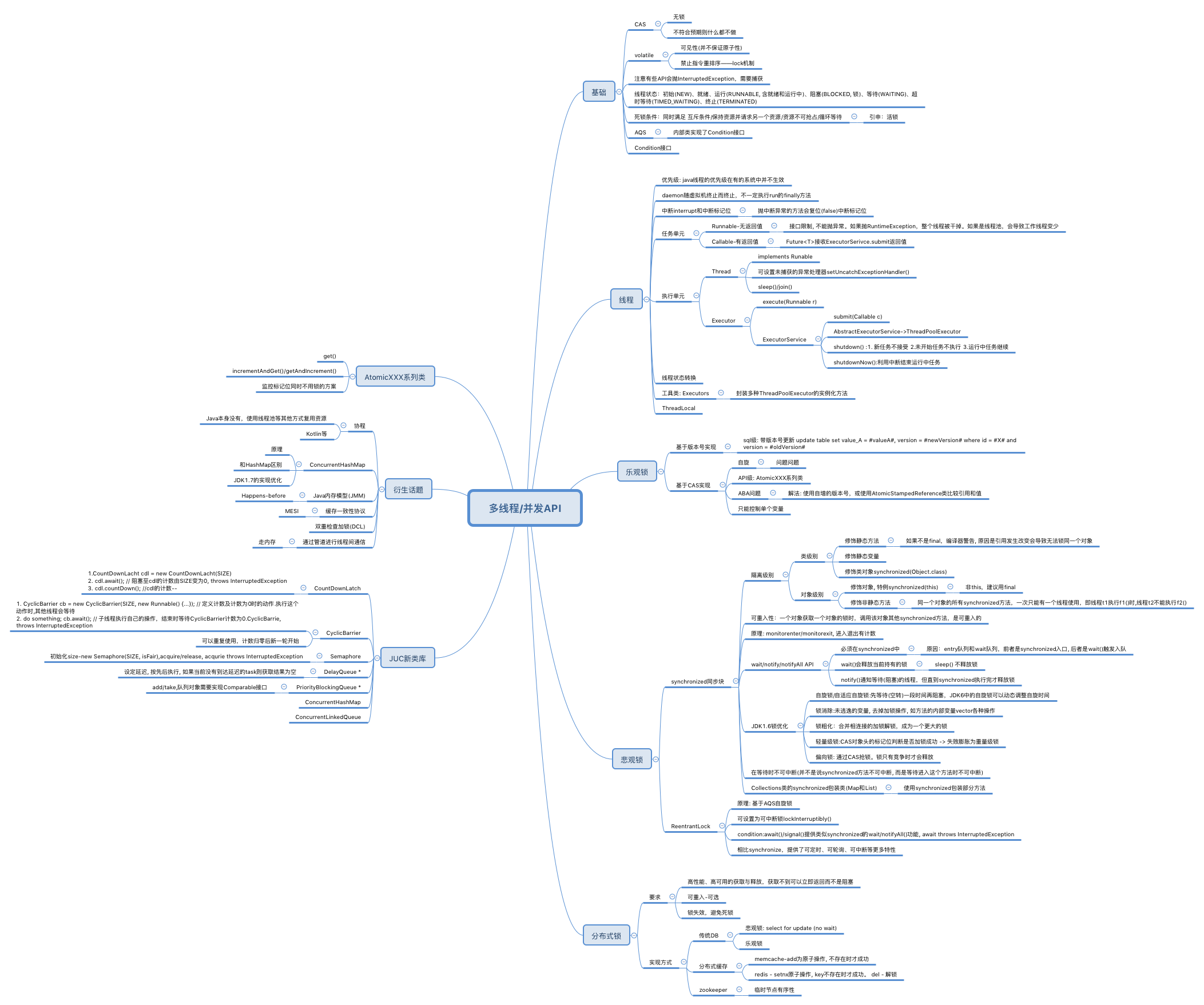
1. 知識點思維導圖
(圖比較大,可以右鍵在新窗口打開)
2. 經典的wait()/notify()/notifyAll()實現生產者/消費者編程範式深入分析 & synchronized
注:本節代碼和部分分析參考了你真的懂wait、notify和notifyAll嗎。
看下面一段典型的wait()/notify()/notifyAll()代碼,對於值得注意的細節,用註釋標出。
import java.util.ArrayList;
import java.util.List;
public class Something {
private Buffer mBuf = new Buffer(); // 共享的池子
public void produce() {
synchronized (this) { // 注1、注2
while (mBuf.isFull()) { // 注3
try {
wait(); // 注4
} catch (InterruptedException e) {
e.printStackTrace();
}
}
mBuf.add();
notifyAll(); // 注5、注6
}
}
public void consume() {
synchronized (this) { // 見注1、注2
while (mBuf.isEmpty()) { // 注3
try {
wait(); // 注4
} catch (InterruptedException e) {
e.printStackTrace();
}
}
mBuf.remove();
notifyAll(); // 注5、注6
}
}
private class Buffer {
private static final int MAX_CAPACITY = 1;
private List innerList = new ArrayList<>(MAX_CAPACITY);
void add() {
if (isFull()) {
throw new IndexOutOfBoundsException();
} else {
innerList.add(new Object());
}
System.out.println(Thread.currentThread().toString() + " add");
}
void remove() {
if (isEmpty()) {
throw new IndexOutOfBoundsException();
} else {
innerList.remove(MAX_CAPACITY - 1);
}
System.out.println(Thread.currentThread().toString() + " remove");
