上篇文章準備了離線安裝 OCP 所需要的離線資源,包括安裝鏡像、所有樣例 Image Stream 和 OperatorHub 中的所有 RedHat Operators。本文就開始正式安裝 OCP(Openshift Container Platform) 集群,包括 DNS 解析、負載均衡配置、ignition 配置文件生成和集群部署。
OCP 安裝期間需要用到多個文件:安裝配置文件、Kubernetes 部署清單、Ignition 配置文件(包含了 machine types)。安裝配置文件將被轉換為 Kubernetes 部署清單,然後將清單包裝到 Ignition 配置文件中。 安裝程序使用這些 Ignition 配置文件來創建 Openshift 集群。運行安裝程序時,所有原始安裝配置文件都會修改,因此在安裝之前應該先備份文件。
1. 安裝過程
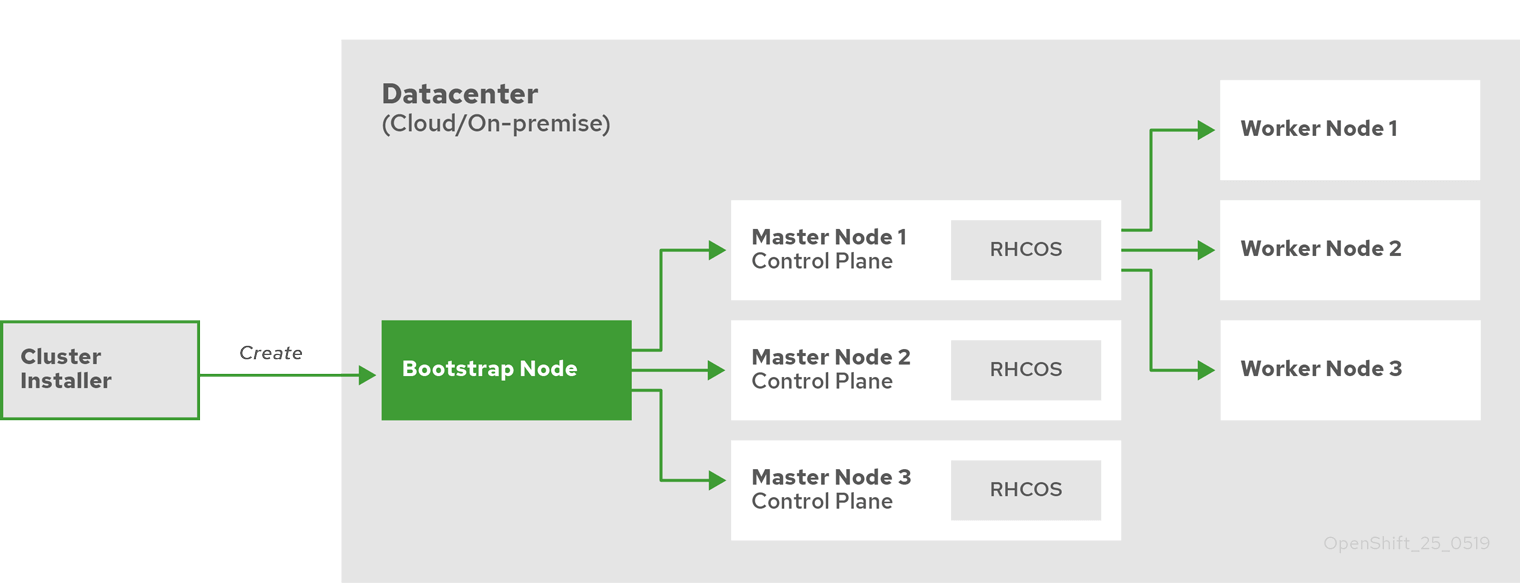
在安裝 OCP 時,我們需要有一台引導主機(Bootstrap)。這個主機可以訪問所有的 OCP 節點。引導主機啟動一個臨時控制平面,它啟動 OCP 集群的其餘部分然後被銷毀。引導主機使用 Ignition 配置文件進行集群安裝引導,該文件描述了如何創建 OCP 集群。安裝程序生成的 Ignition 配置文件包含 24 小時後過期的證書,所以必須在證書過期之前完成集群安裝。
引導集群安裝包括如下步驟:
- 引導主機啟動並開始託管
Master 節點啟動所需的資源。
Master 節點從引導主機遠程獲取資源並完成引導。Master 節點通過引導主機構建 Etcd 集群。- 引導主機使用新的
Etcd 集群啟動臨時 Kubernetes 控制平面。
- 臨時控制平面在 Master 節點啟動生成控制平面。
- 臨時控制平面關閉並將控制權傳遞給生產控制平面。
- 引導主機將 OCP 組件注入生成控制平面。
- 安裝程序關閉引導主機。
引導安裝過程完成以後,OCP 集群部署完畢。然後集群開始下載並配置日常操作所需的其餘組件,包括創建計算節點、通過 Operator 安裝其他服務等。
2. 準備服務器資源
服務器規劃如下:
- 三個控制平面節點,安裝
Etcd、控制平面組件和 Infras 基礎組件。
- 兩個計算節點,運行實際負載。
- 一個引導主機,執行安裝任務,集群部署完成后可刪除。
- 一個基礎節點,用於準備上節提到的離線資源,同時用來部署 DNS 和負載均衡。
- 一個鏡像節點,用來部署私有鏡像倉庫
Quay。
| 主機類型 |
操作系統 |
Hostname |
vCPU |
內存 |
存儲 |
IP |
FQDN |
| 鏡像節點 |
RHEL 7.6 |
registry |
4 |
8GB |
150GB |
192.168.57.70 |
registry.openshift4.example.com |
| 基礎節點 |
RHEL 7.6 |
bastion |
4 |
16GB |
120GB |
192.168.57.60 |
bastion.openshift4.example.com |
| 引導主機 |
RHCOS |
bootstrap |
4 |
16GB |
120GB |
192.168.57.61 |
bootstrap.openshift4.example.com |
| 控制平面 |
RHCOS |
master1 |
4 |
16GB |
120GB |
192.168.57.62 |
master1.openshift4.example.com |
| 控制平面 |
RHCOS |
master2 |
4 |
16GB |
120GB |
192.168.57.63 |
master2.openshift4.example.com |
| 控制平面 |
RHCOS |
master3 |
4 |
16GB |
120GB |
192.168.57.64 |
master3.openshift4.example.com |
| 計算節點 |
RHCOS 或 RHEL 7.6 |
worker1 |
2 |
8GB |
120GB |
192.168.57.65 |
worker1.openshift4.example.com |
| 計算節點 |
RHCOS 或 RHEL 7.6 |
worker2 |
2 |
8GB |
120GB |
192.168.57.66 |
worke2.openshift4.example.com |
3. 防火牆配置
接下來看一下每個節點的端口號分配。
所有節點(計算節點和控制平面)之間需要開放的端口:
| 協議 |
端口 |
作用 |
| ICMP |
N/A |
測試網絡連通性 |
| TCP |
9000-9999 |
節點的服務端口,包括 node exporter 使用的 9100-9101 端口和 Cluster Version Operator 使用的 9099 端口 |
|
10250–10259 |
Kubernetes 預留的默認端口 |
|
10256 |
openshift-sdn |
| UDP |
4789 |
VXLAN 協議或 GENEVE 協議的通信端口 |
|
6081 |
VXLAN 協議或 GENEVE 協議的通信端口 |
|
9000–9999 |
節點的服務端口,包括 node exporter 使用的 9100-9101 端口 |
|
30000–32767 |
Kubernetes NodePort |
控制平面需要向其他節點開放的端口:
| 協議 |
端口 |
作用 |
| TCP |
2379–2380 |
Etcd 服務端口 |
|
6443 |
Kubernetes API |
除此之外,還要配置兩個四層負載均衡器,一個用來暴露集群 API,一個用來暴露 Ingress:
| 端口 |
作用 |
