文:宋瑞文
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※幫你省時又省力,新北清潔一流服務好口碑
※別再煩惱如何寫文案,掌握八大原則!

上次幫小王解決了如何在 Spring Boot 中使用 JDBC 連接 MySQL 后,我就一直在等,等他問我第三個問題,比如說如何在 Spring Boot 中使用 HikariCP 連接池。但我等了四天也沒有等到任何音訊,似乎他從我的世界里消失了,而我卻仍然沉醉在他拍我馬屁的美妙感覺里。
突然感覺,沒有小王的日子里,好空虛。怎麼辦呢?想來想去還是寫文章度日吧,积極創作的過程中,也許能夠擺脫對小王的苦苦思念。寫什麼好呢?
想來想去,就寫如何在 Spring Boot 中使用 HikariCP 連接池吧。畢竟實戰項目當中,肯定不能使用 JDBC,連接池是必須的。而 HikariCP 據說非常的快,快到 Spring Boot 2 默認的數據庫連接池也從 Tomcat 切換到了 HikariCP(喜新厭舊的臭毛病能不能改改)。
HikariCP 的 GitHub 地址如下:
https://github.com/brettwooldridge/HikariCP
目前星標 12K,被使用次數更是達到了 43.1K。再來看看它的自我介紹。
牛逼的不能行啊,原來 Hikari 來源於日語,“光”的意思,這意味着快得像光速一樣嗎?講真,看簡介的感覺就好像在和我的女神“湯唯”握手一樣刺激和震撼。
既然 Spring Boot 2 已經默認使用了 HikariCP,那麼使用起來也相當的輕鬆愜意,只需要簡單幾個步驟。
既然要連接 MySQL,那麼就需要先在電腦上安裝 MySQL 服務(本文暫且跳過),並且創建數據庫和表。
CREATE DATABASE `springbootdemo`;
DROP TABLE IF EXISTS `mysql_datasource`;
CREATE TABLE `mysql_datasource` (
`id` varchar(64) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
創建一個 Spring Boot 項目非常簡單,通過 Spring Initlallzr(https://start.spring.io/)就可以了。
勾選 Web、JDBC、MySQL Driver 等三個依賴。
1)Web 表明該項目是一個 Web 項目,便於我們直接通過 URL 來實操。
3)MySQL Driver:連接 MySQL 服務器的驅動器。
5)JDBC:Spring Boot 2 默認使用了 HikariCP,所以 HikariCP 會默認在 spring-boot-starter-jdbc 中附加依賴,因此不需要主動添加 HikariCP 的依賴。
PS:怎麼證明這一點呢?項目導入成功后,在 pom.xml 文件中,按住鼠標左鍵 + Ctrl 鍵訪問 spring-boot-starter-jdbc 依賴節點,可在 spring-boot-starter-jdbc.pom 文件中查看到 HikariCP 的依賴信息。
選項選擇完后,就可以點擊【Generate】按鈕生成一個初始化的 Spring Boot 項目了。生成的是一個壓縮包,導入到 IDE 的時候需要先解壓。
項目導入成功后,等待 Maven 下載依賴,完成后編輯 application.properties 文件,配置 MySQL 數據源信息。
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/springbootdemo?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=123456
是不是有一種似曾相識的感覺(和[上一篇]()中的數據源配置一模一樣)?為什麼呢?答案已經告訴過大家了——默認、默認、默認,重要的事情說三遍,Spring Boot 2 默認使用了 HikariCP 連接池。
為了便於我們查看 HikariCP 的連接信息,我們對 SpringBootMysqlApplication 類進行編輯,增加以下內容。
@SpringBootApplication
public class HikariCpDemoApplication implements CommandLineRunner {
@Autowired
private DataSource dataSource;
public static void main(String[] args) {
SpringApplication.run(HikariCpDemoApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
Connection conn = dataSource.getConnection();
conn.close();
}
}
HikariCpDemoApplication 實現了 CommandLineRunner 接口,該接口允許我們在項目啟動的時候加載一些數據或者做一些事情,比如說我們嘗試通過 DataSource 對象與數據源建立連接,這樣就可以在日誌信息中看到 HikariCP 的連接信息。CommandLineRunner 接口有一個方法需要實現,就是我們看到的 run() 方法。
通過 debug 的方式,我們可以看到,在項目運行的過程中,dataSource 這個 Bean 的類型為 HikariDataSource。
接下來,我們直接運行 HikariCpDemoApplication 類,這樣一個 Spring Boot 項目就啟動成功了。
HikariDataSource 對象的連接信息會被打印出來。也就是說,HikariCP 連接池的配置啟用了。快給自己點個贊。
有幾種基準測試結果可用來比較HikariCP和其他連接池框架(例如c3p0,dbcp2,tomcat和vibur)的性能。例如,HikariCP團隊發布了以下基準(可在此處獲得原始結果):
HikariCP 團隊為了證明自己性能最佳,特意找了幾個背景對比了下。不幸充當背景的有 c3p0、dbcp2、tomcat 等傳統的連接池。
從上圖中,我們能感受出背景的尷尬,HikariCP 鶴立雞群了。HikariCP 製作以如此優秀,原因大致有下面這些:
1)字節碼級別上的優化:要求編譯后的字節碼最少,這樣 CPU 緩存就可以加載更多的程序代碼。
HikariCP 優化前的代碼片段:
public final PreparedStatement prepareStatement(String sql, String[] columnNames) throws SQLException
{
return PROXY_FACTORY.getProxyPreparedStatement(this, delegate.prepareStatement(sql, columnNames));
}
HikariCP 優化后的代碼片段:
public final PreparedStatement prepareStatement(String sql, String[] columnNames) throws SQLException
{
return ProxyFactory.getProxyPreparedStatement(this, delegate.prepareStatement(sql, columnNames));
}
以上兩段代碼的差別只有一處,就是 ProxyFactory 替代了 PROXY_FACTORY,這個改動后的字節碼比優化前減少了 3 行指令。具體的分析參照 HikariCP 的 Wiki 文檔。
2)使用自定義的列表(FastStatementList)代替 ArrayList,可以避免 get() 的時候進行範圍檢查,remove() 的時候從頭到尾的掃描。
好了,各位讀者朋友們,答應小王的文章終於寫完了。能看到這裏的都是最優秀的程序員,升職加薪就是你了。如果覺得不過癮,還想看到更多,可以 star 二哥的 GitHub【itwanger.github.io】,本文已收錄。
PS:本文配套的源碼已上傳至 GitHub 【SpringBootDemo.SpringBootMysql】。