}
boolean isEmpty() {
return innerList.isEmpty();
}
boolean isFull() {
return innerList.size() == MAX_CAPACITY;
}
}
public static void main(String[] args) {
Something sth = new Something();
Runnable runProduce = new Runnable() {
int count = 4;
@Override
public void run() {
while (count-- > 0) {
sth.produce();
}
}
};
Runnable runConsume = new Runnable() {
int count = 4;
@Override
public void run() {
while (count-- > 0) {
sth.consume();
}
}
};
for (int i = 0; i < 2; i++) {
new Thread(runConsume).start();
}
for (int i = 0; i < 2; i++) {
new Thread(runProduce).start();
}
}
}
- 注1:wait()/notify()/notifyAll()必須在synchronized塊中使用
- 注2:使用synchronized(this)的原因是,這段代碼的main(),是通過實例化Something的對象,並使用它的方法來進行生產/消費的,因此是一個指向this的對象鎖。不同的場景,需要注意同步的對象的選擇。
- 注3:必須使用while循環來包裹wait()。設想一種場景:存在多個生產者或多個消費者消費者,以多個生成者為例,在緩衝區滿的情況下,如果生產者通過notify()喚醒的線程仍是生產者,如果不使用while,那麼獲取鎖的線程無法重新進入睡眠,鎖也不能釋放,造成死鎖。
- 注4:wait()會釋放鎖
- 注5:notfiy()、notifyAll()會通知其他在wait的線程來獲取鎖,但是獲取鎖的真正時機是鎖的原先持有者退出synchronized塊的時候。
- 注6:使用notifyAll()而不是notfiy()的原因是,仍考慮注3的場景,假如生產者喚醒的也是生產者,後者發現緩衝區滿重新進入阻塞,此時沒有辦法再喚醒在等待的消費者線程了,也會造成死鎖。
擴展知識點1:synchronized塊的兩個隊列
synchronized入口是將線程放入同步隊列,wait()是將線程放入阻塞隊列。notify()/notifyAll()實際上是把線程從阻塞隊列放入同步隊列。wait/notify/notifyAll方法需不需要被包含在synchronized塊中,為什麼?