內部 |
外部 |
描述 |
6443 |
引導主機和控制平面使用。在引導主機初始化集群控制平面后,需從負載均衡器中手動刪除引導主機 |
x |
x |
Kubernetes API server |
22623 |
引導主機和控制平面使用。在引導主機初始化集群控制平面后,需從負載均衡器中手動刪除引導主機 |
|
x |
Machine Config server |
443 |
Ingress Controller 或 Router 使用 |
x |
x |
HTTPS 流量 |
80 |
Ingress Controller 或 Router 使用 |
x |
x |
HTTP 流量 |
4. 配置 DNS
按照官方文檔,使用 UPI 基礎架構的 OCP 集群需要以下的 DNS 記錄。在每條記錄中,<cluster_name> 是集群名稱,<base_domain> 是在 install-config.yaml 文件中指定的集群基本域,如下錶所示:
| 組件 |
DNS記錄 |
描述 |
| Kubernetes API |
api.<cluster_name>.<base_domain>. |
此 DNS 記錄必須指向控制平面節點的負載均衡器。此記錄必須可由集群外部的客戶端和集群中的所有節點解析。 |
|
api-int.<cluster_name>.<base_domain>. |
此 DNS 記錄必須指向控制平面節點的負載均衡器。此記錄必須可由集群外部的客戶端和集群中的所有節點解析。 |
| Routes |
*.apps.<cluster_name>.<base_domain>. |
DNS 通配符記錄,指向負載均衡器。這個負載均衡器的後端是 Ingress router 所在的節點,默認是計算節點。此記錄必須可由集群外部的客戶端和集群中的所有節點解析。 |
| etcd |
etcd-<index>.<cluster_name>.<base_domain>. |
OCP 要求每個 etcd 實例的 DNS 記錄指向運行實例的控制平面節點。etcd 實例由 值區分,它們以 0 開頭,以 n-1 結束,其中 n 是集群中控制平面節點的數量。集群中的所有節點必須都可以解析此記錄。 |
|
_etcd-server-ssl._tcp.<cluster_name>.<base_domain>. |
因為 etcd 使用端口 2380 對外服務,因此需要建立對應每台 etcd 節點的 SRV DNS 記錄,優先級 0,權重 10 和端口 2380 |
DNS 服務的部署方法由很多種,我當然推薦使用 CoreDNS,畢竟雲原生標配。由於這裏需要添加 SRV 記錄,所以需要 CoreDNS 結合 etcd 插件使用。以下所有操作在基礎節點上執行。
首先通過 yum 安裝並啟動 etcd:
$ yum install -y etcd
$ systemctl enable etcd --now
然後下載 CoreDNS 二進制文件:
$ wget https://github.com/coredns/coredns/releases/download/v1.6.9/coredns_1.6.9_linux_amd64.tgz
$ tar zxvf coredns_1.6.9_linux_amd64.tgz
$ mv coredns /usr/local/bin
創建 Systemd Unit 文件:
$ cat > /etc/systemd/system/coredns.service <<EOF
[Unit]
Description=CoreDNS DNS server
Documentation=https://coredns.io
After=network.target
[Service]
PermissionsStartOnly=true
LimitNOFILE=1048576
LimitNPROC=512
CapabilityBoundingSet=CAP_NET_BIND_SERVICE
AmbientCapabilities=CAP_NET_BIND_SERVICE
NoNewPrivileges=true
User=coredns
WorkingDirectory=~
ExecStart=/usr/local/bin/coredns -conf=/etc/coredns/Corefile
ExecReload=/bin/kill -SIGUSR1 $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
新建 coredns 用戶:
$ useradd coredns -s /sbin/nologin
新建 CoreDNS 配置文件:
$ cat > /etc/coredns/Corefile <<EOF
.:53 { # 監聽 TCP 和 UDP 的 53 端口
template IN A apps.openshift4.example.com {
match .*apps\.openshift4\.example\.com # 匹配請求 DNS 名稱的正則表達式
answer "{{ .Name }} 60 IN A 192.168.57.60" # DNS 應答
fallthrough
}
etcd { # 配置啟用 etcd 插件,後面可以指定域名,例如 etcd test.com {
path /skydns # etcd 裏面的路徑 默認為 /skydns,以後所有的 dns 記錄都存儲在該路徑下
endpoint http://localhost:2379 # etcd 訪問地址,多個空格分開
fallthrough # 如果區域匹配但不能生成記錄,則將請求傳遞給下一個插件
# tls CERT KEY CACERT # 可選參數,etcd 認證證書設置
}
prometheus # 監控插件
