目錄
- Abstract
- Introduction
- 2 Programming Model
- 2.1 Example
- 2.2 Types
- 2.3 More Examples
- 3 Implementation
- 3.1 Execution Overview
- 3.2 Master Data Structures
- 3.3 Fault Tolerance
- Worker Failure (工作節點故障)
- Master Failure(主節點故障)
- Semantics in the Presence of Failures(語義可能存在的故障)
- 3.4 Locality
- 3.5 Task Granularity
- 3.6 Backup Tasks
- 4 Refinements
- 4.1 Partitioning Function
- 4.2 Ordering Guarantees
- 4.3 Combiner Function
- 4.4 Input and Output Types
- 4.5 Side-effects
- 4.6 Skipping Bad Records
- 4.7 Local Execution
- 4.8 Status Information
- 4.9 Counters
- Others
Abstract
MapReduce :
- programming model 編程模型
- an associated implementation for processing and generating large data sets.
用戶只需要指定 Map(Map函數將 key/value 類型的 pair 生成中間結果的 pair) 和 Reduce 函數(Reduce 函數將所有具有相同中間結果的值組合起來)即可。
MapReduce 封裝隱藏了分佈式系統并行計算的細節:
- 輸入數據的分割
- 計劃將程序分配到一組計算機中
- 處理機器故障
- 管理集群內部的通信
程序(in functional style)分佈式的運行在大型分佈式的集群上,而且具有很好的可伸縮性 scalable。
Introduction
過去這些年,Google一直在尋找方法來實現處理大量數據(抓取到的文件,web日誌等)的方法,通常數據量很大而且必須分散在數以千計的電腦上來進行運算。為了處理如何使計算相互關聯,分配數據以及處理故障的問題,往往編寫大量的複雜代碼掩蓋了他們,最初的簡單計算的初衷卻被忽略掉。
為了解決這種複雜性,抽象出了一個簡單的計算模型放到一個庫中,這個庫隱藏了可能出現的問題:
這個抽象受到了 Lisp 以及很多函數式編程語言中存在的原語 map和 reduce 的啟發。
大多數并行計算都包含兩個步驟:
- map:將每個邏輯記錄變成
key/value 的中間形式方便計算
- reduce:將所有具有相同
key 的值組合到一起來進行合適的處理
我們使用一個函數式的編程模型(functional programming model)可以讓處理大型的并行計算和使用重新執行作為容錯的主要機制變得很簡單。
這項工作的主要貢獻是:提供了一個簡單但是很強大的接口(interface)讓自動化的并行計算和大規模計算的分發成為可能,結合該接口的實現,可以在商用機的大型集群上實現高性能。
Section2 :描述了基本的編程模型給出幾個例子
Section3 :描述MapReduce 接口針對集群運算環境的實現
Section4 :一些針對該模型的細微的改良
Section5 :針對實現設計出一系列性能衡量方法
Section6 :MapReduce 在 Google 中的使用,以及使用 MapReduce 來重寫生產環境的索引系統
Section7 :相關以及未來的工作
2 Programming Model
input: a set of key/value pairs
output: a set of key/value pairs