擴展知識點2:synchronized重入原理
synchronized是可重入的,原理是它內部包含了一個計數器,進入時+1,退出時-1。 Java多線程:synchronized的可重入性
擴展知識點3:作用範圍
synchronized支持三種用法:修飾靜態方法、修飾實例方法、修飾代碼塊,前兩種分別鎖類對象、鎖對象實例,最後一種根據傳入的值來決定鎖什麼。
synchronized是基於java的對象頭實現的,從字節碼可以看出包括了一對進入&退出的監視器。
深入理解Java併發之synchronized實現原理
擴展知識點4:分佈式環境synchronized的意義
單看應用所運行的的單個宿主機,仍然可能有多線程的處理模式,在這個前提下使用併發相關技術是必須的。
擴展知識點5:哪些方法釋放資源,釋放鎖
所謂資源,指的是系統資源。
wait(): 線程進入阻塞狀態,釋放資源,釋放鎖,Object類final方法(notify/notifyAll一樣,不可改寫)。
sleep(): 線程進入阻塞態,釋放資源,(如果在synchronized中)不釋放鎖,進入阻塞狀態,喚醒隨機線程,Thread類靜態native方法。
yield(): 線程進入就緒態,釋放資源,(如果在synchronized中)不釋放鎖,進入可執行狀態,選擇優先級高的線程執行,Thread類靜態native方法。
如果線程產生的異常沒有被捕獲,會釋放鎖。
sleep和yield的比較
可以進一步地將阻塞劃分為同步阻塞——進入synchronized時沒獲取到鎖、等待阻塞——wait()、其他阻塞——sleep()/join(),可以參考線程的狀態及sleep、wait等方法的區別
再進一步地,Java線程狀態轉移可以用下圖表示(圖源《Java 併發編程藝術》4.1.4 節)
WAITING狀態的線程是不會消耗CPU資源的。
3. 線程數調優
理論篇
本節參考了《Java併發編程實戰》8.2節,也可以結合面試問我,創建多少個線程合適?我該怎麼說幫助理解,其中的計算題比較有價值。
前置知識
I/O密集型任務:I/O任務執行時CPU空閑。
CPU密集型任務:進行計算
有的任務是二者兼備的。為了便於分析,不考慮。
定性分析
場景:單核單線程/單核多線程/多核多線程。單核多線程+CPU密集型不能提升執行效率,多核+CPU密集型任務可以;單核多線程+I/O密集型可以提升執行效率。
因此,I/O耗時越多,線程也傾向於變多來充分利用IO等待時間。
定量分析
對於CPU密集型,線程數量=CPU 核數(邏輯)即可。特別的,為了防止線程在程序運行異常時不空轉,額外多設一個線程線程數量 = CPU 核數(邏輯)+ 1
對於I/O密集型,最佳線程數 = CPU核數 * (1/CPU利用率) = CPU核數 * (1 + I/O耗時/CPU耗時)
為什麼CPU利用率=1/(1+ I/O耗時/CPU耗時)?簡單推導一下:
1/(1+ I/O耗時/CPU耗時) = 1/((CPU耗時+I/O耗時)/ CPU耗時) = CPU耗時/總耗時 = CPU利用率
如何獲取參數——CPU利用率?