原創不易,如果覺得有點用的話,請不要吝嗇你手中點贊的權力;如果想要第一時間看到二哥更新的文章,請掃描下方的二維碼,關注沉默王二公眾號。我們下篇文章見!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※新北清潔公司,居家、辦公、裝潢細清專業服務
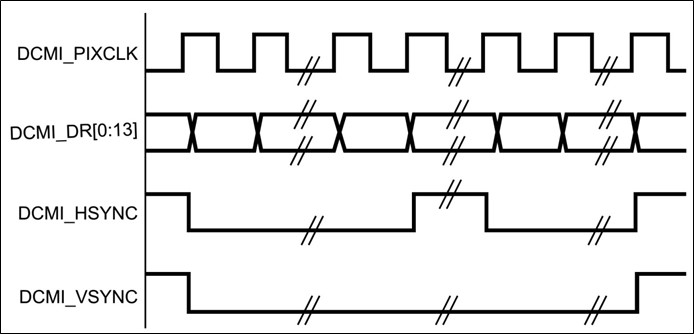
1、STM32圖像接收接口
使用stm32芯片,128kB RAM,512kB Rom,資源有限,接攝像頭採集圖像,這種情況下,內存利用制約程序設計。
STM32使用DCMI接口讀取攝像頭,協議如下。行同步信號指示了一行數據完成,場同步信號指示了一幀圖像傳輸完成。所以出現了兩種典型的數據接收方式,按照行信號一行一行處理,按照場信號一次接收一副圖像。
2、按行讀取
以網絡上流行的野火的demo為例,使用行中斷,用DMA來讀取一行數據。
//記錄傳輸了多少行 static uint16_t line_num =0; //DMA傳輸完成中斷服務函數 void DMA2_Stream1_IRQHandler(void) { if ( DMA_GetITStatus(DMA2_Stream1,DMA_IT_TCIF1) == SET ) { /*行計數*/ line_num++; if (line_num==img_height) { /*傳輸完一幀,計數複位*/ line_num=0; } /*DMA 一行一行傳輸*/ OV2640_DMA_Config(FSMC_LCD_ADDRESS+(lcd_width*2*(lcd_height-line_num-1)),img_width*2/4); DMA_ClearITPendingBit(DMA2_Stream1,DMA_IT_TCIF1); } } //幀中斷服務函數,使用幀中斷重置line_num,可防止有時掉數據的時候DMA傳送行數出現偏移 void DCMI_IRQHandler(void) { if ( DCMI_GetITStatus (DCMI_IT_FRAME) == SET ) { /*傳輸完一幀,計數複位*/ line_num=0; DCMI_ClearITPendingBit(DCMI_IT_FRAME); } }
DMA中斷服務函數中主要是使用了一個靜態變量line_num來記錄已傳輸了多少行數據,每進一次DMA中斷時自加1,由於進入一次中斷就代表傳輸完一行數據,所以line_num的值等於lcd_height時(攝像頭輸出的數據行數),表示傳輸完一幀圖像,line_num複位為0,開始另一幀數據的傳輸。line_num計數完畢后利用前面定義的OV2640_DMA_Config函數配置新的一行DMA數據傳輸,它利用line_num變量計算顯存地址的行偏移,控制DCMI數據被傳送到正確的位置,每次傳輸的都是一行像素的數據量。
當DCMI接口檢測到攝像頭傳輸的幀同步信號時,會進入DCMI_IRQHandler中斷服務函數,在這個函數中不管line_num原來的值是什麼,它都把line_num直接複位為0,這樣下次再進入DMA中斷服務函數的時候,它會開始新一幀數據的傳輸。這樣可以利用DCMI的硬件同步信號,而不只是依靠DMA自己的傳輸計數,這樣可以避免有時STM32內部DMA傳輸受到阻塞而跟不上外部攝像頭信號導致的數據錯誤。
圖像按幀讀取比按行讀取效率更高,那麼為什麼要按行讀取呢?上面的例子是把圖像送到LCD,如果是送到內存,按幀讀取就需要芯片有很大的內存空間。以752*480的分辨率為例,需要360kB的RAM空間,遠遠超出了芯片RAM的大小。部分應用不需要攝像頭全尺寸的圖像,只需要中心區域,比如為了避免畸變影響一般只用圖像中間的部分,那麼按行讀取就有一個好處,讀到一行后,可以把不需要的丟棄,只保留中間部分的圖像像素。
那麼問題來了?為什麼不直接配置攝像頭的屬性,來實現只讀取圖像的中間部分呢,全部讀取出來然後在arm的內存中裁剪丟棄不要的像素,第一浪費了讀取時間,第二浪費了讀取的空間。更優的做法是直接配置攝像頭sensor,使用sensor的裁剪功能輸出需要的像素區域。
3、圖像裁剪–使用STM32 crop功能裁剪
STM32F4系列的DCMI接口支持裁剪功能,對攝像頭輸出的像素點進行截取,不需要的像素部分不被DCMI傳入內存,從硬件接口一側就丟棄了。
HAL_DCMI_EnableCrop(&hdcmi); HAL_DCMI_ConfigCrop(&hdcmi, CAM_ROW_OFFSET, CAM_COL_OFFSET, IMG_ROW-1, IMG_COL-1);
裁剪的本質如下所述,從接收到的數據里選擇需要的矩形區域。所以STM32 DCMI裁剪功能可以完成節約內存,只選取需要的圖像存入內存的作用。
此方法相比於一次讀一行,然後丟棄首尾部分后把需要的區域圖像像素存入buffer后再讀下一行,避免了時序錯誤,代碼簡潔了,DCMI硬件計數丟掉不要的像素,也提高了程序可靠性、可讀性。
成也蕭何敗也蕭何,如上面所述,STM32的crop完成了選取特定區域圖像的功能,那麼也要付出代價,它是從接收到的圖像數據里進行選擇的,這意味着那些不需要的數據依然會傳輸到MCU一側,只不過MCU的DCMI對數據進行計數是忽略了它而已,那麼問題就來了,哪些不需要的數據的傳輸會帶來什麼問題呢?
有圖為證,下圖是使用了STM32 crop裁剪的時序圖,通道1啟動採集IO置高,frame中斷里拉低,由於使用dma傳輸,那麼被crop裁剪后dma計數的數據量變少,所以DCMI frame中斷能在行數據傳輸完成前到達,通道1高電平部分就代表一有效分辨率的幀的採集時間。通道2 曝光信號管腳,通道3是行掃描信號。其中通道1下降沿到通道3下降沿4.5ms。代表單片機已經收到crop指定尺寸的圖像,採集有效區域(crop區域)的圖像完成,但是line信號沒有結束還有很多行沒傳輸,即CMOS和DCMI接口要傳輸752*480圖像還沒完成。
舉例說明,如果使用752*480分辨率採集圖像,你只取中間的360*360視野,有效分辨率是360*360,但是總線上的數據依然是752*480,所以幀率無法提高,多餘的數據按說就不應該傳輸出來,如何破解,問題追到這裏,STM32芯片已經無能為力了,接下來需要在CMOS一側發力了。
4、圖像裁剪–配置CMOS寄存器裁剪
下圖是MT9V034 攝像頭芯片的寄存器手冊,Reg1–4配置CMOS的行列起點和寬度高度。
修改寄存器后,攝像頭CMOS就不再向外傳輸多餘的數據,被裁剪丟棄的數據也不會反應在接口上,所以STM32 DCMI接收到的數據都是需要保留的有效區數據,極大地減少了數據輸出,提高了傳輸效率。本人也在STM324芯片上,實現了220*220分辨率120幀的連續採集。
下面是序圖,通道1高電平代表開始採集和一幀結束,不同於使用STM32 的crop裁剪,使用CMOS寄存器裁剪有效窗口,使得幀結束時行信號也同時結束,後續沒有任何需要傳輸的行數據。
5、一幀數據一次性傳輸
一幀數據一次全部讀入到MCU的方式,其實是最簡單的驅動編寫方式,缺點就是太占內存,但是對於沒有壓縮功能的cmos芯片來說,一般都無力實現。對部分有jpg壓縮功能的cmos芯片而言,比如OV2640可以使用這種方式,一次性讀出一幀圖像。
__align(4) u32 jpeg_buf[jpeg_buf_size]; //JPEG buffer //JPEG 格式 const u16 jpeg_img_size_tbl[][2]= { 176,144, //QCIF 160,120, //QQVGA 352,288, //CIF 320,240, //QVGA 640,480, //VGA 800,600, //SVGA 1024,768, //XGA 1280,1024, //SXGA 1600,1200, //UXGA };
//DCMI 接收數據
void DCMI_IRQHandler(void)
{
if(DCMI_GetITStatus(DCMI_IT_FRAME)==SET)// 一幀數據
{
jpeg_data_process();
DCMI_ClearITPendingBit(DCMI_IT_FRAME);
}
}
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※幫你省時又省力,新北清潔一流服務好口碑
※別再煩惱如何寫文案,掌握八大原則!

