖1-19,二維平面中有兩類點,紅色的和藍色的,用一條直線肯定不能把兩者分開了。
圖1-19 分類示意圖
我們使用一個兩層的神經網絡可以得到一個非常近似的結果,使得分類誤差在滿意的範圍之內。圖1-19中那條淡藍色的曲線,本來並不存在,是通過神經網絡訓練出來的分界線,可以比較完美地把兩類樣本分開,所以分類可以理解為是對兩類或多類樣本數據的邊界的抽象。
圖1-18和圖1-19的曲線形態實際上是一個真實的函數在[0,1]區間內的形狀,其原型是:
\[y=0.4x^2 + 0.3xsin(15x) + 0.01cos(50x)-0.3\]
這麼複雜的函數,一個兩層的神經網絡是如何做到的呢?其實從輸入層到隱藏層的矩陣計算,就是對輸入數據進行了空間變換,使其可以被線性可分,然後在輸出層畫出一個分界線。而訓練的過程,就是確定那個空間變換矩陣的過程。因此,多層神經網絡的本質就是對複雜函數的擬合。我們可以在後面的試驗中來學習如何擬合上述的複雜函數的。
神經網絡的訓練結果,是一大堆的權重組成的數組(近似解),並不能得到上面那種精確的數學表達式(數學解析解)。
1.3.5 為什麼需要激活函數
生理學上的例子
人體骨關節是動物界里最複雜的生理結構,一共有8個重要的大關節:肩關節、
肘關節、腕關節、髖關節、膝關節、踝關節、頸關節、腰關節。
人的臂骨,腿骨等,都是一根直線,人體直立時,也是一根直線。但是人在骨關節和肌肉組織的配合下,可以做很多複雜的動作,原因就是關節本身不是線性結構,而是一個在有限範圍內可以任意活動的結構,有一定的柔韌性。
比如肘關節,可以完成小臂在一個二維平面上的活動。加上肩關節,就可以完成胳膊在三維空間的活動。再加上其它關節,就可以擴展胳膊活動的三維空間的範圍。
用表1-2來對比人體運動組織和神經網絡組織。
表1-2 人體運動組織和神經網絡組織的對比
| 人體運動組織 | 神經網絡組織 |
|---|---|
| 支撐骨骼 | 網絡層次 |
| 關節 | 激活函數 |
| 肌肉韌帶 | 權重參數 |
| 學習各種運動的動作 | 前向+反向訓練過程 |
激活函數就相當於關節。
激活函數的作用
看以下的例子:
\[Z1=X \cdot W1 + B1\]
\[Z2 = Z1 \cdot W2 + B2\]
\[Z3 = Z2 \cdot W3 + B3\]
展開:
\[ \begin{aligned} Z3&=Z2 \cdot W3 + B3 \\ &=(Z1 \cdot W2 + B2) \cdot W3 + B3 \\ &=((X \cdot W1 + B1) \cdot W2 + B2) \cdot W3 + B3 \\ &=X \cdot (W1\cdot W2 \cdot W3) + (B1 \cdot W2 \cdot W3+B2 \cdot W2+B3) \\ &=X \cdot W+B \end{aligned} \]
\(Z1,Z2,Z3\)分別代表三層神經網絡的計算結果。最後可以看到,不管有多少層,總可以歸結到\(XW+B\)的形式,這和單層神經網絡沒有區別。
如果我們不運用激活函數的話,則輸出信號將僅僅是一個簡單的線性函數。線性函數一個一級多項式。線性方程是很容易解決的,但是它們的複雜性有限,並且從數據中學習複雜函數映射的能力更小。一個沒有激活函數的神經網絡將只不過是一個線性回歸模型罷了,不能解決現實世界中的大多數非線性問題。
沒有激活函數,我們的神經網絡將無法學習和模擬其他複雜類型的數據,例如圖像、視頻、音頻、語音等。這就是為什麼我們要使用人工神經網絡技術,諸如深度學習,來理解一些複雜的事情,一些相互之間具有很多隱藏層的非線性問題。
圖1-20 從簡單到複雜的擬合
圖1-20展示了幾種擬合方式,最左側的是線性擬合,中間的是分段線性擬合,右側的是曲線擬合,只有當使用激活函數時,才能做到完美的曲線擬合。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※專營大陸空運台灣貨物推薦
※台灣空運大陸一條龍服務