因為利用率不是一成不變的,需要通過全面的系統監控工具(如SkyWalking、CAT、zipkin),並長期進行調整觀測。
可以先取2N即2倍核數,此時即假設I/O耗時/CPU耗時=1:1,再進行調優。
阿姆達爾定律
CPU併發處理時性能提升上限。
S=1/(1-a+a/n)
其中,a為并行計算部分所佔比例,n為并行處理結點個數。
簡單粗暴理解【阿姆達爾定律】
Java線程池篇
基本屬性
/**
* 使用給定的初始參數和默認線程工廠創建一個新的ThreadPoolExecutor ,並拒絕執行處理程序。 使用Executors工廠方法之一可能更方便,而不是這種通用構造函數。
參數
* corePoolSize - 即使空閑時仍保留在池中的線程數,除非設置 allowCoreThreadTimeOut
* maximumPoolSize - 池中允許的最大線程數
* keepAliveTime - 當線程數大於核心時,這是多餘的空閑線程在終止之前等待新任務的最大時間。
* unit - keepAliveTime參數的時間單位
* workQueue - 在執行任務之前用於保存任務的隊列。 該隊列將僅保存execute方法提交的Runnable任務。
* threadFactory - 執行程序創建新線程時使用的工廠
*/
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory)
常見線程池
由java.util.concurrent.Executors創建的線程池比較常用,而不是使用ThreadPoolExecutor的構造方法。
| 名稱 | 特性 |
|---|---|
| newFixedThreadPool | 線程池大小為固定值 |
| newSingleThreadExecutor | 線程池大小固定為1 |
| newCachedThreadPool | 線程池大小初始為0,默認最大值為MAX INTEGER |
| newScheduledExecutor | 延遲執行任務或按周期重複執行任務 |
線程工廠的作用
用來創建線程,統一在創建線程時設置一些參數,如是否守護線程。線程一些特性等,如優先級。
可參考004-多線程-JUC線程池-ThreadFactory線程工廠
4. 併發容器相關
併發容器可以說是一個面試時的高頻問題了,網絡上也有很多介紹,這裏就不重複解讀,將相關的知識整理一下,邊看源碼邊讀文章效果會很好。
先提一句,Vector是線程安全的,為啥現在不推薦用呢?看源碼可以知道,它將大部分方法都加了synchronized,犧牲了性能換取線程安全,是不可取的。如果真的有需要線程安全的容器,可以用Collections.synchronizedList()來手動給list加synchronized。
再補充一句,其實Vector和Collections.synchronizedList()使用複合操作或迭代器Iterator時也不是線程安全的,具體解釋會在下一篇博客Java容器中介紹。
ConcurrentHashMap
先重點介紹Map的兩個實現類HashMap和ConcurrentHashMap
- HashMap和ConcurrentHashMap HashMap?ConcurrentHashMap?相信看完這篇沒人能難住你!
- HashMap擴容原理:HashMap的擴容機制—resize()
- 多線程下HashMap擴容resize可能導致鏈表循環
- 這兩個數據結構在JDK1.7到1.8時,當數目達到一個閾值時,都從鏈表改用了紅黑樹
- HashMap的node重寫了equals方法來比較節點。Objects.equals會調用Object的equals,對於Object實現類則是實現類自己的equals。
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
ConcurrentLinkedQueue
ConcurrentLinkedQueue使用CAS無鎖操作,保證入隊出隊的線程安全,但不保證遍歷時的線程安全。遍歷要想線程安全需要單獨加鎖。
由於算法的特性,這個容器的尾結點是有延遲的,tail不一定是尾節點,但p.next == null的節點一定是尾結點。
入隊出隊操作很抽象,需要畫圖幫助理解源碼,對應的源碼分析可參考併發容器-ConcurrentLinkedQueue詳解。
5. AQS解讀
抽象隊列同步器AbstractQueuedSynchronizer(AQS)是JUC中很多併發工具類的基礎,用來抽象各種併發控制行為,如ReentranLock、Semaphore。
之前試着直接讀源碼,效果不太好,還是建議結合質量較高的文章來讀,這裏推薦一篇:Java併發之AQS詳解,並且作者還在不斷更新。
這裏簡單記錄一下總結的點。
結構特點
- volatile int state標記位,標識當前的同步狀態。具體的用法和使用AQS的工具類有關。同時,在做CAS的時候,state的狀態變更是通過計算該變量在對象的偏移量來設置的。