掌握Git命令是每位程序員必備的基礎,之前一直是用smartGit工具,直到看到大佬們都是在用Git命令操作的,回想一下,發現有些Git命令我都忘記了,於是寫了這篇博文,複習一下~
https://github.com/whx123/JavaHome
公眾號:撿田螺的小男孩
文章目錄
在回憶Git是什麼的話,我們先來複習這幾個概念哈~
百度百科定義是醬紫的~
版本控制是指對軟件開發過程中各種程序代碼、配置文件及說明文檔等文件變更的管理,是軟件配置管理的核心思想之一。
那些年,我們的畢業論文,其實就是版本變更的真實寫照…腦洞一下,版本控制就是這些論文變更的管理~
那麼,集中化的版本控制系統又是什麼呢,說白了,就是有一個集中管理的中央服務器,保存着所有文件的修改歷史版本,而協同開發者通過客戶端連接到這台服務器,從服務器上同步更新或上傳自己的修改。
分佈式版本控制系統,就是遠程倉庫同步所有版本信息到本地的每個用戶。嘻嘻,這裏分三點闡述吧:
Git是免費、開源的分佈式版本控制系統,可以有效、高速地處理從很小到非常大的項目版本管理。
先複習Git的幾個工作區域哈:
上一小節介紹完Git的四大工作區域,這一小節呢,介紹Git的工作流程咯,把git的操作命令和幾個工作區域結合起來,個人覺得更容易理解一些吧,哈哈,看圖:
git 的正向工作流程一般就這樣:
根據一個文件是否已加入版本控制,可以把文件狀態分為:Tracked(已跟蹤)和Untracked(未跟蹤),而tracked(已跟蹤)又包括三種工作狀態:Unmodified,Modified,Staged
這個圖只是模擬一下git基本命令使用的大概流程哈~
當我們要進行開發,第一步就是克隆遠程版本庫到本地呢
git clone url 克隆遠程版本庫
克隆完之後呢,開發新需求的話,我們需要新建一個開發分支,比如新建開發分支dev
創建分支:
git checkout -b dev 創建開發分支dev,並切換到該分支下
git add的使用格式:
git add . 添加當前目錄的所有文件到暫存區
git add [dir] 添加指定目錄到暫存區,包括子目錄
git add [file1] 添加指定文件到暫存區
有了開發分支dev之後,我們就可以開始開發啦,假設我們開發完HelloWorld.java,可以把它加到暫存區,命令如下
git add Hello.java 把HelloWorld.java文件添加到暫存區去
git commit的使用格式:
git commit -m [message] 提交暫存區到倉庫區,message為說明信息
git commit [file1] -m [message] 提交暫存區的指定文件到本地倉庫
git commit --amend -m [message] 使用一次新的commit,替代上一次提交
把HelloWorld.java文件加到暫存區后,我們接着可以提交到本地倉庫啦~
git commit -m 'helloworld開發'
git status,表示查看工作區狀態,使用命令格式:
git status 查看當前工作區暫存區變動
git status -s 查看當前工作區暫存區變動,概要信息
git status --show-stash 查詢工作區中是否有stash(暫存的文件)
當你忘記是否已把代碼文件添加到暫存區或者是否提交到本地倉庫,都可以用git status看看哦~
git log,這個命令用得應該比較多,表示查看提交歷史/提交日誌~
git log 查看提交歷史
git log --oneline 以精簡模式显示查看提交歷史
git log -p <file> 查看指定文件的提交歷史
git blame <file> 一列表方式查看指定文件的提交歷史
嘻嘻,看看dev分支上的提交歷史吧要回滾代碼就經常用它喵喵提交歷史
git diff 显示暫存區和工作區的差異
git diff filepath filepath路徑文件中,工作區與暫存區的比較差異
git diff HEAD filepath 工作區與HEAD ( 當前工作分支)的比較差異
git diff branchName filepath 當前分支的文件與branchName分支的文件的比較差異
git diff commitId filepath 與某一次提交的比較差異
如果你想對比一下你改了哪些內容,可以用git diff對比一下文件修改差異哦
git pull 拉取遠程倉庫所有分支更新併合併到本地分支。
git pull origin master 將遠程master分支合併到當前本地master分支
git pull origin master:master 將遠程master分支合併到當前本地master分支,冒號後面表示本地分支
git fetch --all 拉取所有遠端的最新代碼
git fetch origin master 拉取遠程最新master分支代碼
我們一般都會用git pull拉取最新代碼看看的,解決一下衝突,再推送代碼到遠程倉庫的。
有些夥伴可能對使用git pull還是git fetch有點疑惑,其實
git pull = git fetch+ git merge。pull的話,拉取遠程分支並與本地分支合併,fetch只是拉遠程分支,怎麼合併,可以自己再做選擇。
git push 可以推送本地分支、標籤到遠程倉庫,也可以刪除遠程分支哦。
git push origin master 將本地分支的更新全部推送到遠程倉庫master分支。
git push origin -d <branchname> 刪除遠程branchname分支
git push --tags 推送所有標籤
如果我們在dev開發完,或者就想把文件推送到遠程倉庫,給別的夥伴看看,就可以使用git push origin dev~
Git一般都是存在多個分支的,開發分支,回歸測試分支以及主幹分支等,所以Git分支處理的命令也需要很熟悉的呀~
git branch用處多多呢,比如新建分支、查看分支、刪除分支等等
新建分支:
git checkout -b dev2 新建一個分支,並且切換到新的分支dev2
git branch dev2 新建一個分支,但是仍停留在原來分支
查看分支:
git branch 查看本地所有的分支
git branch -r 查看所有遠程的分支
git branch -a 查看所有遠程分支和本地分支
刪除分支:
git branch -D <branchname> 刪除本地branchname分支
切換分支:
git checkout master 切換到master分支
我們在開發分支dev開發、測試完成在發布之前,我們一般需要把開發分支dev代碼合併到master,所以git merge也是程序員必備的一個命令。
git merge master 在當前分支上合併master分支過來
git merge --no-ff origin/dev 在當前分支上合併遠程分支dev
git merge --abort 終止本次merge,並回到merge前的狀態
比如,你開發完需求后,發版全需要把代碼合到主幹master分支,如下:
Git版本控制,還是多個人一起搞的,多個分支並存的,這就難免會有衝突出現~
同一個文件,在合併分支的時候,如果同一行被多個分支或者不同人都修改了,合併的時候就會出現衝突。
舉個粟子吧,我們現在在dev分支,修改HelloWorld.java文件,假設修改了第三行,並且commit提交到本地倉庫,修改內容如下:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello,撿田螺的小男孩!");
}
}
我們切回到master分支,也修改HelloWorld.java同一位置內容,如下:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello,jay!!");
}
}
再然後呢,我們提交一下master分支的這個改動,並把dev分支合併過下,就出現衝突啦,如圖所示:
Git 解決衝突步驟如下:
git merge提示衝突后,我們切換到對應文件,看看衝突內容哈,,如下:
所以呢,我們確定到底保留哪個分支內容,還是兩個分支內容都保留呢,然後再去修改文件衝突內容~
Git的撤銷與回退,在日常工作中使用的比較頻繁。比如我們想將某個修改后的文件撤銷到上一個版本,或者想撤銷某次多餘的提交,都要用到git的撤銷和回退操作。
代碼在Git的每個工作區域都是用哪些命令撤銷或者回退的呢,如下圖所示:
有關於Git的撤銷與回退,一般就以下幾個核心命令
如果文件還在工作區,還沒添加到暫存區,可以使用git checkout撤銷
git checkout [file] 丟棄某個文件file
git checkout . 丟棄所有文件
以下demo,使用git checkout — test.txt 撤銷了暫存區test.txt的修改
git reset的作用是修改HEAD的位置,即將HEAD指向的位置改變為之前存在的某個版本.