cache 160
loadbalance # 負載均衡,開啟 DNS 記錄輪詢策略
forward . 192.168.57.1
log # 打印日誌
}
EOF
其中 template 插件用來實現泛域名解析。
啟動 CoreDNS 並設置開機自啟:
$ systemctl enable coredns --now
驗證泛域名解析:
$ dig +short apps.openshift4.example.com @127.0.0.1
192.168.57.60
$ dig +short x.apps.openshift4.example.com @127.0.0.1
192.168.57.60
添加其餘 DNS 記錄:
$ alias etcdctlv3='ETCDCTL_API=3 etcdctl'
$ etcdctlv3 put /skydns/com/example/openshift4/api '{"host":"192.168.57.60","ttl":60}'
$ etcdctlv3 put /skydns/com/example/openshift4/api-int '{"host":"192.168.57.60","ttl":60}'
$ etcdctlv3 put /skydns/com/example/openshift4/etcd-0 '{"host":"192.168.57.62","ttl":60}'
$ etcdctlv3 put /skydns/com/example/openshift4/etcd-1 '{"host":"192.168.57.63","ttl":60}'
$ etcdctlv3 put /skydns/com/example/openshift4/etcd-2 '{"host":"192.168.57.64","ttl":60}'
$ etcdctlv3 put /skydns/com/example/openshift4/_tcp/_etcd-server-ssl/x1 '{"host":"etcd-0.openshift4.example.com","ttl":60,"priority":0,"weight":10,"port":2380}'
$ etcdctlv3 put /skydns/com/example/openshift4/_tcp/_etcd-server-ssl/x2 '{"host":"etcd-1.openshift4.example.com","ttl":60,"priority":0,"weight":10,"port":2380}'
$ etcdctlv3 put /skydns/com/example/openshift4/_tcp/_etcd-server-ssl/x3 '{"host":"etcd-2.openshift4.example.com","ttl":60,"priority":0,"weight":10,"port":2380}'
# 除此之外再添加各節點主機名記錄
$ etcdctlv3 put /skydns/com/example/openshift4/bootstrap '{"host":"192.168.57.61","ttl":60}'
$ etcdctlv3 put /skydns/com/example/openshift4/master1 '{"host":"192.168.57.62","ttl":60}'
$ etcdctlv3 put /skydns/com/example/openshift4/master2 '{"host":"192.168.57.63","ttl":60}'
$ etcdctlv3 put /skydns/com/example/openshift4/master3 '{"host":"192.168.57.64","ttl":60}'
$ etcdctlv3 put /skydns/com/example/openshift4/worker1 '{"host":"192.168.57.65","ttl":60}'
$ etcdctlv3 put /skydns/com/example/openshift4/worker2 '{"host":"192.168.57.66","ttl":60}'
$ etcdctlv3 put /skydns/com/example/openshift4/registry '{"host":"192.168.57.70","ttl":60}'
驗證 DNS 解析:
$ yum install -y bind-utils
$ dig +short api.openshift4.example.com @127.0.0.1
192.168.57.60
$ dig +short api-int.openshift4.example.com @127.0.0.1
192.168.57.60
$ dig +short etcd-0.openshift4.example.com @127.0.0.1
192.168.57.62
$ dig +short etcd-1.openshift4.example.com @127.0.0.1
192.168.57.63
$ dig +short etcd-2.openshift4.example.com @127.0.0.1
192.168.57.64
$ dig +short -t SRV _etcd-server-ssl._tcp.openshift4.example.com @127.0.0.1
10 33 2380 etcd-0.openshift4.example.com.
10 33 2380 etcd-1.openshift4.example.com.
10 33 2380 etcd-2.openshift4.example.com.