- CLH隊列。CLH鎖(Craig,Landin andHagersten)是一種在SMP(Symmetric Multi-Processor對稱多處理器)架構下基於單鏈表的高性能的自旋鎖,隊列中每個節點代表一個自旋的線程,每個線程只需在代表前一個線程的節點上的布爾值locked自旋即可,如圖
圖源和CLH的詳解見算法:CLH鎖的原理及實現
- exclusiveOwnerThread獨佔模式的擁有者,記錄現在是哪個線程佔用這個AQS。
操作特點
- 對state使用>0和<0的判斷,初看代碼很難看懂,這麼寫的原因是
負值表示結點處於有效等待狀態,而正值表示結點已被取消。 - 大量的CAS:無論是獲取鎖、入隊、獲取鎖失敗后的自旋,全部是依賴CAS實現的。
- 沒有使用synchronized:不難理解,如果使用了同步塊,那麼其實現ReentranLock就沒有和synchronized比較的價值了。不過這一點很少有文章專門提到。
- LockSupport類的unpark()/park()方法的使用:回憶上文提到的線程狀態,如果線程獲取不到AQS控制的資源,需要將線程置於waiting,對應可選的方法是wait()/join()/park()。在AQS這個場景下,顯然一沒有synchronized,二沒有顯式的在同一個代碼塊中用join處理多線程(藉助隊列來處理線程,線程相互之間不感知),那麼只有park()才能達到目的。
處理流程
獲取資源acquire(int)
- 嘗試獲取資源(改寫state),成功則返回
- CAS(失敗則自旋)加入等待隊列隊尾
- 在隊列中自旋,嘗試獲取一次資源(前提:隊頭+ tryAcquire()成功),每次失敗都會更改線程狀態為waiting。自旋時會看看前驅有沒有失效的節點(即不再請求資源的),如果有就插隊到最前面並把前面無效節點清理掉便於gc
- waiting狀態中不響應中斷,獲取資源后才會補一個自我中斷selfInterrupt (調用Thread.currentThread().interrupt())
釋放資源release(int)
- 嘗試釋放,成功則處理後續動作,失敗直接返回false
- 喚醒(unpark)等待隊列的下一個線程。如果當前節點沒找到後繼,則從隊尾tail從后往前找。
共享模式獲取資源acquireShared(int)
除了抽象方法tryAcquireShared()以外,基本和acquire(int)一致。
在等待隊列中獲取資源后,會調用獨有的setHeadAndPropagate()方法,將這個節點設為頭結點的同時,檢查後續節點是否可以獲取資源。
共享模式釋放資源releaseShared()
和release(int)區別在於,喚醒後繼時,不要求當前線程節點狀態為0。舉例:當前線程A原先擁有5個資源,釋放1個,後繼的等待線程B剛好需要1個,那麼此時A、B就可以并行了。
未實現的方法
為了便於使用AQS的類更加個性化,AQS有一下方法直接拋UnsupportedOperationException。
- isHeldExclusively()
- tryAcquire()
- tryRelease()
- tryAcquireShared()
- tryReleaseShared()
不寫成abstract方法的原因是,避免強迫不需要對應方法的類實現這些方法。比如要寫一個獨佔的鎖,那麼就不需要實現共享模式的方法。
AQS小結
讀完源碼總結一下,AQS是一個維護資源和請求資源的線程之間的關係的隊列。對於資源(有序或無序的)獲取和釋放已經提取成了線程的出入隊方法,這個隊列同時維護上線程的自旋狀態和管理線程間的睡眠喚醒。
應用
本節可以看作為《JAVA併發變成實戰》14.6的引申。
ReentrantLock
用內部類Sync實現AQS,Sync實現ReentrantLock的行為。Sync又有FairSync和UnfairSync兩種實現。FairSync,lock對應aquire(1);UnfairSync,lock先CAS試着獲取一次,不行再aquire(1)。
實際上,ReentrantLock的公平/非公平鎖只在首次lock時有區別,入隊后喚醒仍是按順序的。可以參考reentrantLock公平鎖和非公平鎖源碼解析
Sync只實現了獨佔模式。
注意:CyclicBarrier直接用了ReentrantLock,沒有直接用AQS。
Semaphore
和ReentrantLock類似,Semaphore也有一個內部類Sync,但相反的是這個Sync只實現了共享模式的acquire()/release()。
Semaphore在acquire()/release()時會計算資源余量並設置,其中unfair模式下的acquire會無條件自旋CAS,fair模式下只有在AQS里不存在排隊中的後繼的情況下才會CAS,否則自旋。
CountDownLatch
同樣有一個內部類Sync,但是不再區分fair/unfair,並且是共享模式的。
await()調用的是acquireSharedInterruptibly(),自然也存在自旋的可能,只是編程時一般不這麼用。countDown()時釋放一個資源繼續在releaseShared()里自旋直到全部釋放。
