1. 部分基本類型
go中的類型與c的相似,常用類型有一個特例:byte類型,即字節類型,長度為,默認值是0;
1 bytes = [5]btye{'h', 'e', 'l', 'l', 'o'}
變量bytes的類型是[5]byte,一個由5個字節組成的數組。它的內存表示就是連起來的5個字節,就像C的數組。
1.1 字符串
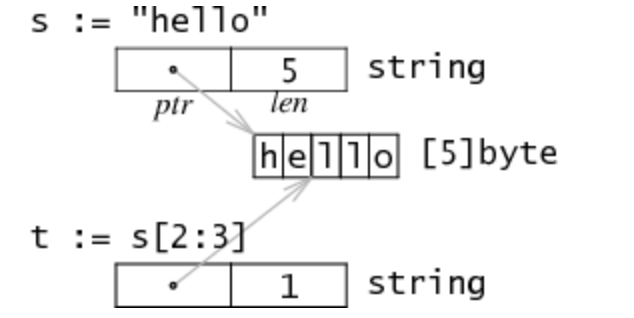
字符串在Go語言內存模型中用一個2字長(64位,32位內存布局方式下)的數據結構表示。它包含一個指向字符串數據存儲地方的指針,和一個字符串長度數據如下圖:
s是一個string類型的字符串,因為string類型不可變,對於多字符串共享同一個存儲數據是安全的。切分操作str[i:j]會得到一個新的2字長結構t,一個可能不同的但仍指向同一個字節序列(即上文說的存儲數據)的指針和長度數據。所以字符串切分不涉及內存分配或複製操作,其效率等同於傳遞下標。
1.2 數組
數組是內置(build-in)類型,是一組同類型數據的集合,它是值類型,通過從0開始的下標索引訪問元素值。數組類型定義了長度和元素類型。如, [4]int 類型表示一個四個整數的數組,其長度是固定的,長度是數組類型的一部分( [4]int 和 [5]int 是完全不同的類型)。 數組可以以常規的索引方式訪問,表達式 s[n] 訪問數組的第 n 個元素。數組不需要顯式的初始化;數組的零值是可以直接使用的,數組元素會自動初始化為其對應類型的零值。
1 var a [4]int 2 a[0] = 1 3 i := a[0] 4 // i == 1 5 // a[2] == 0, int 類型的零值 6 [5] int {1,2} //長度為5的數組,其元素值依次為:1,2,0,0,0 。在初始化時沒有指定初值的元素將會賦值為其元素類型int的默認值0,string的默認值是"" 7 [...] int {1,2,3,4,5} //長度為5的數組,其長度是根據初始化時指定的元素個數決定的 8 [5] int { 2:1,3:2,4:3} //長度為5的數組,key:value,其元素值依次為:0,0,1,2,3。在初始化時指定了2,3,4索引中對應的值:1,2,3 9 [...] int {2:1,4:3} //長度為5的數組,起元素值依次為:0,0,1,0,3。由於指定了最大索引4對應的值3,根據初始化的元素個數確定其長度為5賦值與使用
Go的數組是值語義。一個數組變量表示整個數組,它不是指向第一個元素的指針(不像 C 語言的數組)。 當一個數組變量被賦值或者被傳遞的時候,實際上會複製整個數組。 (為了避免複製數組,你可以傳遞一個指向數組的指針,但是數組指針並不是數組。) 可以將數組看作一個特殊的struct,結構的字段名對應數組的索引,同時成員的數目固定。
b := [2]string{"Penn", "Teller"} b := [...]string{"Penn", "Teller"}
這兩種寫法, b 都是對應 [2]string 類型。
2. 切片slice
2.1 結構
切片類型的寫法是[]T ,T是切片元素的類型。和數組不同的是,切片類型並沒有給定固定的長度。切片的字面值和數組字面值很像,不過切片沒有指定元素個數,切片可以通過數組來初始化,也可以通過內置函數make()初始化。
letters := []string{"a", "b", "c", "d"} //直接初始化切片,[]表示是切片類型,{"a", "b", "c", "d"},初始化值依次是a,b,c,d.其cap=len=4 s := letters [:] //初始化切片s,是數組letters的引用(a slice referencing the storage of x) func make([]T, len, cap) []T //使用內置函數 make 創建 s :=make([]int,len,cap) //通過內置函數make()初始化切片s,[]int 標識為其元素類型為int的切片 s := arr[startIndex:endIndex] //將arr中從下標startIndex到endIndex-1 下的元素創建為一個新的切片 s := arr[startIndex:] //缺省endIndex時將表示一直到arr的最後一個元素 s := arr[:endIndex] //缺省startIndex時將表示從arr的第一個元素開始 s1 := s[startIndex:endIndex] //通過切片s初始化切片s1
slice可以從一個數組或一個已經存在的slice中再次聲明。slice通過array[i:j]來獲取,其中i是數組的開始位置,j是結束位置,但不包含array[j],它的長度是j-i。
1 var ar = [10]byte{'a','b','c','d','e','f','g','h','i','j'} // 聲明一個含有10個元素元素類型為byte的數組 2 var a, b []byte // 聲明兩個含有byte的slice 3 a = ar[2:5] //現在a含有的元素: ar[2]、ar[3]和ar[4] 4 5 // b是數組ar的另一個slice 6 b = ar[3:5]// b的元素是:ar[3]和ar[4]