$ dig +short bootstrap.openshift4.example.com @127.0.0.1
192.168.57.61
$ dig +short master1.openshift4.example.com @127.0.0.1
192.168.57.62
$ dig +short master2.openshift4.example.com @127.0.0.1
192.168.57.63
$ dig +short master3.openshift4.example.com @127.0.0.1
192.168.57.64
$ dig +short worker1.openshift4.example.com @127.0.0.1
192.168.57.65
$ dig +short worker2.openshift4.example.com @127.0.0.1
192.168.57.66
5. 配置負載均衡
負載均衡我選擇使用 Envoy,先準備配置文件:
Bootstrap
# /etc/envoy/envoy.yaml
node:
id: node0
cluster: cluster0
dynamic_resources:
lds_config:
path: /etc/envoy/lds.yaml
cds_config:
path: /etc/envoy/cds.yaml
admin:
access_log_path: "/dev/stdout"
address:
socket_address:
address: "0.0.0.0"
port_value: 15001
LDS
# /etc/envoy/lds.yaml
version_info: "0"
resources:
- "@type": type.googleapis.com/envoy.config.listener.v3.Listener
name: listener_openshift-api-server
address:
socket_address:
address: 0.0.0.0
port_value: 6443
filter_chains:
- filters:
- name: envoy.tcp_proxy
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.tcp_proxy.v3.TcpProxy
stat_prefix: openshift-api-server
cluster: openshift-api-server
access_log:
name: envoy.access_loggers.file
typed_config:
"@type": type.googleapis.com/envoy.extensions.access_loggers.file.v3.FileAccessLog
path: /dev/stdout
- "@type": type.googleapis.com/envoy.config.listener.v3.Listener
name: listener_machine-config-server
address:
socket_address:
address: "::"
ipv4_compat: true
port_value: 22623
filter_chains:
- filters:
- name: envoy.tcp_proxy
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.tcp_proxy.v3.TcpProxy
stat_prefix: machine-config-server
cluster: machine-config-server
access_log:
name: envoy.access_loggers.file
typed_config:
"@type": type.googleapis.com/envoy.extensions.access_loggers.file.v3.FileAccessLog
path: /dev/stdout
- "@type": type.googleapis.com/envoy.config.listener.v3.Listener
name: listener_ingress-http
address:
socket_address:
address: "::"
ipv4_compat: true
port_value: 80
filter_chains:
- filters:
- name: envoy.tcp_proxy
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.tcp_proxy.v3.TcpProxy
stat_prefix: ingress-http
cluster: ingress-http
access_log:
name: envoy.access_loggers.file
typed_config:
"@type": type.googleapis.com/envoy.extensions.access_loggers.file.v3.FileAccessLog
path: /dev/stdout
- "@type": type.googleapis.com/envoy.config.listener.v3.Listener
name: listener_ingress-https
address:
socket_address:
address: "::"
ipv4_compat: true
port_value: 443
filter_chains:
- filters:
- name: envoy.tcp_proxy
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.tcp_proxy.v3.TcpProxy
stat_prefix: ingress-https
cluster: ingress-https
access_log:
name: envoy.access_loggers.file
typed_config:
"@type": type.googleapis.com/envoy.extensions.access_loggers.file.v3.FileAccessLog
path: /dev/stdout
CDS
# /etc/envoy/cds.yaml
version_info: "0"
resources:
- "@type": type.googleapis.com/envoy.config.cluster.v3.Cluster
name: openshift-api-server
connect_timeout: 1s
type: strict_dns
dns_lookup_family: V4_ONLY
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: openshift-api-server
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 192.168.57.61
port_value: 6443
- endpoint:
address:
socket_address:
address: 192.168.57.62
port_value: 6443
- endpoint:
address:
socket_address:
address: 192.168.57.63
port_value: 6443
- endpoint:
address:
socket_address:
address: 192.168.57.64
port_value: 6443
- "@type": type.googleapis.com/envoy.config.cluster.v3.Cluster
name: machine-config-server
connect_timeout: 1s
type: strict_dns
dns_lookup_family: V4_ONLY
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: machine-config-server
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 192.168.57.61
port_value: 22623
- endpoint:
address:
socket_address:
address: 192.168.57.62
port_value: 22623
- endpoint:
address:
socket_address:
address: 192.168.57.63
port_value: 22623
- endpoint:
address:
socket_address:
address: 192.168.57.64
port_value: 22623
- "@type": type.googleapis.com/envoy.config.cluster.v3.Cluster
name: ingress-http
connect_timeout: 1s
type: strict_dns
dns_lookup_family: V4_ONLY
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: ingress-http
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 192.168.57.65
port_value: 80
- endpoint:
address:
socket_address:
address: 192.168.57.66
port_value: 80
- "@type": type.googleapis.com/envoy.config.cluster.v3.Cluster
name: ingress-https
connect_timeout: 1s
type: strict_dns
dns_lookup_family: V4_ONLY
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: ingress-https
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 192.168.57.65
port_value: 443
- endpoint:
address:
socket_address:
address: 192.168.57.66
port_value: 443
配置看不懂的去看我的电子書:Envoy 中文指南
啟動 Envoy:
$ podman run -d --restart=always --name envoy --net host -v /etc/envoy:/etc/envoy envoyproxy/envoy
6. 安裝準備
生成 SSH 私鑰並將其添加到 agent
在安裝過程中,我們會在基礎節點上執行 OCP 安裝調試和災難恢復,因此必須在基礎節點上配置 SSH key,ssh-agent 將會用它來執行安裝程序。
基礎節點上的 core 用戶可以使用該私鑰登錄到 Master 節點。部署集群時,該私鑰會被添加到 core 用戶的 ~/.ssh/authorized_keys 列表中。
密鑰創建步驟如下:
① 創建無密碼驗證的 SSH key:
$ ssh-keygen -t rsa -b 4096 -N '' -f ~/.ssh/new_rsa
② 啟動 ssh-agent 進程作為後台任務:
$ eval "$(ssh-agent -s)"
③ 將 SSH 私鑰添加到 ssh-agent:
$ ssh-add ~/.ssh/new_rsa
後續集群安裝過程中,有一步會提示輸入 SSH public key,屆時使用前面創建的公鑰 new_rsa.pub 就可以了。
獲取安裝程序
如果是在線安裝,還需要在基礎節點上下載安裝程序。但這裡是離線安裝,安裝程序在上篇文章中已經被提取出來了,所以不需要再下載。
創建安裝配置文件
首先創建一個安裝目錄,用來存儲安裝所需要的文件:
$ mkdir /ocpinstall
自定義 install-config.yaml 並將其保存在 /ocpinstall 目錄中。配置文件必須命名為 install-config.yaml。配置文件內容:
apiVersion: v1
baseDomain: example.com
compute:
- hyperthreading: Enabled
name: worker
replicas: 0
controlPlane:
hyperthreading: Enabled
name: master
replicas: 3
metadata:
name: openshift4
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
networkType: OpenShiftSDN
serviceNetwork:
- 172.30.0.0/16
platform:
none: {}
fips: false
pullSecret: '{"auths": ...}'
sshKey: 'ssh-rsa ...'
