1. ArrayList 和Vector 的區別
ArrayList和Vector底層實現原理都是一樣得,都是使用數組方式存儲數據
Vector是線程安全的,但是性能比ArrayList要低。
ArrayList,Vector主要區別為以下幾點:
(1):Vector是線程安全的,源碼中有很多的synchronized可以看出,而ArrayList不是。導致Vector效率無法和ArrayList相比;
(2):ArrayList和Vector都採用線性連續存儲空間,當存儲空間不足的時候,ArrayList默認增加為原來的50%,Vector默認增加為原來的一倍;
(3):Vector可以設置capacityIncrement,而ArrayList不可以,從字面理解就是capacity容量,Increment增加,容量增長的參數。
2.說說ArrayList,Vector, LinkedList 的存儲性能和特性
ArrayList採用的數組形式來保存對象,這種方法將對象放在連續的位置中,所以最大的缺點就是插入和刪除的時候比較麻煩,查找比較快;
Vector使用了sychronized方法(線程安全),所以在性能上比ArrayList要差些.
LinkedList採用的鏈表將對象存放在獨立的空間中,而且在每個空間中還保存下一個鏈表的索引。使用雙向鏈表方式存儲數據,按序號索引數據需要前向或後向遍曆數據,所以索引數據慢,是插入數據時只需要記錄前後項即可,所以插入的速度快。
3.快速失敗(fail-fast) 和安全失敗(fail-safe) 的區別是什麼?
1.快速失敗
原理是:
迭代器在遍歷時直接訪問集合中的內容,並且在遍歷過程中使用一個modCount變量。集合在被遍歷期間如果內容發生變化,就會改變modCount的值。每當迭代器使用hasNext()或next()遍歷下一個元素之前,都會先檢查modCount變量是否為expectmodCount值。如果是的話就返回遍歷;否則拋出異常,終止遍歷。
查看ArrayList源碼,在next方法執行的時候,會執行checkForComodification()方法。
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1 ;
return (E) elementData[lastRet = i];
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
這裏異常的拋出條件是modCount != expectedModCount這個條件。如果集合發生變化時修改modCount值剛好又設置為了expectedModCount值,則異常不會拋出。因此,不能依賴於這個異常是否拋出而進行併發操作,這個異常只建議用於檢測併發修改的bug。
2.安全失敗
採用安全失敗機制的集合容器,在遍歷時不是直接在集合上訪問的,而是先複製原有集合內容,在拷貝的集合上進行遍歷。
原理:
由於迭代時是對原集合的拷貝進行遍歷,所以在遍歷過程中對原集合所做的修改並不能被迭代器檢測到,所以不會觸發ConcurrentModificationException,例如CopyOnWriteArrayList。
缺點:
基於拷貝內容的優點是避免了ConcurrentModificationException,但同樣地,迭代器並不能訪問到修改後的內容。即:迭代器遍歷的是開始遍歷那一刻拿到的集合拷貝,在遍歷期間原集合發生的修改迭代器是不知道的。
場景:
Java.util.concurrent包下的容器都是安全失敗的,可以在多線程下併發使用,併發修改。
快速失敗和安全失敗都是對迭代器而言的。快速失敗:當在迭代一個集合時,如果有另外一個線程在修改這個集合,就會跑出ConcurrentModificationException,java.util下都是快速失敗。安全失敗:在迭代時候會在集合二層做一個拷貝,所以在修改集合上層元素不會影響下層。在java.util.concurrent包下都是安全失敗。
4.HashMap 的數據結構
HashMap的主幹類是一個Entry數組(jdk1.7) ,每個Entry都包含有一個鍵值隊(key-value).
我們可以看一下源碼:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry <K,V> next; // 存儲指向下一個Entry的引用,單鏈表結構
int hash; // 對key的hashcode值進行hash運算後得到的值,存儲在Entry,避免重複計算
/**
* Creates new entry.
*/
Entry( int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
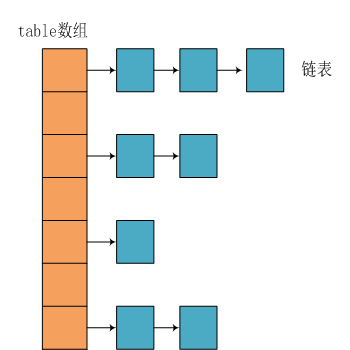
所以,HashMap的整體結果如下
簡單來說,HashMap由數組+鏈表組成的,數組是HashMap的主體,鏈表則是主要為了解決哈希衝突而存在的,如果定位到的數組位置不含鏈表(當前entry的next指向null ),那麼對於查找,添加等操作很快,僅需一次尋址即可;如果定位到的數組包含鏈表,對於添加操作,其時間複雜度為O(n),首先遍歷鏈表,存在即覆蓋,否則新增;對於查找操作來講,仍需遍歷鏈表,然後通過key對象的equals方法逐一比對查找。所以,性能考慮,HashMap中的鏈表出現越少,性能才會越好。
5.HashMap 的工作原理
HashMap基於hashing原理,我們通過put()和get()方法存儲和獲取對象,當我們將鍵值對傳遞給put()方法時,它調用鍵對象的hashCode()方法來計算hashcode,讓後找到bucket位置來存儲值對象。當獲取對象時,通過鍵對象的equals()方法找到正確的鍵值對,然後返回對象。
我們看一下put()源碼:
public V put(K key, V value) {
// 當key為null,調用putForNullKey方法,保存null與table第一個位置中,這是HashMap允許為null的原因
if (key == null )
return putForNullKey( value);
// 計算key的hash值
int hash = hash(key.hashCode()); // 計算key hash值在table數組中的位置
int i = indexFor(hash, table.length); // 從i出開始迭代e,找到key保存的位置
for (Entry<K, V> e = table[i]; e != null ; e = e.next) {
Object k;
// 判斷該條鏈上是否有hash值相同的(key相同)
// 若存在相同,則直接覆蓋value,返回舊value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value; // 舊值=新值
e.value = value;
e.recordAccess( this );
return oldValue; // 返回舊值
}
}
// 修改次數增加1
modCount++ ;
// 將key、value添加至i位置處
addEntry(hash, key, value, i);
