Java性能分析神器1–VisualVM Launcher
VisualVM
當你日復一日敲代碼的時候,當你把各種各樣的框架集成到一起的時候,看着大功告成成功運行的日誌,有沒有那麼一絲絲迷茫和惆悵:這TM起的是什麼玩意?每一行日誌背後代表的是什麼東西??他為什麼就能跑起來了呢????
這種時候不要慌,給大家推薦一款功能強大的插件:VisualVM Launcher。(eclipse就叫 )。這個插件需要和客戶端配合使用 。
VisualVM是集成了命令行JDK工具和輕量級分析功能的可視化工具。JVM提供了一些常用的jdk命令行工具:
- jstat(JVM Statistics Monitoring Tool):用於收集Hotspot虛擬機各方面的運行數據(查看虛擬機各雲心狀態信息),显示本地或遠程虛擬機進程中的類裝載,內存,垃圾收集, JIT編譯等運行數據。
- jps(JVM Process Status Tool):显示指定系統內所有的HotSpot虛擬機進程(查看虛擬機進程信息),可用於查詢正在運行的虛擬機進程, 同時可選擇性的显示虛擬機執行主類, 即執行main函數的類, 以及進程的本地虛擬機
ID(Local Virtual Machine Identifier 簡稱LVMID)(對於本地虛擬機進程來說, 進程的本地虛擬機ID與操作系統的進程ID是一致的) - jinfo(Configuration Info for Java):显示虛擬機配置信息(查看虛擬機配置參數信息),可用於查看和調整虛擬機的配置參數.
- jmap(JVM Memory Map):生成虛擬機的內存轉儲快照, 生成heapdump文件(生成虛擬機內存轉儲快照),可用於獲取heapdump文件, 且可以查詢finalize執行隊列, Java堆與永久代的一些信息。
- jhat(JVM Heap Dump Browser):用於分析heapdump文件, 它會建立一個HTTP/HTML服務器, 讓用戶在瀏覽器上查看分析結果(分析虛擬機轉儲快照信息),jhat命令與jmap命令搭配使用, 用於分析jmap生成的堆轉儲快照, jhat內置了一個微型的HTTP/HTML服務器, 生成dump文件的分析結果后, 可以在瀏覽器中查看。
- jstack(JVM Stack Trace):显示虛擬機的線程快照(虛擬機堆棧跟蹤),用於生成虛擬機當前時刻的線程快照。 線程快照指的是當前虛擬機內的每一條線程正在執行的方法堆棧的集合, 生成線程快照的作用是, 可用於定位線程出現長時間停頓的原因, 如線程間死鎖, 死循環, 請求外部資源導致的長時間等待等問題, 當線程出現停頓時 就可以用jstack各個線程調用的堆棧情況
這些工具功能強大,可以很方便的查看jvm內存分配,內存大小,裝載類總數,線程總數等。有了這些信息,就可以很快的進程診斷,性能調優辣。
安裝VisualVM和VisualVM Launcher
1. Idea安裝VisualVM Launcher插件
Preferences –> Plugins –> 搜索VisualVM Launcher,安裝重啟即可
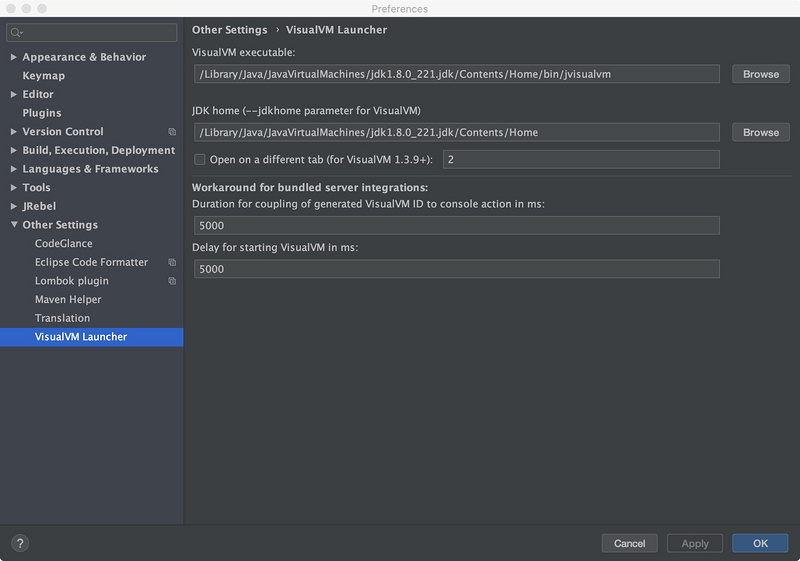
2. 配置Idea VisualVM Launcher插件
Preferences –> other settings -> VisualVM Launcher –> 輸入VisualVM executable 和 JDK home即可
3. 配置完之後的idea頁面
4. 安裝VisualVM客戶端
–> 選擇對應的系統安裝包 –> 對應安裝,安裝完成后打開是這樣的頁面:
VisualVM和java命令行工具
1. jmap+jhat內存快照與分析:Heap Dump
-
HeapDump又叫做堆存儲文件,指一個Java進程在某個時間點的內存快照。Heap Dump在觸發內存快照的時候會保存此刻的java對象和類的信息。通常在寫heap Dump文件前會觸發一次FullGC,所以heap dump文件里保存的都是FullCG后留下的對象信息。
-
jmap進行內存快照方式:
jmap -dump:format=b,file=<filename.hprof> <pid> -
jhat進行內存快照分析:
jhat <heap dump file>- 使用了jhat命令,就啟動了一個http服務,端口是7000,即http://localhost:7000/,就可以在瀏覽器里分析
-
VisualVM進行內存快照方式:
- 在“應用程序”窗口中右鍵單擊應用程序節點,然後選擇“堆 Dump”。
- 在“應用程序”窗口中雙擊應用程序節點以打開應用程序標籤,然後在“監視”標籤中單擊“堆 Dump”。
-
VisualVM快照頁面,也可以右鍵保存此時的快照:
-
想要打開保存好的java快照:
- 單擊“堆 Dump”工具欄中的“類”,以查看活動類和對應實例的列表。
- 雙擊某個類名打開“實例”視圖,以查看實例列表。
- 從列表中選擇某個實例,以查看對該實例的引用。
2. jinfo:显示虛擬機配置信息(查看虛擬機配置參數信息)
-
虛擬機配置信息:JVM的啟動參數
-
jinfo進行查看虛擬機配置信息查詢(jinfo -help查看更多)
jinfo <pid> -
Visual VM查看虛擬機配置信息,直接在應用程序打開,就可以看到JVM參數 和 系統屬性:
-
一些常見的虛擬機配置參數:
- -Xms:初始堆大小。如:-Xms256m
- -Xmx:最大堆大小。如:-Xmx512m
- -Xmn:新生代大小。通常為 Xmx 的 1/3 或 1/4。
- -Xss:為每個線程分配的內存大小,JDK1.5+ 每個線程堆棧大小為 1M,一般來說如果棧不是很深的話, 1M 是絕對夠用了的。
- -XX:NewRatio:新生代與老年代的比例,如 –XX:NewRatio=2,則新生代占整個堆空間的1/3,老年代佔2/3
- -XX:SurvivorRatio:新生代中 Eden 與 Survivor 的比值。默認值為 8。即 Eden 佔新生代空間的 8/10,另外兩個 Survivor 各占 1/10
- -XX:PermSize:永久代(方法區)的初始大小
- PermSize永久代的概念在jdk1.8中已經不存在了,取而代之的是metaspace元空間,當認為執行永久代的初始大小以及最大值是jvm會給出如此下提示:
- Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=30m; support was removed in 8.0
- Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=30m; support was removed in 8.0
- PermSize永久代的概念在jdk1.8中已經不存在了,取而代之的是metaspace元空間,當認為執行永久代的初始大小以及最大值是jvm會給出如此下提示:
- -XX:MaxPermSize:永久代(方法區)的最大值
- -XX:+PrintGCDetails:打印 GC 信息
- -XX:+HeapDumpOnOutOfMemoryError:讓虛擬機在發生內存溢出時 Dump 出當前的內存堆轉儲快照,以便分析用
3. jps查看虛擬機進程信息
-
用來查詢正在運行的虛擬機進程
-
jps命令,:
jps
-
VisualVM查看正在運行的虛擬機進程:
4. jstack显示虛擬機的線程快照
-
生成虛擬機當前時刻的線程快照,用來查找運行時死鎖,死循環的原因
-
jstack命令,
jstack <pid>
-
VisualVM生成虛擬機線程快照方式:
- 在“應用程序”窗口中右鍵單擊應用程序節點,然後選擇“線程 Dump”。
- 在“應用程序”窗口中雙擊應用程序節點以打開應用程序標籤,然後在“線程”標籤中單擊“線程 Dump”。
-
VisualVM線程快照頁面,也可以右鍵保存快照:
5. jstat收集Hotspot虛擬機各方面的運行數據
-
運行數據:對Java應用程序的資源和性能進行實時監控,主要包括GC情況和Heap Size資源使用情況。
-
jstat進行資源與性能監控,:
jstat -gc <pid>
-
VisualVM進行程序資源的實時監控:
VisualVM也提供了一些其他功能
此外,VisualVM也提供很多插件,有各樣的功能,我就不多介紹了
這篇文章,介紹了VisualVM的作用和用法,下面會寫一篇姊妹篇 帶上代碼,去分析當系統出現死鎖或者循環等異常時,內存、線程和CPU在做什麼。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!