為了更好地理解git reset,我們來回顧一下,Git的版本管理及HEAD的理解
Git的所有提交,會連成一條時間軸線,這就是分支。如果當前分支是master,HEAD指針一般指向當前分支,如下:
假設執行git reset,回退到版本二之後,版本三不見了哦,如下:
Git Reset的幾種使用模式
git reset HEAD --file
回退暫存區里的某個文件,回退到當前版本工作區狀態
git reset –-soft 目標版本號 可以把版本庫上的提交回退到暫存區,修改記錄保留
git reset –-mixed 目標版本號 可以把版本庫上的提交回退到工作區,修改記錄保留
git reset –-hard 可以把版本庫上的提交徹底回退,修改的記錄全部revert。
先看一個粟子demo吧,代碼git add到暫存區,並未commit提交,就以下醬紫回退,如下:
git reset HEAD file 取消暫存
git checkout file 撤銷修改
再看另外一個粟子吧,代碼已經git commit了,但是還沒有push:
git log 獲取到想要回退的commit_id
git reset --hard commit_id 想回到過去,回到過去的commit_id
如果代碼已經push到遠程倉庫了呢,也可以使用reset回滾哦(這裏大家可以自己操作實踐一下哦)~
git log
git reset --hard commit_id
git push origin HEAD --force
與git reset不同的是,revert複製了那個想要回退到的歷史版本,將它加在當前分支的最前端。
revert之前:
revert 之後:
當然,如果代碼已經推送到遠程的話,還可以考慮revert回滾呢
git log 得到你需要回退一次提交的commit id
git revert -n <commit_id> 撤銷指定的版本,撤銷也會作為一次提交進行保存
打tag就是對發布的版本標註一個版本號,如果版本發布有問題,就把該版本拉取出來,修復bug,再合回去。
git tag 列出所有tag
git tag [tag] 新建一個tag在當前commit
git tag [tag] [commit] 新建一個tag在指定commit
git tag -d [tag] 刪除本地tag
git push origin [tag] 推送tag到遠程
git show [tag] 查看tag
git checkout -b [branch] [tag] 新建一個分支,指向某個tag
rebase又稱為衍合,是合併的另外一種選擇。
假設有兩個分支master和test
D---E test
/
A---B---C---F--- master
執行 git merge test得到的結果
D--------E
/ \
A---B---C---F----G--- test, master
執行git rebase test,得到的結果
A---B---D---E---C‘---F‘--- test, master
rebase好處是: 獲得更優雅的提交樹,可以線性的看到每一次提交,並且沒有增加提交節點。所以很多時候,看到有些夥伴都是這個命令拉代碼:git pull –rebase
stash命令可用於臨時保存和恢復修改
git stash 把當前的工作隱藏起來 等以後恢復現場後繼續工作
git stash list 显示保存的工作進度列表
git stash pop stash@{num} 恢復工作進度到工作區
git stash show :显示做了哪些改動
git stash drop stash@{num} :刪除一條保存的工作進度
git stash clear 刪除所有緩存的stash。
显示當前分支的最近幾次提交
git blame 記錄了某個文件的更改歷史和更改人,可以查看背鍋人,哈哈
git remote 查看關聯的遠程倉庫的名稱
git remote add url 添加一個遠程倉庫
git remote show [remote] 显示某個遠程倉庫的信息
感謝各位前輩的文章:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※新北清潔公司,居家、辦公、裝潢細清專業服務
※推薦評價好的iphone維修中心
Tushare是一個免費、開源的python財經數據接口包。主要實現對股票等金融數據從數據採集、清洗加工 到 數據存儲的過程,用戶可以免費(部分數據的下載有積分限制)的通過它提供的財經接口獲取股票交易、期貨等財經信息,功能非常強大。該接口和直接到各財經網站爬數據相比,最大的優勢就是快,去傳統財經網站爬數據,好多關鍵性的股票信息只能一隻股一隻股爬,而Tu Share的API,一個調用可以獲得一天的全部數據,速度差了好幾個數量級。另外一方面各財經網站的接口的API沒有對外文檔化,隨時可能變化,而Tu Share的API有正式的文檔化相對比較穩定。
該網站使用積分制來控制數據的訪問權限,如果想要訪問數據,先要到下面這個網址完成註冊,https://tushare.pro/register。註冊完成后,可以需要到個人主頁中拷貝Token,這個Token會在以後的訪問中用到,步驟如下
1、登錄成功后,點擊右上角->個人主頁
2、 在“用戶中心”中點擊“接口TOKEN”
3、 可以點擊右側複製按鈕複製token
Tushare HTTP數據獲取的方式,採用了post的機制,通過提交JSON body參數,就可以獲得您想要的數據。具體參數說明如下:
api_name:接口名稱,比如stock_basic
token :用戶唯一標識,可通過登錄pro網站獲取
params:接口參數,如daily接口中start_date和end_date
fields:字段列表,用於接口獲取指定的字段,以逗號分隔,如”open,high,low,close”
code: 接口返回碼,2002表示權限問題。
msg:錯誤信息,比如“系統內部錯誤”,“沒有權限”等
data:數據,data里包含fields和items字段,分別為字段和數據內容
1、在Visual Studio中安裝下面幾個包:Microsoft.Extensions.Http、Newtonsoft.Json
2、封裝方法,實現對REST web service的調用
public interface IHttpClientUtility { string HttpClientPost(string url, object datajson); }
public class HttpClientUtility : IHttpClientUtility { public HttpClientUtility() { } public string HttpClientPost(string url, object datajson) { using (HttpClient httpClient = new HttpClient()) //http對象 { httpClient.DefaultRequestHeaders.Accept.Clear(); httpClient.DefaultRequestHeaders.Accept.Add(new MediaTypeWithQualityHeaderValue("application/json")); httpClient.Timeout = new TimeSpan(0, 0, 5); //轉為鏈接需要的格式 HttpContent httpContent = new JsonContent(datajson); //請求 HttpResponseMessage response = httpClient.PostAsync(url, httpContent).Result; if (response.IsSuccessStatusCode) { Task<string> t = response.Content.ReadAsStringAsync(); return t.Result; } throw new Exception("調用失敗"); } } }
public class JsonContent : StringContent { public JsonContent(object value) : base(JsonConvert.SerializeObject(value), Encoding.UTF8, "application/json") { } public JsonContent(object value, string mediaType) : base(JsonConvert.SerializeObject(value), Encoding.UTF8, mediaType) { } }
3、封裝對Tu Share API的調用
public class TuShareUtility { private IHttpClientUtility _httpClientUtility; private string _url = "http://api.waditu.com/"; public TuShareUtility(IHttpClientUtility httpClientUtility) { _httpClientUtility = httpClientUtility; } /// <summary> /// 調用TuShare API /// </summary> /// <param name="apiName"></param> /// <param name="parmaMap"></param> /// <param name="fields"></param> /// <returns></returns> public DataTable GetData(string apiName,Dictionary<string,string> parmaMap,params string[] fields) { var tuShareParamObj=new TuShareParamObj(){ ApiName = apiName ,Params = parmaMap,Fields = string.Join(",",fields)}; //做Http調用 var result=_httpClientUtility.HttpClientPost(_url, tuShareParamObj); //將返回結果序列化成對象 var desResult=JsonConvert.DeserializeObject<TuShareResult>(result); //如果調用失敗,拋出異常 if(!string.IsNullOrEmpty(desResult.Msg)) throw new Exception(desResult.Msg); //返回結果分成兩部分,一部分是列頭信息,另一部分是數據本身,用這兩部分數據可以構建DataTable DataTable dt = new DataTable(); foreach (var dataField in desResult.Data.Fields) { dt.Columns.Add(dataField); } foreach (var dataItemRow in desResult.Data.Items) { var newdr=dt.NewRow(); for (int i=0;i< dataItemRow.Length;i++) { newdr[i] = dataItemRow[i]; } dt.Rows.Add(newdr); } return dt; } private class TuShareParamObj { [JsonProperty("api_name")] public string ApiName { get; set; } [JsonProperty("token")] public string Token { get; } = "****************";//你的Token [JsonProperty("params")] public Dictionary<string, string> Params { get; set; } [JsonProperty("fields")] public string Fields { get; set; } } private class TuShareData { [JsonProperty("fields")] public string[] Fields { get; set; } [JsonProperty("items")] public string[][] Items { get; set; } } private class TuShareResult { [JsonProperty("code")] public string Code { get; set; } [JsonProperty("msg")] public string Msg { get; set; } [JsonProperty("data")] public TuShareData Data { get; set; } } }
4、調用示例
獲得日線行情,整個過程1秒左右,返回6月24日,股票相關交易信息,代碼如下,(該網站的其它接口定義可以到https://tushare.pro/document/2查看)
var tuShareUtility=new TuShareUtility(); Dictionary<string, string> p = new Dictionary<string, string>(); p["trade_date"] = "20200624"; var table = tuShareUtility.GetData("daily", p, "");
返回如下結果
返回字段說明
| 名稱 | 類型 | 描述 |
|---|---|---|
| ts_code | str | 股票代碼 |
| trade_date | str | 交易日期 |
| open | float | 開盤價 |
| high | float | 最高價 |
| low | float | 最低價 |
| close | float | 收盤價 |
| pre_close | float | 昨收價 |
| change | float | 漲跌額 |
| pct_chg | float | 漲跌幅 (未復權,如果是復權請用 通用行情接口 ) |
| vol | float | 成交量 (手) |
| amount | float | 成交額 (千元) |
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
※回頭車貨運收費標準
URI = Universal Resource Identifier
URL = Universal Resource Locator
在學習中,我們難免會遇到 URI 和 URL,有時候都傻傻分不清,為啥這邊是 URI 那邊又是 URL,這兩者到底有什麼區別呢?