MapReduce 的用戶將只會使用兩個函數 Map 和 Reduce。
Map:用戶編寫,將輸入的 pair 變成 k/v 的中間 pairs,然後 MapReduce 會把具有相同 key 的 pair 送給 Reduce 函數
Reduce: 用戶編寫,接受中間結果 key 和 key 的一系列值。將這些值組合起來成為更少的 k/v;通常每個 Reduce 函數只輸出一個 或者 0 個值。中間結果太多無法全部放到內存中,可以通過迭代的方法來處理大量的 value
2.1 Example
設想一個需要統計文件中每個單詞數量的一個問題,我們很可能編寫這樣的代碼:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1")
reduce(String key, String values):
// key: a word
// values: a list of counts
int result = 0
for each v in values
result += ParseInt(v)
Emit(AsString(result))
map:給每個單詞添加一個屬性(出現的次數,這裏就是1)
reduce:給每個特定的單詞加起來計算總數並且提交
此外,用戶編寫代碼以使用輸入和輸出文件的名稱以及可選的調整參數來填充mapreduce規範對象。然後,用戶調用MapReduce函數,並將其傳遞給指定對象。用戶代碼與MapReduce庫(在C ++中實現)鏈接在一起。
2.2 Types
儘管前面偽代碼使用 string 來寫的輸入輸出,但是從概念上說,是由用戶來指定 map 和 reduce 的類型
map (k1, v1) -> list(k2, v2)
map (k2, list(v2)) -> list(v2)
輸入值和中間值來自不同的域,中間值和輸出值來自相同的域
C ++實現在用戶定義的函數之間來回傳遞字符串,並將其留給用戶代碼以在字符串和適當的類型之間進行轉換
2.3 More Examples
這有一些可以使用 MapReduce 簡化的計算:
Distributed Grep: 分佈式的匹配,map 函數提交一個符合匹配的 line, reduce 的作用只是複製中間結果到輸出
Count of URL Access Frequency: 網頁訪問計數,map 處理網頁請求並且輸出中間結果為 <URL, 1>, reduce 功能是將所有的相同的 URL 計算到一起提交為 <URL, total count>
Reverse Web-Link Graph: 翻轉網絡鏈接圖, map 輸出 <target, source> pairs ,將 target 命名為 source。reduce函數連接與給定目標URL關聯的所有源URL的列表,並提交該對 <target, list(source)>
Term-Vector per Host: 術語向量是出現在一篇文章中最重要的術語集合列表<word, frequency> pairs。map 函數給每個輸入文件輸出一個 <hostname, term vector> pairs,reduce 函數傳遞給特定主機的術語向量,然後去掉不常出現的向量最後提交一個 <hostname, term vector> pair
Invert Index:map函數解析每個文檔,併發出一系列<單詞,文檔ID>對。 reduce函數接受給定單詞的所有對,對相應的文檔ID進行排序,併發出一個“單詞,列表(文檔ID)”對。setofall輸出對形成一個簡單的倒排索引。易於擴展此計算以跟蹤單詞位置。
Distributed Sort: 分佈式排序,map函數功能從每個記錄中提取鍵,併發出一個<key, record>對。 reduce函數將所有對保持不變。這種計算取決於第4.1節中描述的分區功能和第4.2節中描述的排序屬性。
3 Implementation