return null ;
}
通過源碼我們可以清晰看到HashMap保存數據的過程為:首先判斷key是否為null,若為null,則直接調用putForNullKey方法。若不為空則先計算key的hash值,然後根據hash值搜索在table數組中的索引位置,如果table數組在該位置處有元素,則通過比較是否存在相同的key,若存在則覆蓋原來key的value,否則將該元素保存在鏈頭(最先保存的元素放在鏈尾)。若table在該處沒有元素,則直接保存。
get()源碼:
public V get(Object key) {
// 若為null,調用getForNullKey方法返回相對應的value
if (key == null )
return getForNullKey();
// 根據該key的hashCode值計算它的hash碼
int hash = hash(key.hashCode());
// 取出table數組中指定索引處的值
for (Entry<K, V> e = table[indexFor(hash, table.length)]; e != null ; e = e .next) {
Object k;
// 若搜索的key與查找的key相同,則返回相對應的value
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e .value;
}
return null ;
}
在這裡能夠根據key快速的取到value除了和HashMap的數據結構密不可分外,還和Entry有莫大的關係,在前面就提到過,HashMap在存儲過程中並沒有將key,value分開來存儲,而是當做一個整體key-value來處理的,這個整體就是Entry對象。同時value也只相當於key的附屬而已。在存儲的過程中,系統根據key的hashcode來決定Entry在table數組中的存儲位置,在取的過程中同樣根據key的hashcode取出相對應的Entry對象。
6.Hashmap 什麼時候進行擴容呢?
這裏我們再來複習put的流程:當我們想一個HashMap中添加一對key-value時,系統首先會計算key的hash值,然後根據hash值確認在table中存儲的位置。若該位置沒有元素,則直接插入。否則迭代該處元素鏈表並依此比較其key的hash值。如果兩個hash值相等且key值相等(e.hash == hash && ((k = e.key) == key || key.equals(k))),則用新的Entry的value覆蓋原來節點的value。如果兩個hash值相等但key值不等,則將該節點插入該鏈表的鏈頭。具體的實現過程見addEntry方法,如下:
void addEntry( int hash, K key, V value, int bucketIndex) {
// 獲取bucketIndex處的Entry
Entry<K, V> e = table[bucketIndex];
// 將新創建的Entry放入bucketIndex索引處,並讓新的Entry指向原來的Entry
table[bucketIndex] = new Entry<K, V> (hash, key, value, e);
// 若HashMap中元素的個數超過極限了,則容量擴大兩倍
if ( size++ >= threshold)
resize( 2 * table.length);
}
這個方法中有兩點需要注意:
一是鏈的產生。這是一個非常優雅的設計。系統總是將新的Entry對象添加到bucketIndex處。如果bucketIndex處已經有了對象,那麼新添加的Entry對象將指向原有的Entry對象,形成一條Entry鏈,但是若bucketIndex處沒有Entry對象,也就是e==null,那麼新添加的Entry對象指向null ,也就不會產生Entry鏈了。
二、擴容問題。
隨著HashMap中元素的數量越來越多,發生碰撞的概率就越來越大,所產生的鏈表長度就會越來越長,這樣勢必會影響HashMap的速度,為了保證HashMap的效率,系統必須要在某個臨界點進行擴容處理。該臨界點在當HashMap中元素的數量等於table數組長度*加載因子。但是擴容是一個非常耗時的過程,因為它需要重新計算這些數據在新table數組中的位置並進行複製處理。所以如果我們已經預知HashMap中元素的個數,那麼預設元素的個數能夠有效的提高HashMap的性能。
7.HashSet怎樣保證元素不重複
都知道HashSet中不能存放重複的元素,有時候可以用來做去重操作。但是其內部是怎麼保證元素不重複的呢?
打開HashSet源碼,發現其內部維護一個HashMap:
public class HashSet<E>
extends AbstractSet <E>
implements Set <E> , Cloneable, java.io.Serializable
{
static final long serialVersionUID = - 5024744406713321676L ;
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<> ();
}
...
}
HashSet的構造方法其實就是在內部實例化了一個HashMap對象,其中還會看到一個static final的PRESENT變量;
想知道為什麼HashSet不能存放重複對象,那麼第一步看看它的add方法進行的判重,代碼如下
public boolean add(E e) {
return map.put(e, PRESENT)== null ;
}
其實看add()方法,這時候答案已經出來了:HashMap的key是不能重複的,而這裏HashSet的元素又是作為了map的key,當然也不能重複了。
順便看一下HashMap裏面又是怎麼保證key不重複的,代碼如下:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null )
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e ! = null ; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess( this );
return oldValue;
}
}
modCount ++ ;
addEntry(hash, key, value, i);
return null ;
}
其中最關鍵的一句:
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
調用了對象的hashCode和equals方法進行判斷,所以又得到一個結論:若要將對象存放到HashSet中並保證對像不重複,應根據實際情況將對象的hashCode方法和equals方法進行重寫
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包”嚨底家”
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※小三通海運與一般國際貿易有何不同?
※小三通快遞通關作業有哪些?