我們從名字上看
可能大家就比較困惑了,這倆好像是一樣的啊?那我們就類比一下我們現實生活中的情況:
我們要找一個人——張三,我們可以通過他的唯一的標識來找,比如說身份證,那麼這個身份證就唯一的標識了一個人,這個身份證就是一個 URI;
而要找到張三,我們不一定要用身份證去找,我們還可以根據地址去找,如 在清華大學18號宿舍樓的404房間第一個床鋪的張三,我們也可以唯一確定一個張三,
動物住址協議://地球/中國/北京市/清華大學/18號宿舍樓/404號寢/張三.人。而這個地址就是我們用於標識和定位的 URL。
我們從上面可以很明顯的看出,URI 通過任何方法標識一個人即可,而 URL 雖然也可以標識一個人,但是它主要是通過定位地址的方法標識一個人,所以 URL 其實是 URI 的一個子集,即 URL 是靠標識定位地址的一個 URI。
URL(Uniform Resource Locator,統一資源定位符),用於定位網絡上的資源,每一個信息資源都有統一的且在網上唯一的地址。
Url一般有以下部分組成
scheme://host:port/path?query#fragment
Scheme: 通信協議,一般為http、https等;
Host: 服務器的域名主機名或ip地址;
Port: 端口號,此項為可選項,默認為80;
Path: 目錄,由“/”隔開的字符串,表示的是主機上的目錄或文件地址;
Query: 查詢,此項為可選項,可以給動態網頁傳遞參數,用“&”隔開,每個參數的名和值用“=”隔開;
Fragment: 信息片段,字符串,用於指定網絡資源中的某片斷;
其實,把 URL 說成是網址其實是很不嚴謹的說法,因為 URL 有很嚴格的結構,表示也很靈活、有彈性。
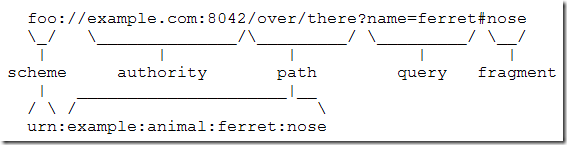
在 RFC 3986: Uniform Resource Identifier (URI): Generic Syntax 的 Syntax Components 把 URL 描述為如下圖:
如圖所示,把 URL 分成幾個部分,這樣便可以了解URL的構成。 在 URI scheme – Wikipedia 頁面中對 URL 的描述更為詳細,如下圖:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※新北清潔公司,居家、辦公、裝潢細清專業服務
※推薦評價好的iphone維修中心
最近在寫一個多模塊的SpringBoot項目,基於過程總了一些總結,故把SpringBoot多個模塊的項目創建記錄下來。
首先,先建立一個父工程:
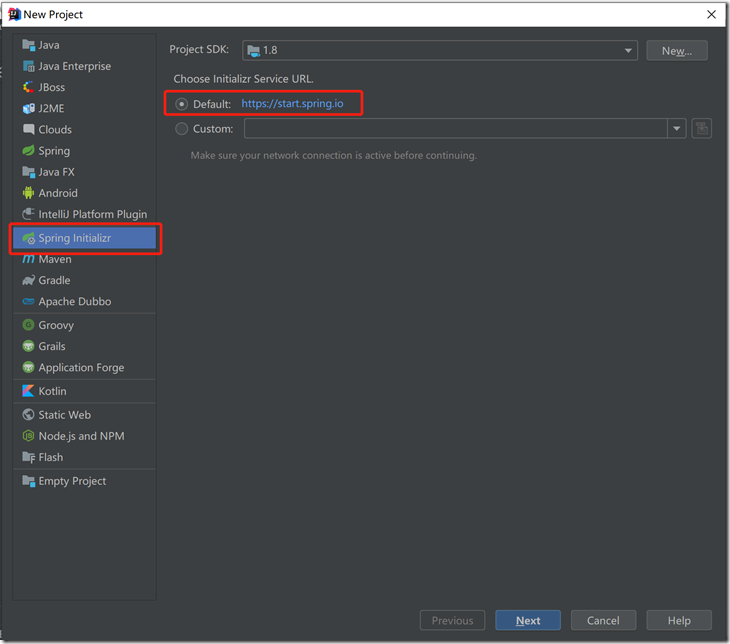
(1)在IDEA工具欄選擇File->New->Project
(2)選擇Spring Initializr,默認選擇Default,然後點擊Next:
(3)在輸入框填寫以下截圖內容,點擊Next
(4)直接點Next,無需選擇
(5)直接點擊Finish完成創建
(6)按照以上步驟,可以生成以下的項目目錄結構:
(7)這時把沒用的.mvn目錄,src目錄,mvnw還有mvnw.cmd都刪除,最終只保留.gitignore和pom.xml,若是web項目,可在該pom.xml里添加以下依賴:
1 <!--web特徵--> 2 <dependency> 3 <groupId>org.springframework.boot</groupId> 4 <artifactId>spring-boot-starter-web</artifactId> 5 <version>2.3.1.RELEASE</version> 6 </dependency>
最終得到以下的父結構目錄:
以上是創建父模塊,下面創建子模塊:
(1)在父模塊的根目錄fte上點右鍵,在彈出的框里選擇New->Module
(2)選擇Maven,點擊Next
(3)填寫以下內容,點擊Next
(4)填寫Module,點擊Finish
(5)同理添加fte-controller,fte-dao,fte-service,fte-web,最終得到以下的目錄結構:
(6)增加模塊之間的依賴:
controller層添加以下依賴:
1 <dependencies> 2 <dependency> 3 <groupId>com.example</groupId> 4 <artifactId>fte-common</artifactId> 5 <version>0.0.1-SNAPSHOT</version> 6 </dependency> 7 8 <dependency> 9 <groupId>com.example</groupId> 10 <artifactId>fte-dao</artifactId> 11 <version>0.0.1-SNAPSHOT</version> 12 </dependency> 13 14 <dependency> 15 <groupId>com.example</groupId> 16 <artifactId>fte-service</artifactId> 17 <version>0.0.1-SNAPSHOT</version> 18 </dependency> 19 </dependencies>
service層添加以下依賴:
1 <dependencies> 2 <dependency> 3 <groupId>com.example</groupId> 4 <artifactId>fte-dao</artifactId> 5 <version>0.0.1-SNAPSHOT</version> 6 </dependency> 7 </dependencies>
(7)測試
在fte-controller創建com.zhu.fte.web包,增加以下兩個類:
fteWebApplication類:
1 package com.zhu.fte.web; 2 3 import org.springframework.boot.SpringApplication; 4 import org.springframework.boot.autoconfigure.SpringBootApplication; 5 6 @SpringBootApplication 7 public class fteWebApplication { 8 public static void main(String[] args) { 9 SpringApplication.run(fteWebApplication.class,args); 10 } 11 }
DemoController類
1 package java.com.zhu.fte.web; 2 3 import org.springframework.web.bind.annotation.GetMapping; 4 import org.springframework.web.bind.annotation.RequestMapping; 5 import org.springframework.web.bind.annotation.RestController; 6 7 @RestController 8 @RequestMapping("demo") 9 public class DemoController { 10 11 @GetMapping("test") 12 public String test(){ 13 return "hello world"; 14 } 15 16 }
運行發現出現錯誤:
出現錯誤:
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-surefire-plugin:2.22.2:test (default-test) on project fte-common: Execution default-test of goal org.apache.maven.plugins:maven-surefire-plugin:2.22.2:test failed: Plugin org.apache.maven.plugins:maven-surefire-plugin:2.22.2 or one of its dependencies could not be resolved: Could not transfer artifact junit:junit:jar:4.12 from/to central (https://repo.maven.apache.org/maven2): Connect to repo.maven.apache.org:443 [repo.maven.apache.org/151.101.52.215] failed: Connection timed out: connect -> [Help 1]
把缺少的org.apache.maven.plugins手動放到父工程的pom.xml里
1 <build> 2 <plugins> 3 <plugin> 4 <groupId>org.apache.maven.plugins</groupId> 5 <artifactId>maven-clean-plugin</artifactId> 6 <version>2.5</version> 7 </plugin> 8 <plugin> 9 <groupId>org.apache.maven.plugins</groupId> 10 <artifactId>maven-source-plugin</artifactId> 11 <version>2.2</version> 12 </plugin> 13 <plugin> 14 <groupId>org.apache.maven.plugins</groupId> 15 <artifactId>maven-compiler-plugin</artifactId> 16 <version>3.0</version> 17 <configuration> 18 <source>1.8</source> 19 <target>1.8</target> 20 <encoding>${file.encoding}</encoding> 21 <!--編譯的時候方法不改變方法參數名稱,用於支持使用反射獲取方法參數名稱--> 22 <compilerArgument>-parameters</compilerArgument> 23 </configuration> 24 </plugin> 25 <plugin> 26 <groupId>org.apache.maven.plugins</groupId> 27 <artifactId>maven-install-plugin</artifactId> 28 <version>2.4</version> 29 </plugin> 30 <plugin> 31 <groupId>org.apache.maven.plugins</groupId> 32 <artifactId>maven-jar-plugin</artifactId> 33 <version>2.4</version> 34 <configuration> 35 <archive> 36 <manifest> 37 <addDefaultImplementationEntries>true 38 </addDefaultImplementationEntries> 39 </manifest> 40 </archive> 41 </configuration> 42 </plugin> 43 44 <plugin> 45 <groupId>org.apache.maven.plugins</groupId> 46 <artifactId>maven-surefire-plugin</artifactId> 47 <version>2.13</version> 48 <configuration> 49 <argLine>-Xmx512M -Dfile.encoding=${file.encoding}</argLine> 50 </configuration> 51 </plugin> 52 </plugins> 53 </build>
運行fteWebApplication類里的main方法,默認端口為8080,訪問http://localhost:8080/demo/test,正常出現以下情況:
按照以上步驟,就可以初步建立SpringBoot多模塊的項目,下一章將基於這個基礎搭建Mybatis以及其逆向工程。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
※回頭車貨運收費標準

大家好~這三個月以來,我一直在學習和實現“基於WebGPU的混合光線追蹤實時渲染”的技術,使用了Ray Tracing管線(如.rgen、.rmiss等着色器)。
現在與大家分享和介紹我目前的學習成果,希望對大家有所幫助!謝謝!