MapReduce 可以有很多不同的實現,正確實現是根據你自己所在的環境來進行實現,例如某個實現可能很適合一個共享內存的小機器,某個實現可能是在NUMA多處理器的環境下,也可能是在一個大的網絡連接的集群的機器中。
NUMA Non-uniform memory access
非統一內存訪問架構是一種為多處理器的電腦設計的內存架構,內存訪問時間取決於內存相對於處理器的位置。在NUMA下,處理器訪問它自己的本地內存的速度比非本地內存快一些。 非統一內存訪問架構的特點是:被共享的內存物理上是分佈式的,所有這些內存的集合就是全局地址空間
這節描述的是 Google 雲計算環境下廣泛使用的,下面是 Google 的配置:
- 機器,都是典型的Linux系統,運行在基於x86的雙處理器上,每台機器 2-4GB 內存
- 網絡,使用商品網絡硬件,在機器級別通常為100Mb/s或1Gb/s,但平均平均對分帶寬要小得多
- 集群中有上百或者上千個機器,所以機器故障出現很正常
- 存儲,使用廉價的 IDE 硬盤直接保存每個機器自己的數據,開發出的分佈式文件系統來管理這些磁盤上的文件。文件系統使用複製來在不可靠的硬件上提供可用性和可靠性。
- 用戶通過一個任務調度系統提交任務。每個工作包含一系列的任務,使用任務調度器來分配到集群中可用的機器上
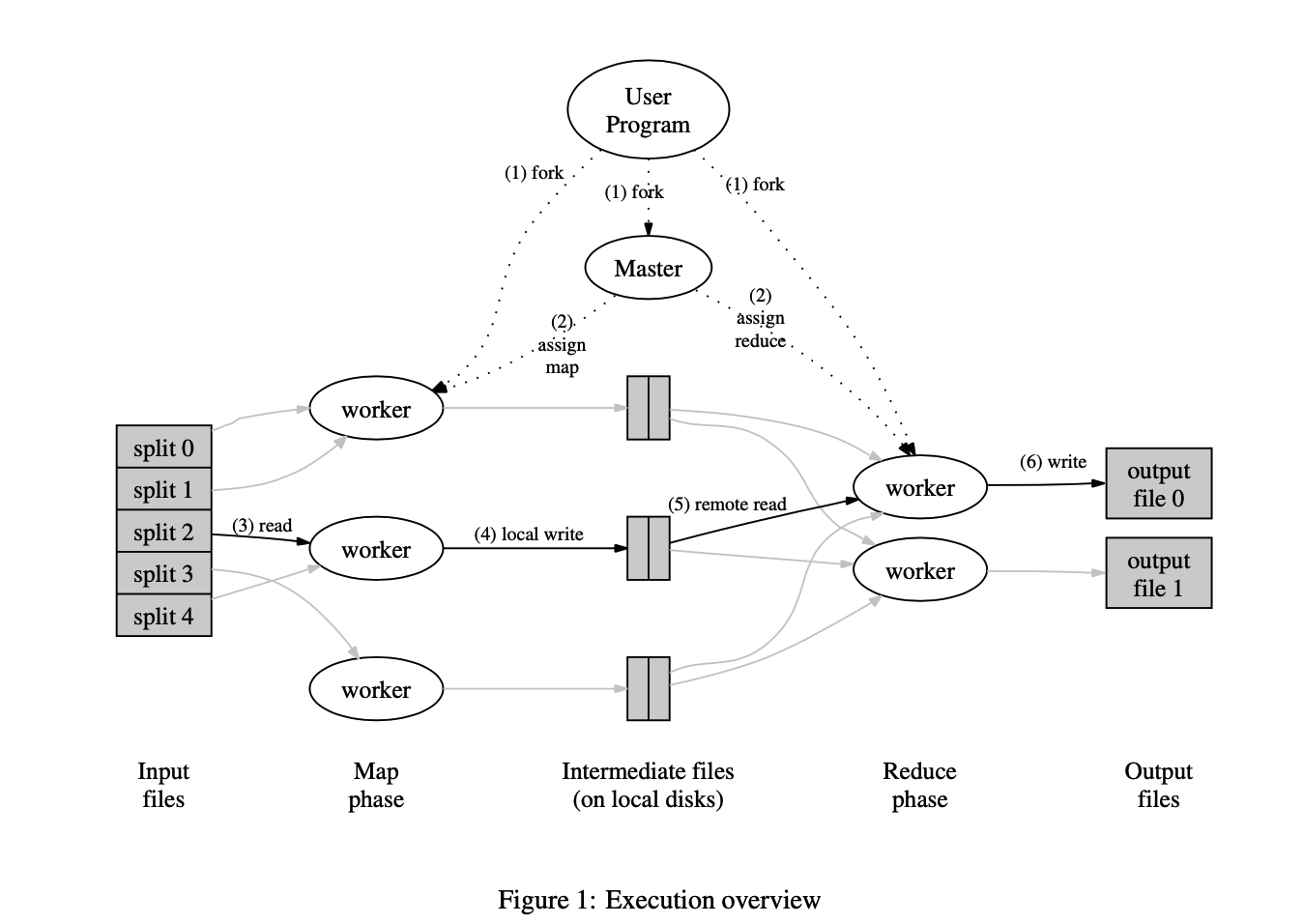
3.1 Execution Overview
Map 調用分佈在多個機器上,自動將輸入數據分配成 M 組,輸入的分割可以并行的發生在不同的機器上。 Reduce 調用也是分佈式的,通過將中間值的key使用一個分割函數(例如:hash(key) mod R)來將任務分配到不同的機器上。分區數量 R 的取值和分區數量也是通過用戶來指定的。
下面這個圖說明了 MapReduce 執行的完整流程:
- 用戶程序中的 MapReduce 庫首先將輸入文件分成 M 份(每份 16MB – 64 MB),然後開始在集群中複製很多拷貝
- 程序中有一份拷貝是特殊的(master)。剩下的 worker 來被分配工作,有 M 個map任務和 R 個 reduce 任務來分配給不同的 worker。master 來挑選空閑的 worker 分配給他們每個一個 map task 或者 reduce task
- 一個被分配到 map 工作的 worker 將會從對應的分割的內容中讀取。它會解析
k/v pair 到輸入數據並且傳給到用戶定義的 map 函數。Map 函數產生的中間 key/value 數據將會被保存在內存的緩存中
- 緩存中的 pair 會被周期性的寫入到本地磁盤上,通並且過分割函數將該文件分成的 R 個區域。這些緩衝對的位置在本地磁盤上被傳遞迴主服務器,該主服務器負責將這些位置轉發給reduce worker。
- 當一個 reduce worker 被 master 告知這些存儲的區域,reduce worker 將使用遠程過程調用來從 map workers 的本地磁盤以及緩存中讀取 pair 對。當一個 reduce worker 讀取了所有的中間數據,它將會跟配相同的 key 來進行排序。排序是必需的因為通常會有很多不同的 key 映射到同一個 reduce 任務。如果中間數據太大來放到內存中排序,外排序就會被使用
- reduce worker 迭代排過序的中間數據,對於每個獨特的中間值 key,它會傳遞這個 key 和對應中間值到用戶定義的 reduce 函數中來處理。Reduce函數的輸出將附加到此reduce分區的最終輸出文件中
- 當所有的 map task 和 reduce task 都被完成之後,master 喚醒用戶程序。這個時候,MapReduce 的調用返回到用戶的代碼邏輯中
在成功的完成之後,mapreduce執行的輸出將會在 R 個輸出文件中(每個reduce task 都會被用戶指定文件的名稱)。通常來說,用戶不會將 R 個輸出文件合併成一個,而是將這個文件作為另一個 MapReduce 的輸入。或者把他們當成另外的分佈式程序的輸入