FutureTask
新版的FutureTask已經重寫,不再使用AQS,這裏就不再提了。
ReentrantReadWriteLock
可重入讀寫鎖,涉及到鎖升級,這裏沒有研究的很透徹,有興趣可以自行了解。
注意到讀鎖和寫鎖是共用同一個Sync的。
6 JMM到底是個啥?
The Java memory model specifies how the Java virtual machine works with the computer’s memory (RAM)。
—— Java Memory Model
雖然被冠以”模型“,JMM實際上是定義JVM如何與計算機內存協同工作的規範,也可以理解為__指令__與其操作的__數據__的行為。這樣,自然而然地引入了指令重排序、變量更改的可見性的探討。
JMM定義了一個偏序關係,稱之為happens-before。不滿足happens-before的兩個操作可以由JVM進行重排序。
6.1 什麼是偏序關係
假設 R 是集合 A 上的關係,如果R是自反的、反對稱的和傳遞的,則稱 R 是 A 上的一個偏序。偏序關係
那麼,自反的、反對稱的和傳遞的,又是什麼?下面粘貼了百度百科相關詞條:
- 自反關係:設 R是 A上的一個二元關係,若對於 A中的每一個元素 a, (a,a)都屬於 R,則稱 R為自反關係。
- 反對稱關係:集合 A 上的二元關係 R 是反對稱的,當且僅當對於X里的任意元素a, b,若a R-關係於 b 且 b R-關係於 a,則a=b。
- 傳遞關係:令R是A上的二元關係,對於A中任意的 ,若 ,且 ,則 ,則稱R具有傳遞性(或稱R是傳遞關係)。
上面的反對稱關係稍微不好理解,轉換成逆否命題就好理解了:若a!=b,那麼R中不能同存在aRb和bRa。
6.2 偏序關係和JMM
將R作為兩個操作間的關係,集合A是所有操作的集合,那麼就可以理解JMM為什麼實際上是一套偏序關係了。
6.3 happens-before規則
這部分的說明很多文章都是有差異,比如鎖原則,JLS(Java Language Specification,Java語言規範)特指的是監視器鎖,只不過顯式鎖和內置鎖有相同的內存語義而已。這裏直接摘錄原文並配上說明。原文見Chapter 17. Threads and Locks
If we have two actions x and y, we write hb(x, y) to indicate that x happens-before y.
If x and y are actions of the same thread and x comes before y in program order, then hb(x, y).
There is a happens-before edge from the end of a constructor of an object to the start of a finalizer (§12.6) for that object.
If an action x synchronizes-with a following action y, then we also have hb(x, y).
If hb(x, y) and hb(y, z), then hb(x, z).
The wait methods of class Object (§17.2.1) have lock and unlock actions associated with them; their happens-before relationships are defined by these associated actions.
It should be noted that the presence of a happens-before relationship between two actions does not necessarily imply that they have to take place in that order in an implementation. If the reordering produces results consistent with a legal execution, it is not illegal.
For example, the write of a default value to every field of an object constructed by a thread need not happen before the beginning of that thread, as long as no read ever observes that fact.
More specifically, if two actions share a happens-before relationship, they do not necessarily have to appear to have happened in that order to any code with which they do not share a happens-before relationship. Writes in one thread that are in a data race with reads in another thread may, for example, appear to occur out of order to those reads.