一個slice是一個數組某個部分的引用。在內存中它是一個包含三個域的結構體:指向slice中第一個元素的指針ptr,slice的長度數據len,以及slice的容量cap。長度是下標操作的上界,如x[i]中i必須小於長度。容量是分割操作的上界,如x[i:j]中j不能大於容量。slice在Go的運行時庫中就是一個C語言動態數組的實現,在$GOROOT/src/pkg/runtime/runtime.h中定義:
struct Slice { // must not move anything byte* array; // actual data uintgo len; // number of elements uintgo cap; // allocated number of elements };
數組的slice會創建一份新的數據結構,包含一個指針,一個指針和一個容量數據。如同分割一個字符串,分割數組也不涉及複製操作,它只是新建了一個結構放置三個數據。如下圖:
示例中,對[]int{2,3,5,7,11}求值操作會創建一個包含五個值的數組,並設置x的屬性來描述這個數組。分割表達式x[1:3]不重新分配內存數據,只寫了一個新的slice結構屬性來引用相同的存儲數據。上例中,長度為2–只有y[0]和y[1]是有效的索引,但是容量為4–y[0:4]是一個有效的分割表達式。
因為slice分割操作不需要分配內存,也沒有通常被保存在堆中的slice頭部,這種表示方法使slice操作和在C中傳遞指針、長度對一樣廉價。
2.2 擴容
其實slice在Go的運行時庫中就是一個C語言動態數組的實現,要增加切片的容量必須創建一個新的、更大容量的切片,然後將原有切片的內容複製到新的切片。在對slice進行append等操作時,可能會造成slice的自動擴容。其擴容時的大小增長規則是:
- 如果新的大小是當前大小2倍以上,則大小增長為新大小
- 否則循環以下操作:如果當前大小小於1024,按每次2倍增長,否則每次按當前大小1/4增長。直到增長的大小超過或等於新大小。
下面的例子將切片 s 容量翻倍,先創建一個2倍 容量的新切片 t ,複製 s 的元素到 t ,然後將 t 賦值給 s :
t := make([]byte, len(s), (cap(s)+1)*2) // +1 in case cap(s) == 0 for i := range s { t[i] = s[i] } s = t
循環中複製的操作可以由 copy 內置函數替代,返回複製元素的數目。此外, copy 函數可以正確處理源和目的切片有重疊的情況。
一個常見的操作是將數據追加到切片的尾部。必要的話會增加切片的容量,最後返回更新的切片:
func AppendByte(slice []byte, data ...byte) []byte { m := len(slice) n := m + len(data) if n > cap(slice) { // if necessary, reallocate // allocate double what's needed, for future growth. newSlice := make([]byte, (n+1)*2) copy(newSlice, slice) slice = newSlice } slice = slice[0:n] copy(slice[m:n], data) return slice }
Go提供了一個內置函數 append,也實現了這樣的功能。
func append(s []T, x ...T) []T //append 函數將 x 追加到切片 s 的末尾,並且在必要的時候增加容量。 a := make([]int, 1) // a == []int{0} a = append(a, 1, 2, 3) // a == []int{0, 1, 2, 3}
如果是要將一個切片追加到另一個切片尾部,需要使用 ... 語法將第2個參數展開為參數列表。
a := []string{"John", "Paul"} b := []string{"George", "Ringo", "Pete"} a = append(a, b...) // equivalent to "append(a, b[0], b[1], b[2])" // a == []string{"John", "Paul", "George", "Ringo", "Pete"}
由於切片的零值 nil 用起來就像一個長度為零的切片,我們可以聲明一個切片變量然後在循環 中向它追加數據:
// Filter returns a new slice holding only // the elements of s that satisfy fn() func Filter(s []int, fn func(int) bool) []int { var p []int // == nil for _, v := range s { if fn(v) { p = append(p, v) } } return p }
3. 使用切片需要注意的陷阱