3.2 Master Data Structures
master 保存一些數據結構。對於每個 map 和 reduce 任務,它會保存狀態(idle,in-progress,completed),以及識別每個 worker machine(非空閑任務)。
master 是處於 map 任務發送到 reduce 任務中間的導管,master 會保存中間文件區域的位置。因此,對於每個完成的 map 任務, master 保存 R 個由map任務產生的中間文件的大小和位置。當 map 任務完成之後,會更新這些文件的位置和大小。這些信息將逐漸被推送到已經在工作的 reduce 任務。
3.3 Fault Tolerance
由於 MapReduce 是用來在大量機器上處理大量數據的一個庫,所以這個庫必需能夠有很好的容錯能力。
Worker Failure (工作節點故障)
master 節點周期性的 ping 每個 worker 節點。如果在一個特定的時間內沒有收到回復,那麼 master 節點就會將這個 worker 標記為失敗。完成 map 任務的 worker 節點將會被重置為 idle 空閑狀態,然後就可以被其他 worker 節點安排。相似的,如果一個節點上的 map 或者 reduce 任務在執行過程中失敗了,那麼這個任務將會被重置然後分配然後重新分配。
如果一個 map 任務的節點在完成任務之後出現故障,那麼就需要重新執行這個任務,因為這個節點變得不可訪問。但是如果是 reduce 任務完成之後節點出現故障,不需要重新執行,這是因為 reduce 任務的輸出被保存到一個全局文件系統中。
當一個 map 任務首先在節點 A 上執行之後在節點 B 上執行時,所有正在執行的 reduce 節點將會被告知這次重新執行過程。所有還沒有從 worker A 讀取數據的 reduce 任務將會 worker B 讀取。
MapReduce 可以處理大規模的 worker 節點故障。例如在一次 MapReduce 任務中,一個由80台計算機組成的集群由於網絡問題無法訪問,MapReduce 的 master 節點只是簡單的讓那些不能正常執行任務的工作節點再次執行任務,然後繼續向前執行任務直到完成 MapReduce 操作。
Master Failure(主節點故障)
讓 master 節點周期性的上述master節點的數據結構的檢查點。如果 master task 失敗了,可以從上一個檢查點的拷貝恢復。但是如果只有一個主節點,那麼出現故障的可能性非常小,因此如果主節點出現故障,我們的當前的實現就中止了此次 MapReduce 任務。客戶端可以檢查到這種情況,然後可以選擇是否重試 MapReduce 操作。
Semantics in the Presence of Failures(語義可能存在的故障)
當用戶指定的 map 和 reduce 操作對於他們的輸入輸出都確定好了之後,分佈式的實現將會產生一個類似於線性執行過程任務執行的結果。
我們依賴於 map 和 reduce 任務的 原子性 commit 作為這個特性的保證。每個執行過程中的任務都會將把他的輸出保存到一個私有的臨時文件中。一個 reduce 任務產生一個這樣的文件,但是一個 map 任務將會產生 R 個這樣的文件。當一個 map 任務完成之後, worker 節點發送包含這 R 個文件名的消息到 master 節點。如果這個節點已經接收到完成的消息,那麼將會忽略這個消息,否則將會把這些文件名保存到 master 節點的數據結構中。
當一個 reduce 任務完成的時候,reduce worker 將會原子性的將它的臨時文件重命名成一個輸出文件。如果有以個 reduce 任務在多個機器上同時完成,那麼這個重命名的操作將會對於一個輸出文件多次執行。我們依賴於基礎文件系統提供的原子重命名操作,以確保最終文件系統狀態僅包含一次執行reduce任務所產生的數據。