additionalTrustBundle: |
-----BEGIN CERTIFICATE-----
省略,注意這裏要前面空兩格
-----END CERTIFICATE-----
imageContentSources:
- mirrors:
- registry.openshift4.example.com/ocp4/openshift4
source: quay.io/openshift-release-dev/ocp-release
- mirrors:
- registry.openshift4.example.com/ocp4/openshift4
source: quay.io/openshift-release-dev/ocp-v4.0-art-dev
- baseDomain : 所有 Openshift 內部的 DNS 記錄必須是此基礎的子域,並包含集群名稱。
- compute : 計算節點配置。這是一個數組,每一個元素必須以連字符
- 開頭。
- hyperthreading : Enabled 表示啟用同步多線程或超線程。默認啟用同步多線程,可以提高機器內核的性能。如果要禁用,則控制平面和計算節點都要禁用。
- compute.replicas : 計算節點數量。因為我們要手動創建計算節點,所以這裏要設置為 0。
- controlPlane.replicas : 控制平面節點數量。控制平面節點數量必須和 etcd 節點數量一致,為了實現高可用,本文設置為 3。
- metadata.name : 集群名稱。即前面 DNS 記錄中的
<cluster_name>。
- cidr : 定義了分配 Pod IP 的 IP 地址段,不能和物理網絡重疊。
- hostPrefix : 分配給每個節點的子網前綴長度。例如,如果將
hostPrefix 設置為 23,則為每一個節點分配一個給定 cidr 的 /23 子網,允許 \(510 (2^{32 – 23} – 2)\) 個 Pod IP 地址。
- serviceNetwork : Service IP 的地址池,只能設置一個。
- pullSecret : 上篇文章使用的 pull secret,可通過命令
cat /root/pull-secret.json|jq -c 來壓縮成一行。
- sshKey : 上面創建的公鑰,可通過命令
cat ~/.ssh/new_rsa.pub 查看。
- additionalTrustBundle : 私有鏡像倉庫 Quay 的信任證書,可在鏡像節點上通過命令
cat /data/quay/config/ssl.cert 查看。
- imageContentSources : 來自前面
oc adm release mirror 的輸出結果。
備份安裝配置文件,便於以後重複使用:
$ cd /ocpinstall
$ cp install-config.yaml install-config.yaml.20200604
創建 Kubernetes 部署清單
創建 Kubernetes 部署清單后 install-config.yaml 將被刪除,請務必先備份此文件!
創建 Kubernetes 部署清單文件:
$ openshift-install create manifests --dir=/ocpinstall
修改 manifests/cluster-scheduler-02-config.yml 文件,將 mastersSchedulable 的值設為 flase,以防止 Pod 調度到控制節點。
創建 Ignition 配置文件
創建 Ignition 配置文件后 install-config.yaml 將被刪除,請務必先備份此文件!
$ cp install-config.yaml.20200604 install-config.yaml
$ openshift-install create ignition-configs --dir=/ocpinstall
生成的文件:
├── auth
│ ├── kubeadmin-password
│ └── kubeconfig
├── bootstrap.ign
├── master.ign
├── metadata.json
└── worker.ign
準備一個 HTTP 服務,這裏選擇使用 Nginx:
$ yum install -y nginx
修改 Nginx 的配置文件 /etc/nginx/nginx/.conf,將端口改為 8080(因為負載均衡器已經佔用了 80 端口)。然後啟動 Nginx 服務:
$ systemctl enable nginx --now
將 Ignition 配置文件拷貝到 HTTP 服務的 ignition 目錄:
$ mkdir /usr/share/nginx/html/ignition
$ cp -r *.ign /usr/share/nginx/html/ignition/
獲取 RHCOS 的 BIOS 文件
下載用於裸機安裝的 BIOS 文件,並上傳到 Nginx 的目錄:
$ mkdir /usr/share/nginx/html/install
$ wget https://mirror.openshift.com/pub/openshift-v4/dependencies/rhcos/4.4/latest/rhcos-4.4.3-x86_64-metal.x86_64.raw.gz -O /usr/share/nginx/html/install/rhcos-4.4.3-x86_64-metal.x86_64.raw.gz
獲取 RHCOS 的 ISO 文件
本地下載 RHCOS 的 ISO 文件:https://mirror.openshift.com/pub/openshift-v4/dependencies/rhcos/4.4/latest/rhcos-4.4.3-x86_64-installer.x86_64.iso,然後上傳到 vSphere。步驟如下:
① 首先登陸 vSphere,然後點擊『存儲』。
② 選擇一個『數據存儲』,然後在右邊的窗口中選擇『上載文件』。
③ 選擇剛剛下載的 ISO 文件,上傳到 ESXI 主機。
7. 安裝集群
Bootstrap
最後開始正式安裝集群,先創建 bootstrap 節點虛擬機,操作系統選擇『Red Hat Enterprise Linux 7 (64-Bit)』,並掛載之前上傳的 ISO,按照之前的表格設置 CPU 、內存和硬盤,打開電源,然後按照下面的步驟操作:
① 在 RHCOS Installer 安裝界面按 Tab 鍵進入引導參數配置選項。
② 在默認選項 coreos.inst = yes 之後添加(由於無法拷貝粘貼,請輸入仔細核對后再回車進行):
ip=192.168.57.61::192.168.57.1:255.255.255.0:bootstrap.openshift4.example.com:ens192:none nameserver=192.168.57.60 coreos.inst.install_dev=sda coreos.inst.image_url=http://192.168.57.60:8080/install/rhcos-4.4.3-x86_64-metal.x86_64.raw.gz coreos.inst.ignition_url=http://192.168.57.60:8080/ignition/bootstrap.ign
其中 ip=... 的含義為 ip=$IPADDRESS::$DEFAULTGW:$NETMASK:$HOSTNAMEFQDN:$IFACE:none。
如圖所示:
③ 如果安裝有問題會進入 emergency shell,檢查網絡、域名解析是否正常,如果正常一般是以上參數輸入有誤,reboot 退出 shell 回到第一步重新開始。
安裝成功后從基礎節點通過命令 ssh -i ~/.ssh/new_rsa core@192.168.57.61 登錄 bootstrap 節點,然後驗證:
- 網絡配置是否符合自己的設定:
hostnameip routecat /etc/resolv.conf
- 驗證是否成功啟動 bootstrap 相應服務:
podman ps 查看服務是否以容器方式運行- 使用
ss -tulnp 查看 6443 和 22623 端口是否啟用。
這裏簡單介紹一下 bootstrap 節點的啟動流程,它會先通過 podman 跑一些容器,然後在容器裏面啟動臨時控制平面,這個臨時控制平面是通過 CRIO 跑在容器里的,有點繞。。直接看命令:
$ podman ps -a --no-trunc --sort created --format "{{.Command}}"
start --tear-down-early=false --asset-dir=/assets --required-pods=openshift-kube-apiserver/kube-apiserver,openshift-kube-scheduler/openshift-kube-scheduler,openshift-kube-controller-manager/kube-controller-manager,openshift-cluster-version/cluster-version-operator
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
render --dest-dir=/assets/cco-bootstrap --cloud-credential-operator-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:244ab9d0fcf7315eb5c399bd3fa7c2e662cf23f87f625757b13f415d484621c3