The happens-before relation defines when data races take place.
A set of synchronization edges, S, is sufficient if it is the minimal set such that the transitive closure of S with the program order determines all of the happens-before edges in the execution. This set is unique.
It follows from the above definitions that:
An unlock on a monitor happens-before every subsequent lock on that monitor.
A write to a volatile field (§8.3.1.4) happens-before every subsequent read of that field.
A call to start() on a thread happens-before any actions in the started thread.
All actions in a thread happen-before any other thread successfully returns from a join() on that thread.
The default initialization of any object happens-before any other actions (other than default-writes) of a program.
試着翻譯一下各項規則:
先定義hb(x, y)表示操作x和操作y的happens-before關係。
- 同一個線程的操作x, y,代碼中順序為x, y,那麼hb(x, y)
- 對象構造方法要早於終結方法完成
- 如果x synchronizes-with y那麼hb(x,y)
- 傳遞性,hb(x, y) 且hb(y,z)則hb(x,z)
- 同一個監視器鎖解鎖需要hb所有加鎖(注:該規則擴展到顯式鎖)
- volatile的讀hb所有寫(該規則擴展到原子操作)
- 線程start() hb所有它的啟動后的任何動作
- 線程中所有操作hb 對它的join()
- 對象默認構造器hb對它的讀寫
synchronizes-with又是啥?查閱了一下,表示”這個關係表示一個行為在發生時,它首先把要操作的那些對象同主存同步完畢之後才繼續執行“。參考JMM(Java內存模型)中的核心概念。
JLS上對happens-before的解釋翻譯過來還是不太好理解,《Java併發編程實戰》的解釋和Happens-beofre 先行發生原則(JVM 規範)一樣,可以參考下。
最後可以發現,JMM只是一套規則,並沒有提到具體的實現,程序員知道Java有這一重保證即可。
7. 短篇話題整理總結
7.1 ThreadLocal的用法總結
應用場景:在多線程下替代類的靜態變量(static),在多線程環境進行單個 類 的數據隔離。
為什麼推薦使用static修飾ThreadLocal?
這時才能保證”一個線程,一個ThreadLocal”,否則便成了“一個線程,(多個對象實例時)多個ThreadLocal”。
可能會有內存泄漏:ThreadLocalMap的key(Thread對象)是弱引用,但value不是,如果key被回收,value還在。解法是手動remove掉。
(本節參考了《Java併發編程實戰》)