map 和 reduce 操作絕大部分都是確定性的,事實上我們的語義將會和線性順序執行的程序的結果一致,這樣很容易分析程序的行為。當 map/reduce 操作是不確定的時候,我們提供弱化但是可信的語義。例如在一個不確定的語義中,一個特定 reduce 任務的輸出和這個任務順序執行的結果一致。然而,用於不同reduce任務R2的輸出可以對應於由不確定性程序的不同順序執行所產生的用於R2的輸出。(這裏保留疑問,沒有太懂什麼意思,指的是有可能是線性結果一致的意思嗎?)
考慮有一個 map 任務 M,和兩個 reduce 任務 R1,R2,e(Ri)是 Ri提交的結果,弱一點的語義指的是,e(R1) 可能讀取的 M 的一個執行的結果而 e(R2) 可能讀取的是 R 執行輸出的另外一個結果。
3.4 Locality
網絡帶寬是在雲計算環境中比較稀缺的資源(盡量少用)。通過將輸入文件(由GFS保管)保存到本地磁盤上來減少網絡帶寬的使用。GFS 將每個文件分成 64 MB的塊,然後將每塊保存幾個副本(通常為3份)在不同的機器上。MapReduce 盡量將這些位置信息保存下來然後盡量將含有某個文件主機的任務分配給它,這樣就可以減少網絡的傳遞使用。如果失敗,那麼將會嘗試從靠近輸入數據的一個副本主機去啟動這個任務。當在一個集群上執行大型的 MapReduce 操作的時候,輸入數據一般都是本地讀取,減少網絡帶寬的使用。
3.5 Task Granularity
我們將一個 map 任務分成 M 塊,然後 reduce 會處理最後輸出成 R 塊。
理想情況下,M 和 R 應該遠遠大於集群中的 worker 節點數量。讓每個節點執行不同的任務將會有利於動態的負載均衡,同時會加速當一個 worker 節點故障之後的恢復,map 任務完成之後可以分配到所有的其他節點上。
R 和 M 在實現過程中會有邊界,因為 schedule 決策需要 O(M + R)的時間,保存這個信息到內存中需要 O(M*R)的複雜度(常數內存很小)。
R 通常是由用戶指定的,這是由於每個 reduce 任務的輸出將會輸出到單獨的文件中。在實際中,通常 M 被選擇到每個單獨的任務輸入數據將會是 16MB ~ 64MB,讓 R 要比我們使用的機器的數目的小几倍。
例如,M =20,000,R = 5,000,worker machines = 2000
3.6 Backup Tasks
讓整個 MapReduce 任務時間延長的原因主要有 “拖延者”:某一個機器在 map/reduce 任務上花費了太多的時間。導致這個 “拖延者” 的原因可能有很多,比如一塊讀寫速度超級慢的硬盤 1MB/s(其他的是 30MB/s)比如集群在這個機器上也分配了其他任務,這些任務競爭使用 CPU、硬盤網絡等等。我們最近遇到的一個問題是機器初始化代碼中的一個錯誤,該錯誤導致禁用了處理器緩存:受影響機器的計算速度降低了一百倍。
4 Refinements
儘管上面說的夠用了,但是我們還是找到一些可以優化的點。
4.1 Partitioning Function
用戶將會指定輸出文件的數量 R。輸入數據將會根據中間值來把這些數據分區。一個默認的分區函數就是 hash函數(hash(key) mod R) 。通常情況下這樣很好,但是在某些情況下不是很好。例如,輸出數據是 URL key,我們希望具有相同主機 hostname 的 URL 在一起,這樣,MapReduce 提供了用戶自己制定 分區函數的方式,例如可以寫為(hash(Hostname(urlkey))),這樣具有相同的 hostname 的URL將會在一個相同的輸出文件中。
4.2 Ordering Guarantees
我們保證了在某個給定的分區中,中間值的 k/v pair 將會按照增序排列,這樣在某些需要有序的場景下是很有用的。
4.3 Combiner Function