這三個月我對Ray Tracing的研究有了質的突破,主要歸功於我發現的WebGPU Node開源項目!
該作者首先在dawn-ray-tracing開源項目中對“dawn項目:Chrome對WebGPU的實現”進行了擴展,加入了光追的API;
然後在WebGPU Node開源項目中,底層封裝了Vulkan SDK,上層使用了dawn-ray-tracing項目,提供了WebGPU API,實現了在Nodejs環境中使用WebGPU API和Ray Tracing管線來實現硬件加速的光線追蹤(電腦需要使用nvdia的RTX顯卡)!
相關介紹參見:
Real-Time Ray-Tracing in WebGPU
有兩種方法來搭建運行環境:
1、給Chrome瀏覽器打補丁,使其與下載DXR驅動(DirectX Raytracing)關聯,從而在該瀏覽器中運行
詳見該作者最近寫的開源項目:chromium-ray-tracing
(我沒有測試過,不知道是否能使用)
2、編譯dawn-ray-tracing和WebGPU Node項目,從而在Nodejs環境中運行
我使用的是這個方法(不過我使用的WebGPU Node項目是今年3月份時的代碼,最新的代碼我還沒有編譯成功)。
我的操作系統是win7,顯卡是RTX 2060s,vulkan sdk是1.1.126.0版本
/* 最新代碼我還沒有編譯成功哈哈!請先不要進行下面的編譯操作!
編譯的步驟為(需要使用VPN翻牆):
# 編譯dawn-ray-tracing項目
## Clone the repo as "dawn-ray-tracing"
git clone https://github.com/maierfelix/dawn-ray-tracing
cd dawn-ray-tracing
## Bootstrap the gclient configuration
cp scripts/standalone.gclient .gclient
## Fetch external dependencies and toolchains with gclient
gclient sync
set DEPOT_TOOLS_WIN_TOOLCHAIN=0
npm install --global --production windows-build-tools
gn gen out/Shared --ide=vs --target_cpu="x64" --args="is_component_build=true is_debug=false is_clang=false"
ninja -C out/Shared
# 編譯webgpu node項目
npm install webgpu
在webgpu node的根目錄中創建名為“PATH_TO_DAWN”的文件,在其中指定dawn-ray-tracing項目的絕對路徑,如:
D:/Github/dawn-ray-tracing
在webgpu node的根目錄中執行:
npm run all --dawnversion=0.0.1
(
這裏要注意的是,需要先安裝Vulkan SDK和python;
可以通過“npm config set python C:\depot_tools\python.bat”來設置python路徑,或者指定python路徑:
npm run all --dawnversion=0.0.1 --python="C:\Users\Administrator\Downloads\depot_tools\bootstrap-3_8_0_chromium_8_bin\python\bin\python.exe"
)
# 在nodejs中運行ray tracing示例,驗證是否成功
進入webgpu node的根目錄
cd examples & cd ..
node --experimental-modules examples/ray-tracing/index.mjs
*/
考慮到WebGPU還沒有正式發布,並且可能在三年內瀏覽器都不會支持Ray Tracing管線,所以我把渲染放到雲端,這樣就可以在雲端自行搭建環境(如使用WebGPU Node開源項目),然後通過網絡傳輸將渲染結果傳輸到客戶端,從而在客戶端瀏覽器不支持的情況下仍能显示光追渲染的畫面。
因此,我的應用場景為:
1、雲渲染
2、雲遊戲
這兩個應用場景有不同的需求:
“雲渲染”屬於離線渲染,我們關心的是:
因此:
“雲遊戲”屬於實時渲染,我們關心的是:
因此:
主要技術框架是“實時混合光線追蹤”,主要包含下面的pass:
1、gbuffer pass
創建gbuffer
2、ray tracing pass
直接從gbuffer中獲取world position、diffuse等數據,用來計算直接光照,從而減少了每個像素髮射的光線數量;
每個像素髮射1個shadow ray,用來計算直接光照的陰影;
如果只用1個bounce來計算全局光照的話,每個像素髮射1個indirect ray+1個shadow ray,用來計算間接光照。
3、denoise pass
基於BMFR算法來實現降噪,具體可參考本文後面的“實現降噪Denoise”部分。
4、taa pass
使用taa來抗鋸齒
相關代碼可見我的開源項目:
WebGPU-RTX
我通過下面的文章進行了初步的了解:
一篇光線追蹤的入門
光線追蹤與實時渲染的未來
實時光線追蹤技術:業界發展近況與未來挑戰
Introduction to NVIDIA RTX and DirectX Ray Tracing
如何評價微軟的 DXR(DirectX Raytracing)?
通過學習下面的資料:
Ray Tracing in One Weekend
Ray Tracing: The Next Week
Ray Tracing in One Weekend和Ray Tracing: The Next Week的詳解
基於OpenGL的GPU光線追蹤
我參考資料中的代碼,用WebGL 2實現一個Demo:
該場景的紅圈中是一個球,附近有一個球形光源和一個矩形光源
因為沒有進行降噪,所以噪點太多了哈哈!