切片操作並不會複製底層的數組。整個數組將被保存在內存中,直到它不再被引用。 有時候可能會因為一個小的內存引用導致保存所有的數據。
如下, FindDigits 函數加載整個文件到內存,然後搜索第一個連續的数字,最後結果以切片方式返回。
var digitRegexp = regexp.MustCompile("[0-9]+") func FindDigits(filename string) []byte { b, _ := ioutil.ReadFile(filename) return digitRegexp.Find(b) }
這段代碼的行為和描述類似,返回的 []byte 指向保存整個文件的數組。因為切片引用了原始的數組, 導致 GC 不能釋放數組的空間;只用到少數幾個字節卻導致整個文件的內容都一直保存在內存里。要修復整個問題,可以將需要的數據複製到一個新的切片中:
func CopyDigits(filename string) []byte { b, _ := ioutil.ReadFile(filename) b = digitRegexp.Find(b) c := make([]byte, len(b)) copy(c, b) return c }
使用 append 實現一個更簡潔的版本:
8 func CopyDigitRegexp(filename string) []byte { 7 b,_ := ioutil.ReadFile(filename) 6 b = digitRefexp.Find(b) 5 var c []intb 4 // for _,v := range b{ 3 c =append(c, b) 2 //} 1 return c 0 }
4. make和new
Go有兩個數據結構創建函數:make和new,也是兩種不同的內存分配機制。
make和new的基本的區別是new(T)返回一個*T,返回的是一個指針,指向分配的內存地址,該指針可以被隱式地消除引用)。而make(T, args)返回一個普通的T。通常情況下,T內部有一些隱式的指針。所以new返回一個指向已清零內存的指針,而make返回一個T類型的結構。更詳細的區別在後面內存分配的學習里研究。
5. 數組和切片的區別
- 數組長度不能改變,初始化后長度就是固定的;切片的長度是不固定的,可以追加元素,在追加時可能使切片的容量增大。
- 結構不同,數組是一串固定數據,切片描述的是截取數組的一部分數據,從概念上說是一個結構體。
- 初始化方式不同,如上。另外在聲明時的時候:聲明數組時,方括號內寫明了數組的長度或使用
...自動計算長度,而聲明slice時,方括號內沒有任何字符。 - unsafe.sizeof的取值不同,unsafe.sizeof(slice)返回的大小是切片的描述符,不管slice里的元素有多少,返回的數據都是24。unsafe.sizeof(arr)的值是在隨着arr的元素的個數的增加而增加,是數組所存儲的數據內存的大小。
unsafe.sizeof總是在編譯期就進行求值,而不是在運行時,這意味着,sizeof的返回值可以賦值給常量。 在編譯期求值,還意味着可以獲得數組所佔的內存大小,因為數組總是在編譯期就指明自己的容量,並且在以後都是不可變的。
unsafe.sizeof(string)時大小始終是16,不論字符串的len有多大,sizeof始終返回16,這是因為字符串類型對應一個結構體,該結構體有兩個域,第一個域是指向該字符串的指針,第二個域是字符串的長度,每個域佔8個字節,但是並不包含指針指向的字符串的內容。
6. nil
按照Go語言規範,任何類型在未初始化時都對應一個零值:布爾類型是false,整型是0,字符串是””,而指針,函數,interface,slice,channel和map的零值都是nil。
interface
一個interface在沒有進行初始化時,對應的值是nil。也就是說var v interface{},此時v就是一個nil。在底層存儲上,它是一個空指針。與之不同的情況是,interface值為空。比如:
1 var v *T 2 var i interface{} 3 i = v
此時i是一個interface,它的值是nil,但它自身不為nil。
string
string的空值是””,它是不能跟nil比較的。即使是空的string,它的大小也是兩個機器字長的。slice也類似,它的空值並不是一個空指針,而是結構體中的指針域為空,空的slice的大小也是三個機器字長的。
channel
channel跟string或slice有些不同,它在棧上只是一個指針,實際的數據都是由指針所指向的堆上面。
跟channel相關的操作有:初始化/讀/寫/關閉。channel未初始化值就是nil,未初始化的channel是不能使用的。下面是一些操作規則:
- 讀或者寫一個nil的channel的操作會永遠阻塞。
- 讀一個關閉的channel會立刻返回一個channel元素類型的零值。
- 寫一個關閉的channel會導致panic。
map
map也是指針,實際數據在堆中,未初始化的值是nil。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
※新北清潔公司,居家、辦公、裝潢細清專業服務