bootstrap --etcd-ca=/assets/tls/etcd-ca-bundle.crt --etcd-metric-ca=/assets/tls/etcd-metric-ca-bundle.crt --root-ca=/assets/tls/root-ca.crt --kube-ca=/assets/tls/kube-apiserver-complete-client-ca-bundle.crt --config-file=/assets/manifests/cluster-config.yaml --dest-dir=/assets/mco-bootstrap --pull-secret=/assets/manifests/openshift-config-secret-pull-secret.yaml --etcd-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:aba3c59eb6d088d61b268f83b034230b3396ce67da4f6f6d49201e55efebc6b2 --kube-client-agent-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:8eb481214103d8e0b5fe982ffd682f838b969c8ff7d4f3ed4f83d4a444fb841b --machine-config-operator-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:31dfdca3584982ed5a82d3017322b7d65a491ab25080c427f3f07d9ce93c52e2 --machine-config-oscontent-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:b397960b7cc14c2e2603111b7385c6e8e4b0f683f9873cd9252a789175e5c4e1 --infra-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:d7862a735f492a18cb127742b5c2252281aa8f3bd92189176dd46ae9620ee68a --keepalived-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:a882a11b55b2fc41b538b59bf5db8e4cfc47c537890e4906fe6bf22f9da75575 --coredns-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:b25b8b2219e8c247c088af93e833c9ac390bc63459955e131d89b77c485d144d --mdns-publisher-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:dea1fcb456eae4aabdf5d2d5c537a968a2dafc3da52fe20e8d99a176fccaabce --haproxy-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:7064737dd9d0a43de7a87a094487ab4d7b9e666675c53cf4806d1c9279bd6c2e --baremetal-runtimecfg-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:715bc48eda04afc06827189883451958d8940ed8ab6dd491f602611fe98a6fba --cloud-config-file=/assets/manifests/cloud-provider-config.yaml --cluster-etcd-operator-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:9f7a02df3a5d91326d95e444e2e249f8205632ae986d6dccc7f007ec65c8af77
render --prefix=cluster-ingress- --output-dir=/assets/ingress-operator-manifests
/usr/bin/cluster-kube-scheduler-operator render --manifest-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:187b9d29fea1bde9f1785584b4a7bbf9a0b9f93e1323d92d138e61c861b6286c --asset-input-dir=/assets/tls --asset-output-dir=/assets/kube-scheduler-bootstrap --config-output-file=/assets/kube-scheduler-bootstrap/config
/usr/bin/cluster-kube-controller-manager-operator render --manifest-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:187b9d29fea1bde9f1785584b4a7bbf9a0b9f93e1323d92d138e61c861b6286c --asset-input-dir=/assets/tls --asset-output-dir=/assets/kube-controller-manager-bootstrap --config-output-file=/assets/kube-controller-manager-bootstrap/config --cluster-config-file=/assets/manifests/cluster-network-02-config.yml
/usr/bin/cluster-kube-apiserver-operator render --manifest-etcd-serving-ca=etcd-ca-bundle.crt --manifest-etcd-server-urls=https://localhost:2379 --manifest-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:187b9d29fea1bde9f1785584b4a7bbf9a0b9f93e1323d92d138e61c861b6286c --manifest-operator-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:718ca346d5499cccb4de98c1f858c9a9a13bbf429624226f466c3ee2c14ebf40 --asset-input-dir=/assets/tls --asset-output-dir=/assets/kube-apiserver-bootstrap --config-output-file=/assets/kube-apiserver-bootstrap/config --cluster-config-file=/assets/manifests/cluster-network-02-config.yml
/usr/bin/cluster-config-operator render --config-output-file=/assets/config-bootstrap/config --asset-input-dir=/assets/tls --asset-output-dir=/assets/config-bootstrap
/usr/bin/cluster-etcd-operator render --etcd-ca=/assets/tls/etcd-ca-bundle.crt --etcd-metric-ca=/assets/tls/etcd-metric-ca-bundle.crt --manifest-etcd-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:aba3c59eb6d088d61b268f83b034230b3396ce67da4f6f6d49201e55efebc6b2 --etcd-discovery-domain=test.example.com --manifest-cluster-etcd-operator-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:9f7a02df3a5d91326d95e444e2e249f8205632ae986d6dccc7f007ec65c8af77 --manifest-setup-etcd-env-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:31dfdca3584982ed5a82d3017322b7d65a491ab25080c427f3f07d9ce93c52e2 --manifest-kube-client-agent-image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:8eb481214103d8e0b5fe982ffd682f838b969c8ff7d4f3ed4f83d4a444fb841b --asset-input-dir=/assets/tls --asset-output-dir=/assets/etcd-bootstrap --config-output-file=/assets/etcd-bootstrap/config --cluster-config-file=/assets/manifests/cluster-network-02-config.yml