相關代碼可見我的開源項目:
Wonder-RayTrace
通過學習NVIDIA Vulkan Ray Tracing Tutorial教程,我用 js語言+WebGPU Node開源項目 基於Ray Tracing管線依次實現了陰影、反射等基礎渲染效果。
該教程使用了VK_KHR_ray_tracing擴展,而WebGPU Node開源項目也使用了該擴展(Vulkan SDK),因此該教程的shader代碼幾乎可以直接用到該開源項目中。
教程代碼
我用Reason語言重寫了示例代碼,提煉了一個基礎架構。
因為我希望優先減少渲染時間,所以我要通過混合管線來進行實時渲染。
我通過A Gentle Introduction To DirectX Raytracing教程來學習和實現。
教程代碼下載
我學習了該教程的第一篇到第11篇,分別實現了創建GBuffer、使用Lambertian材質渲染、多光源的陰影等內容。
教程的第9篇通過每個像素對每個光源發射一個shadow ray,最後累加並計算平均值,實現了多光源的陰影。
教程的第11篇對第9篇進行了改進:為了減少每個像素髮射的shadow ray的數量,每個像素只隨機向一個光源發射一個shadow ray。
這樣會導致噪點,如下圖所示:
我們可以通過累計採樣數來不斷逼近無噪點的圖片(如該教程的第6篇一樣),但這樣需要經過長時間后才會收斂,所以只適合“雲渲染”這種離線渲染的應用場景。
累加一定幀數后,結果如下圖所示:
降噪算法通常需要先實現“幀間的數據復用”,而TAA抗鋸齒也需要實現“幀間數據復用”的技術;而且降噪算法會使用TAA作為最後一個pass來抗鋸齒。所以我決定先實現taa,將其作為實現降噪算法的鋪墊。
我參考了下面的資料來實現taa:
DX12渲染管線(2) – 時間性抗鋸齒(TAA)、 相關代碼
Unity Temporal AA的改進與提高、 相關代碼
unit Temporal Anti-Aliasing
為了能應用於“雲遊戲”這種實時渲染的應用場景,我們需要快速降噪。因此我實現了BMFR算法來降噪。
降噪前場景:
降噪后場景:
我參考了下面的資料:
BLOCKWISE MULTI-ORDER FEATURE REGRESSION FOR REAL-TIME PATH TRACING RECONSTRUCTION
參考代碼
教程的第11篇隨機向一個光源發射一個shadow ray,這其實已經使用了蒙特卡羅積分的理論。
我們可以通過下面的資料深入學習該理論,了解概率密度函數(pdf)、重要性採樣等相關概念,為我們後面實現全局光照打下理論基礎:
【RAY TRACING THE REST OF YOUR LIFE 超詳解】 光線追蹤 3-1 蒙特卡羅 (一) 到 【RAY TRACING THE REST OF YOUR LIFE 超詳解】 光線追蹤 3-7 混合概率密
光線追蹤器Ray Tracer:進階篇
通過學習教程的第12篇,我實現了one bounce的全局光照。
更多參考資料:
Global Illumination and Path Tracing
Global Illumination and Monte Carlo
這裏我遇到的問題主要是處理indirect specular noise:噪點不穩定,導致降噪后不穩定(高光周圍有明顯波動)。
我首先以為是pdf寫錯了,結果修改了pdf后還是沒有改進;
然後希望通過clamp等方法移除這些高光的fireflies噪點,結果影響到了畫質;
最後採用了“採樣indirect specular/diffuse多次”來穩定噪點。這適用於“雲渲染”的離線渲染,但不適用於“雲遊戲”的實時渲染。
通過學習教程的第14篇,我引入了pbr材質,實現了GGX模型,加入了多bounce的全局光照。
我對教程代碼進行了改進:
在.rgen着色器中使用for循環而不是遞歸來實現的多bounce;
實現了disney BRDF,在pbr材質中有diffuse、roughness、metallic、specular這幾個參數。
更多參考資料:
基於物理着色(二)- Microfacet材質和多層材質
基於物理着色(三)- Disney和UE4的實現
基於物理的渲染(PBR)白皮書 | 迪士尼原則的BRDF與BSDF相關總結
WebGPU-Path-Tracer 實現了disney BRDF
使用bindless texture或者virtual texture來實現
如gamma矯正等
雲端天然具有并行的優勢,因此可將渲染任務分配到多個顯卡/服務器中執行。
BMFR對高光specular處理得不好。
為了應用在“雲渲染”中,需要提高畫質。因此可考慮:
現在我通過增加spp來增加噪點的穩定性,這在“雲遊戲”中行不通,因為只能有1 spp。因此可考慮:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※新北清潔公司,居家、辦公、裝潢細清專業服務

之前在刷筆試題和面試的時候經常會遇到或者被問到 try-catch-finally 語法塊的執行順序等問題,今天就抽空整理了一下這個知識點,然後記錄下來。
本篇文章主要是通過舉例的方式來闡述各種情況,我這裏根據 try-catch-finally 語法塊分為兩種大情況討論:try-catch 語法塊和 try-catch-finally 語句塊,然後再在每種情況里再去具體討論。
我們可以看看下面程序:
public static void main(String[] args) {
System.out.println(handleException0());
}
/**
* try,catch都有return
* @return
*/
private static String handleException0() {
try{
System.out.println("try開始");
String s = null;
int length = s.charAt(0);
System.out.println("try結束");
return "try塊的返回值";
}catch (Exception e){
System.out.println("捕獲到了異常");
return "catch的返回值";
}
}
執行結果:
try開始
捕獲到了異常
catch的返回值
分析:程序首先執行 try 塊裏面的代碼,try 塊裏面發現有異常,try 塊後面的代碼不會執行(自然也不會return),然後進入匹配異常的那個 catch 塊,然後進入 catch 塊裏面將代碼執行完畢,當執行到 catch 裏面的return 語句的時候,程序中止,然後將此 return 的最終結果返回回去。
這種語法塊我分為了 4 種情況討論,下面進行一一列舉。
1、第一種情況,try 塊裏面有 return 的情況,並且捕獲到異常
例1:
public static void main(String[] args) {
String result = handleException1();
System.out.println(result);
}
private static String handleException1() {
try{
System.out.println("try開始");
String str = null;
int length = str.length();
System.out.println("try結束");
}catch (Exception e){
System.out.println("捕獲到了異常");
}finally {
System.out.println("finally塊執行完畢了");
}
return "最終的結果";
}
例1執行的結果如下:
try開始
捕獲到了異常
finally塊執行完畢了
最終的結果
例2:
public static void main(String[] args) {
String result = handleException2();
System.out.println(result);
}
private static String handleException2() {
try{
System.out.println("try開始");
String str = null;
int length = str.length();
System.out.println("try結束");
return "try塊的返回值";
}catch (Exception e){
System.out.println("捕獲到了異常");
}finally {
System.out.println("finally塊執行完畢了");
}
return "最終的結果";
}
例2的執行結果如下:
try開始
捕獲到了異常
finally塊執行完畢了
最終的結果
分析:首先 例1 和 例2 的結果是很顯然的,當遇到異常的時候,直接進入匹配到相對應的 catch 塊,然後繼續執行 finallly 語句塊,最後將 return 結果返回回去。
第二種情況:try塊裏面有return的情況,但是不會捕獲到異常
例3:
思考:下面代碼try語句塊中有return語句,那麼是否執行完try語句塊就直接return退出方法了呢?