7.2 CountDownLatch和CyclicBarrier區別
https://blog.csdn.net/tolcf/article/details/50925145
CountDownLatch的子任務調用countDown後會繼續執行直至該線程結束。
CyclicBarrier的子任務await時會暫停執行;可重複使用,即await的數目達到設置的值時,喚醒所有await的線程進行下一輪。
7.3 ReentrantLock用了CAS但為什麼不是樂觀鎖?
https://blog.csdn.net/qq_35688140/article/details/101223701
我的看法:因為仍有可能造成阻塞,而樂觀鎖更新失敗則會直接返回(CAS允許自旋)。
換一個角度,悲觀鎖是預先做最壞的設想——一定會有其他任務併發,那麼就先佔好坑再更新;樂觀鎖則是認為不一定有併發,更新時判斷再是否有問題。這樣看來ReentrantLock從使用方式上來說是悲觀鎖。
7.4 雙重檢查加鎖
public classDoubleCheckedLocking{ //1
private static Instance instance; //2
public staticI nstance getInstance(){ //3
if(instance==null){ //4:第一次檢查
synchronized(DoubleCheckedLocking.class){ //5:加鎖
if(instance==null) //6:第二次檢查
instance=newInstance(); //7:問題的根源出在這裏
} //8
}//9
return instance;
}
}
問題
一個線程看到另一個線程初始化該類的部分構造的對象,即以上代碼註釋第4處這裏讀到非null但未完全初始化
原因
註釋第7處,創建對象實例的三步指令1.分配內存空間2.初始化3.引用指向分配的地址,2和3可能重排序
解決
方案1,給instance加violatile
方案2,使用佔位類,在類初始化時初始化對象,如下
public class InstanceFactory {
private static class InstanceHolder{
public static Instance instance= newInstance();
}
public static Instance getInstance() {
return InstanceHolder.instance; //這裏將導致InstanceHolder類被初始化
}
}
7.5 FutureTask
FutureTask是Future的實現類,可以使用Future來接收線程池的submit()方法,也可以直接用FutureTask封裝任務,作為submit()的參數。具體的用法可以參考Java併發編程:Callable、Future和FutureTask 。
新版的FutureTask不再使用AQS。
FutureTask設置了當前工作線程,對於其任務維護了一個內部狀態轉換狀態機,通過CAS做狀態判斷和轉換。
當其他線程來get()時,如果任務未完成則放入等待隊列,自旋直到取到結果(for循環+LockSupport.park()),否則直接取結果。
具體實現原理可以參考《線程池系列一》-FutureTask原理講解與源碼剖析。
7.6 JDK1.6鎖優化之輕量級鎖和偏向鎖
實際上二者是有聯繫的,都是基於mark word實現。這個轉換關係可以用《深入理解Java虛擬機》第十三章的插圖表現
但是這個圖沒有體現輕量級鎖釋放后,仍可恢復為可偏向的。
7.7 問題排查三板斧
- top查看內存佔用率,-H可以看線程(不會完整展示),-p [pid]看指定進程的線程
注意:linux線程和進程id都是在pid這一列展示的。 - pstack跟蹤進程棧,strace查看進程的系統操作。多次執行pstack來觀察進程是不是總是處於某種上下文中。
- jps直接獲取java進程id,jstat看java進程情況。jstate可用不同的參數來查看不同緯度的信息:類加載情況、gc統計、堆內存統計、新生代/老年代內存統計等,具體可以參考【JVM】jstat命令詳解—JVM的統計監測工具
- jstack打印java線程堆棧,和pstack展示方式很像,是java緯度的
- jmap打印java內存情況,-dump可以生成dump文件
- 分析dump文件,如MAT
8. LeetCode多線程習題
原題目和詳解參考Concurrency – 力扣
1114.按序打印
按照指定次序完成一系列動作,可以看做是buffer為1的1對1生產者消費者模型。
1115.交替打印FooBar
交替執行(不完全是生產者-消費者模型)某些動作。
可用的解法:
- synchronized
- Semaphore
- CountDownLatch
- CyclicBarrier
- Lock
1116.打印零與奇偶數:0102…
和1114類似
1188. 設計有限阻塞隊列
注意: 使用synchronize解法時,wait()應置於while中循環判斷.
如果只用if,喚醒后不再次判斷dequeue可能NPE
本題可以加深理解為什麼要用while
1195. 交替打印字符串
根據AC的解法推斷, 每個線程只調用對應方法一次,因此需要在方法內部循環
不推薦只用synchronized,四個線程按順序打印, 如果使用單一的鎖很容易飢餓導致超時
推薦解法:
AtomicInteger無鎖解法
CylicBarrier高效解法
Semaphore加鎖
1279. 紅綠燈路口
題目難懂,暗含條件:車來時紅綠燈不是綠的,則強制變綠通過。紅綠燈本身的時間沒有嚴格控制
延伸閱讀
什麼是分佈式鎖
一文了解分佈式鎖
9. 未展開的話題
併發研究之CPU緩存一致性協議(MESI)
線程池原理(四):ScheduledThreadPoolExecutor
一半是天使一半是魔鬼的Unsafe類詳解 —— unsafe類都有什麼?用偏移量直接訪問、線程操作、內存管理和內存屏障、CAS
10. 其他參考
Java併發高頻面試題
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準