render --output-dir=/assets/cvo-bootstrap --release-image=registry.openshift4.example.com/ocp4/openshift4@sha256:4a461dc23a9d323c8bd7a8631bed078a9e5eec690ce073f78b645c83fb4cdf74
/usr/bin/grep -oP Managed /manifests/0000_12_etcd-operator_01_operator.cr.yaml
$ crictl pods
POD ID CREATED STATE NAME NAMESPACE ATTEMPT
17a978b9e7b1e 3 minutes ago Ready bootstrap-kube-apiserver-bootstrap.openshift4.example.com kube-system 24
8a0f79f38787a 3 minutes ago Ready bootstrap-kube-scheduler-bootstrap.openshift4.example.com kube-system 4
1a707da797173 3 minutes ago Ready bootstrap-kube-controller-manager-bootstrap.openshift4.example.com kube-system 4
0461d2caa2753 3 minutes ago Ready cloud-credential-operator-bootstrap.openshift4.example.com openshift-cloud-credential-operator 4
ab6519286f65a 3 minutes ago Ready bootstrap-cluster-version-operator-bootstrap.openshift4.example.com openshift-cluster-version 2
457a7a46ec486 8 hours ago Ready bootstrap-machine-config-operator-bootstrap.openshift4.example.com default 0
e4df49b4d36a1 8 hours ago Ready etcd-bootstrap-member-bootstrap.openshift4.example.com openshift-etcd 0
如果驗證無問題,則可以一邊繼續下面的步驟一邊觀察日誌:journalctl -b -f -u bootkube.service
RHCOS 的默認用戶是 core,如果想獲取 root 權限,可以執行命令 sudo su(不需要輸入密碼)。
Master
控制節點和之前類似,先創建虛擬機,然後修改引導參數,引導參數調整為:
ip=192.168.57.62::192.168.57.1:255.255.255.0:master1.openshift4.example.com:ens192:none nameserver=192.168.57.60 coreos.inst.install_dev=sda coreos.inst.image_url=http://192.168.57.60:8080/install/rhcos-4.4.3-x86_64-metal.x86_64.raw.gz coreos.inst.ignition_url=http://192.168.57.60:8080/ignition/master.ign
控制節點安裝成功後會重啟一次,之後同樣可以從基礎節點通過 SSH 密鑰登錄。
然後重複相同的步驟創建其他兩台控制節點,注意修改引導參數(IP 和主機名)。先不急着創建計算節點,先在基礎節點執行以下命令完成生產控制平面的創建:
$ openshift-install --dir=/ocpinstall wait-for bootstrap-complete --log-level=debug
DEBUG OpenShift Installer 4.4.5
DEBUG Built from commit 15eac3785998a5bc250c9f72101a4a9cb767e494
INFO Waiting up to 20m0s for the Kubernetes API at https://api.openshift4.example.com:6443...
INFO API v1.17.1 up
INFO Waiting up to 40m0s for bootstrapping to complete...
DEBUG Bootstrap status: complete
INFO It is now safe to remove the bootstrap resources
待出現 It is now safe to remove the bootstrap resources 提示之後,從負載均衡器中刪除引導主機,本文使用的是 Envoy,只需從 cds.yaml 中刪除引導主機的 endpoint,然後重新加載就好了。
觀察引導節點的日誌:
$ journalctl -b -f -u bootkube.service
...
Jun 05 00:24:12 bootstrap.openshift4.example.com bootkube.sh[12571]: I0605 00:24:12.108179 1 waitforceo.go:67] waiting on condition EtcdRunningInCluster in etcd CR /cluster to be True.
Jun 05 00:24:21 bootstrap.openshift4.example.com bootkube.sh[12571]: I0605 00:24:21.595680 1 waitforceo.go:67] waiting on condition EtcdRunningInCluster in etcd CR /cluster to be True.
Jun 05 00:24:26 bootstrap.openshift4.example.com bootkube.sh[12571]: I0605 00:24:26.250214 1 waitforceo.go:67] waiting on condition EtcdRunningInCluster in etcd CR /cluster to be True.
Jun 05 00:24:26 bootstrap.openshift4.example.com bootkube.sh[12571]: I0605 00:24:26.306421 1 waitforceo.go:67] waiting on condition EtcdRunningInCluster in etcd CR /cluster to be True.
Jun 05 00:24:29 bootstrap.openshift4.example.com bootkube.sh[12571]: I0605 00:24:29.097072 1 waitforceo.go:64] Cluster etcd operator bootstrapped successfully
Jun 05 00:24:29 bootstrap.openshift4.example.com bootkube.sh[12571]: I0605 00:24:29.097306 1 waitforceo.go:58] cluster-etcd-operator bootstrap etcd
Jun 05 00:24:29 bootstrap.openshift4.example.com podman[16531]: 2020-06-05 00:24:29.120864426 +0000 UTC m=+17.965364064 container died 77971b6ca31755a89b279fab6f9c04828c4614161c2e678c7cba48348e684517 (image=quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:9f7a02df3a5d91326d95e444e2e249f8205632ae986d6dccc7f007ec65c8af77, name=recursing_cerf)
Jun 05 00:24:29 bootstrap.openshift4.example.com bootkube.sh[12571]: bootkube.service complete
Worker
計算節點和之前類似,先創建虛擬機,然後修改引導參數,引導參數調整為:
ip=192.168.57.65::192.168.57.1:255.255.255.0:worker1.openshift4.example.com:ens192:none nameserver=192.168.57.60 coreos.inst.install_dev=sda coreos.inst.image_url=http://192.168.57.60:8080/install/rhcos-4.4.3-x86_64-metal.x86_64.raw.gz coreos.inst.ignition_url=http://192.168.57.60:8080/ignition/worker.ign