public static void main(String[] args) {
String result = handleException3();
System.out.println(result);
}
private static String handleException3() {
try{
System.out.println("");
return "try塊的返回值";
}catch (Exception e){
System.out.println("捕獲到了異常");
}finally {
System.out.println("finally塊執行完畢了");
}
return "最終的結果";
}
例3的執行結果如下:
finally塊執行完畢了
try塊的返回值
分析:例3的結果其實我們可以通過打斷點的方式去看看程序的具體執行流程,通過打斷點我們可以發現,代碼先執行 try塊 里的代碼,當執行到 return 語句的時候,handleException3方法並沒有立刻結束,而是繼續執行finally塊里的代碼,finally塊里的代碼執行完后,緊接着回到 try 塊的 return 語句,再把最終結果返回回去, handleException 方法執行完畢。
第三種情況:try塊和finally裏面都有return的情況
例4:
public static void main(String[] args) {
System.out.println(handleException4());
}
/**
* 情況3:try和finally中均有return
* @return
*/
private static String handleException4() {
try{
System.out.println("");
return "try塊的返回值";
}catch (Exception e){
System.out.println("捕獲到了異常");
}finally {
System.out.println("finally塊執行完畢了");
return "finally的返回值";
}
// return "最終的結果";//不能再有返回值
}
例4的執行結果:
finally塊執行完畢了
finally的返回值
分析:需要注意的是,當 try 塊和 finally 裏面都有 return 的時候,在 try/catch/finally 語法塊之外不允許再有return 關鍵字。我們還是通過在程序中打斷點的方式來看看代碼的具體執行流程。代碼首先執行 try 塊 里的代碼,當執行到 return 語句的時候,handleException4 方法並沒有立刻結束,而是繼續執行 finally 塊里的代碼,當發現 finally 塊里有 return 的時候,直接將 finally 里的返回值(也就是最終結果)返回回去, handleException4 方法執行完畢。
第四種情況:try塊,catch塊,finally塊都有return
例5:
public static void main(String[] args) {
System.out.println(handleException5());
}
/**
* 情況4:try,catch,finally都有return
* @return
*/
private static String handleException5() {
try{
System.out.println("try開始");
int[] array = {1, 2, 3};
int i = array[10];
System.out.println("try結束");
return "try塊的返回值";
}catch (Exception e){
e.printStackTrace();//這行代碼其實就是打印輸出異常的具體信息
System.out.println("捕獲到了異常");
return "catch的返回值";
}finally {
System.out.println("finally塊執行完畢了");
return "finally的返回值";
}
// return "最終的結果";
}
例5的執行結果:
try開始
捕獲到了異常
finally塊執行完畢了
finally的返回值
java.lang.ArrayIndexOutOfBoundsException: 10
at com.example.javabasic.javabasic.ExceptionAndError.TryCatchFinally.handleException5(TryCatchFinally.java:25)
at com.example.javabasic.javabasic.ExceptionAndError.TryCatchFinally.main(TryCatchFinally.java:14)
分析:程序首先執行try塊裏面的代碼,try塊裏面發現有異常,try塊後面的代碼不會執行(自然也不會return),然後進入匹配異常的那個catch塊,然後進入catch塊裏面將代碼執行完畢,當執行到catch裏面的return語句的時候,程序不會馬上終止,而是繼續執行finally塊的代碼,最後執行finally裏面的return,然後將此return的最終結果返回回去。
其實,我們通過以上例子我們可以發現,不管return關鍵字在哪,finally一定會執行完畢。理論上來說try、catch、finally塊中都允許書寫return關鍵字,但是執行優先級較低的塊中的return關鍵字定義的返回值將覆蓋執行優先級較高的塊中return關鍵字定義的返回值。也就是說finally塊中定義的返回值將會覆蓋catch塊、try塊中定義的返回值;catch塊中定義的返回值將會覆蓋try塊中定義的返回值。
再換句話說如果在finally塊中通過return關鍵字定義了返回值,那麼之前所有通過return關鍵字定義的返回值都將失效——因為finally塊中的代碼一定是會執行的。
公眾號:良許Linux
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※幫你省時又省力,新北清潔一流服務好口碑
※別再煩惱如何寫文案,掌握八大原則!
系統重新學習C++語言部分,記錄重要但易被忽略的,關鍵但易被遺忘的。
1、拋出異常類時,雖然catch的是一個引用,但是也會產生一次拷貝,因為當拋出異常的函數在棧解退的過程中會會調用異常類的析構函數,異常類將不復存在。
2、如果有一個異常類層次結構,應該這樣排列catch塊:將捕獲位於層次結構最下面的異常類的catch語句放在最前面,將捕獲基類異常的catch語句放在最後面。拋出異常的順序要與catch塊相反。
3、在catch語句中使用基類對象時,將捕獲所有的派生類對象,但派生類特性將被剝去,因此將使用虛方法的基類版本。
4、 將dynamic_cast用於引用時,由於沒有與空指針對應的引用值,因此無法使用特殊的引用值來表示失敗,當請求不正確時,將引發bad_cast的異常。
5、reinterpret_cast運算符並不支持所有的類型轉換,例如,可以將指針類型轉換為足以存儲指針的整數,但不能將指針轉換為更小的整型或浮點型。另一個限制是,不能將函數指針和數據指針互相轉換。
6、使用new分配內存時,可以使用auto_ptr、unique_ptr、shared_ptr、但只有unique_ptr有使用new[]和delete[]的版本。
7、在unique_ptr為右值時,可以將其賦值給shared_ptr,模板shared_ptr包含一個顯式構造函數,可以用於將右值unique_ptr轉換為shared_ptr。
8、對於所有內置的算術運算符、關係運算符和邏輯運算符,STL都提供了等價的函數符(仿函數)。
9、valarray模板類重載了許多運算符,可以直接參与大多數數值運算;slice類可用作數組索引,它接受三個值初始值:起始索引、索引數、跨距。
1 valarry<double> arr(10); 2 arr[slice(1,4,3)] = 10;
slice(1,4,3)創建的對象表示選擇4個索引,這可以將arr的第1、4、7、10個元素都設置為10。
10、迭代器類型
| Input iterator(輸入迭代器) | 讀,不能寫;只支持自增運算 |
| Output iterator(輸出迭代器) | 寫,不能讀;只支持自增運算 |
| Forward iterator(前向迭代器) | 讀和寫;只支持自增運算 |
| Bidirectional iterator(雙向迭代器) | 讀和寫;支持自增和自減運算 |
| Random access iterator(隨機訪問迭代器) | 讀和寫;支持完整的迭代器算術運算 |
11、對於標準錯誤輸出,是沒有緩衝區的。
12、在使用cout時,可以使用成員函數width()設置下一次輸出時的字段寬度,默認右對齊並以空格填充空白字段,當字段寬度不足時,C++不對截斷輸出寬度;使用成員函數fill()用來填充空白字段;使用成員函數precision()來設置浮點數輸出精度;成員函數setf()與unsetf()提供了更豐富的輸出格式設置方法,但使用標準控制符將更加簡單。
13、對於cin的get()方法和getline()方法來說,如果沒有讀取到任何字符(getline()將換行符視為一個字符),則設置failbit;如果讀取了最大數目的字符,但行中還有其他字符,getline()將設置failbit。
14、cin的peak()方法可以查看輸入流中的下一個字符,gcount()方法可以返回最後一個非格式化抽取方法讀取的字符數,putback()方法可以將字符插入到輸入字符串中。
15、fstream類中的方法seekg()和seekp()分別將輸入指針和輸出指針移到指定的文件位置,事實上,由於fstream類使用緩衝區來存儲中間數據,因此指針指向的是緩衝區中的位置,而不是實際的文件。
16、fstream類中的方法tellg()和tellp()方法分別返回輸入流、輸出流當前指針的位置,對於fstream對象,輸入輸出指針將一前一后地移動,因此它們的返回值相同。但對於使用istream對象來管理輸入流,而使用ostream對象來管理同一個文件的輸出流,則輸入指針和輸出指針將彼此獨立的移動。
17、關於如何生成臨時文件,使用tmpnam()可以生產TMP_NAM個不同的文件名,其中每個文件名包含的字符不超過L_tmpnam個。
18、C++庫還提供了sstream族(包含ostringstream類和istringstream類),它們使用相同的接口提供程序和string對象之間的IO。
19、新標準引入的移動語義,用來修飾六個特殊函數的default關鍵字,用來刪除任意成員函數的delete關鍵字,以及使用類似初始化列表的方式在一個構造函數中使用另一個構造函數(被稱為委託構造),以及使用using 類名::函數名,使基類所有的非特殊成員函數對派生類可以用(繼承構造函數),以及显示聲明重寫(覆蓋)某個虛函數的標識符override,以及禁止派生類覆蓋特定的虛函數標識符final。
20、C++11引入lambda表達的主要目的是能夠將類似於函數的表達式用作接受函數指針或函數符的函數的參數。
21、C++提供了多個包裝器對象,用於給其他編程接口提供更一致或更合適的接口。C++11提供了包括模板bind(替代bind1st和bind2nd)、men_fn(將成員函數作為常規函數傳遞)和reference_wrapper(創建行為像引用但可被複制的對象)以及funtion(以統一的方式處理多種類似於函數的形式,使用模板時可減少可執行代碼的規模)。
22、正確使用遞歸實現可變參數模板。
23、C++11增加了對并行編程的支持,以及相當多的新增庫等。
24、C++允許定義指向類成員(包括數據和函數)的指針,這種語法需要使用到成員解除引用運算符(* 、->*)。
25、C++11新增了alignof運算符,它接受一個類型作為參數,返回這個類型的對齊方式;noexcept關鍵字用於指出函數不會引發異常,它也可以用作運算符,判斷表達式是否可能引發異常,不引發返回true。
26、STL提供了豐富的全局函數,包括查詢,排序,複製等一系列算法。
2020年6月2日,星期二,凌晨2點01分,首次完整讀完這本書,共勉。
學如逆水行舟,不進則退;心似平原放馬,易縱難收。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※新北清潔公司,居家、辦公、裝潢細清專業服務
※推薦評價好的iphone維修中心