計算節點安裝成功后也會重啟一次,之後同樣可以從基礎節點通過 SSH 密鑰登錄。
然後重複相同的步驟創建其他計算節點,注意修改引導參數(IP 和主機名)。
登錄集群
可以通過導出集群 kubeconfig 文件以默認系統用戶身份登錄到集群。kubeconfig 文件包含有關 CLI 用於將客戶端連接到正確的集群和 API Server 的集群信息,該文件在 OCP 安裝期間被創建。
$ mkdir ~/.kube
$ cp /ocpinstall/auth/kubeconfig ~/.kube/config
$ oc whoami
system:admin
批准 CSR
將節點添加到集群時,會為添加的每台節點生成兩個待處理證書籤名請求(CSR)。必須確認這些 CSR 已獲得批准,或者在必要時自行批准。
$ oc get node
NAME STATUS ROLES AGE VERSION
master1.openshift4.example.com Ready master,worker 6h25m v1.17.1
master2.openshift4.example.com Ready master,worker 6h39m v1.17.1
master3.openshift4.example.com Ready master,worker 6h15m v1.17.1
worker1.openshift4.example.com NotReady worker 5h8m v1.17.1
worker2.openshift4.example.com NotReady worker 5h9m v1.17.1
輸出列出了創建的所有節點。查看掛起的證書籤名請求(CSR),並確保添加到集群的每台節點都能看到具有 Pending 或 Approved 狀態的客戶端和服務端請求。針對 Pending 狀態的 CSR 批准請求:
$ oc adm certificate approve xxx
或者執行以下命令批准所有 CSR:
$ oc get csr -ojson | jq -r '.items[] | select(.status == {} ) | .metadata.name' | xargs oc adm certificate approve
Operator 自動初始化
控制平面初始化后,需要確認所有的 Operator 都處於可用的狀態,即確認所有 Operator 的 Available 字段值皆為 True:
$ oc get clusteroperators
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE
authentication 4.4.5 True False False 150m
cloud-credential 4.4.5 True False False 7h7m
cluster-autoscaler 4.4.5 True False False 6h12m
console 4.4.5 True False False 150m
csi-snapshot-controller 4.4.5 True False False 6h13m
dns 4.4.5 True False False 6h37m
etcd 4.4.5 True False False 6h19m
image-registry 4.4.5 True False False 6h12m
ingress 4.4.5 True False False 150m
insights 4.4.5 True False False 6h13m
kube-apiserver 4.4.5 True False False 6h15m
kube-controller-manager 4.4.5 True False False 6h36m
kube-scheduler 4.4.5 True False False 6h36m
kube-storage-version-migrator 4.4.5 True False False 6h36m
machine-api 4.4.5 True False False 6h37m
machine-config 4.4.5 True False False 6h36m
marketplace 4.4.5 True False False 6h12m
monitoring 4.4.5 True False False 6h6m
network 4.4.5 True False False 6h39m
node-tuning 4.4.5 True False False 6h38m
openshift-apiserver 4.4.5 True False False 6h14m
openshift-controller-manager 4.4.5 True False False 6h12m
openshift-samples 4.4.5 True False False 6h11m
operator-lifecycle-manager 4.4.5 True False False 6h37m
operator-lifecycle-manager-catalog 4.4.5 True False False 6h37m
operator-lifecycle-manager-packageserver 4.4.5 True False False 6h15m
service-ca 4.4.5 True False False 6h38m
service-catalog-apiserver 4.4.5 True False False 6h38m
service-catalog-controller-manager 4.4.5 True False False 6h39m
storage 4.4.5 True False False 6h12m
如果 Operator 不正常,需要進行問題診斷和修復。
完成安裝
最後一步,完成集群的安裝,執行以下命令:
$ openshift-install --dir=/ocpinstall wait-for install-complete --log-level=debug
注意最後提示訪問 Web Console 的網址及用戶密碼。如果密碼忘了也沒關係,可以查看文件 /ocpinstall/auth/kubeadmin-password 來獲得密碼。
本地訪問 Web Console,需要添加 hosts:
192.168.57.60 console-openshift-console.apps.openshift4.example.com
192.168.57.60 oauth-openshift.apps.openshift4.example.com
瀏覽器訪問 https://console-openshift-console.apps.openshift4.example.com,輸入上面輸出的用戶名密碼登錄。首次登錄後會提示:
You are logged in as a temporary administrative user. Update the Cluster OAuth configuration to allow others to log in.
我們可以通過 htpasswd 自定義管理員賬號,步驟如下:
① htpasswd -c -B -b users.htpasswd admin xxxxx
② 將 users.htpasswd 文件下載到本地。
③ 在 Web Console 頁面打開 Global Configuration:
然後找到 OAuth,點擊進入,然後添加 HTPasswd 類型的 Identity Providers,並上傳 users.htpasswd 文件。
④ 退出當前用戶,注意要退出到如下界面:
選擇 htpasswd,然後輸入之前創建的用戶名密碼登錄。
如果退出后出現的就是用戶密碼輸入窗口,實際還是 kube:admin 的校驗,如果未出現如上提示,可以手動輸入 Web Console 地址來自動跳轉。
⑤ 登錄后貌似能看到 Administrator 菜單項,但訪問如 OAuth Details 仍然提示:
oauths.config.openshift.io "cluster" is forbidden: User "admin" cannot get resource "oauths" in API group "config.openshift.io" at the cluster scope
因此需要授予集群管理員權限:
$ oc adm policy add-cluster-role-to-user cluster-admin admin
Web Console 部分截圖:
如果想刪除默認賬號,可以執行以下命令:
$ oc -n kube-system delete secrets kubeadmin
8. 參考資料
- OpenShift 4.2 vSphere Install with Static IPs
- OpenShift Container Platform 4.3部署實錄
- Chapter 1. Installing on bare metal
Kubernetes 1.18.2 1.17.5 1.16.9 1.15.12離線安裝包發布地址http://store.lameleg.com ,歡迎體驗。 使用了最新的sealos v3.3.6版本。 作了主機名解析配置優化,lvscare 掛載/lib/module解決開機啟動ipvs加載問題, 修復lvscare社區netlink與3.10內核不兼容問題,sealos生成百年證書等特性。更多特性 https://github.com/fanux/sealos 。歡迎掃描下方的二維碼加入釘釘群 ,釘釘群已經集成sealos的機器人實時可以看到sealos的動態。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準