在某些情況下,最終的輸出文件reduce是需要根據中間值來合併的。例如在2.1的 word count 中,需要統計每個單詞的數目,我們輸出的是 <word, 1> 這樣的形式。這些pair都需要通過網絡來進行發送到 reduce 工作節點,我們提供了一個 combiner 函數,讓用戶可以在發送數據之前執行的函數,也就是說在本地先合併,然後再發送到網絡中去。
在每個執行 map task 的機器都會執行 conbine 函數。
combine 和 reduce 的唯一區別:
- combine 輸出是到中間值文件中
- reduce 輸出到一個最終的輸出文件中
4.4 Input and Output Types
MapReduce 庫提供了幾種輸入的類型。
例如,在 “text” 模式下輸入將每一個行當作 k/v pair,這行的偏移量當作 key,這行的內容當作 value。
用戶可以通過實現 reader 接口在實現自己的輸入類型,儘管大多數用戶都只使用預定義的類型。
reader 不一定要從文件中讀取數據,也可以從數據庫中讀取數據,或者從內存中的某個的某個數據結構中獲取數據。
同樣的,輸出也可以自定義。
4.5 Side-effects
在某些情況下,用戶需要產生一些額外的輸出文件在reduce 的輸出結果中。我們依靠這個應用程序自己的編寫者來使此類副作用成為原子和冪等的。通常應用程序將會寫入一個臨時文件中,然後當它完成的時候將會原子性的重命名這個文件。
我們不提供原子性的兩節點提交由一個任務產生的多個輸出文件。因此,產生多個輸出的結果的任務應該是確定性的。
4.6 Skipping Bad Records
在處理大量數據的時候,由於用戶的 map/reduce 函數的錯誤在處理某些數據的時候產生bug,這個時候可以選擇跳過這些 bug。有的時候我們可以查找到bug所在的地方,但是有的時候我們找不到bug,因為可能是第三方的庫導致的錯誤,我們提供了一種可選的執行模式來跳過這些可能出現錯誤的記錄。
每個 worker 進程都會有一個監聽段錯誤和總線錯誤的處理器。在執行用戶的 map/reduce 函數之前,mapreduce 將會在一個全局變量中保存順序編號。如果用戶代碼產生了一個 signal,那麼就會發送一個 UDP包到 MapReduce 的 master 節點上。當 master 節點發現在某個幾點上出現了很多次故障的時候,之後就會跳過這個記錄。
4.7 Local Execution
在 Map/Reduce 中debug需要一些 trick,因為在分佈式系統中執行可能是在幾千台機器中,工作分配也是動態的。MapReduce 提供了一個另外的本地MapReduce 的本地實現(順序執行),這樣就可以在本地來進行 debug了。
4.8 Status Information
master 節點通過 HTTP 服務器提供一個显示當前狀態的網頁。這個界面显示了多少任務完成了,多少任務還在執行,中間數據有多少字節等,還包含了錯誤的標準輸出文件的鏈接等,用戶可以通過這個界面預估還有多久可以完成任務。當執行很慢的時候,可以通過這個界面來查找原因。
另外,top-level 的狀態信息還會显示哪些 worker 節點有故障,哪些任務失敗了。
4.9 Counters
提供一個全局的計數器來統計某些數據,例如統計大寫單詞的出現次數。
Counter* uppercase;
uppercase = GetCounter("uppercase");
map(String name, String contents):
for each word w in contents:
if (IsCapitalized(w)):
uppercase->Increment();
EmitIntermediate(w, "1");
計數器的值會從每個節點周期性的發送到master節點,主節點統計計數器的值並且在 狀態頁面显示。
有些值MapReduce 會自己去統計。
計數器功能對於完整性檢查MapReduce操作的行為很有用。例如,在某些MapReduce操作中,用戶代碼可能想要確保所生成的輸出對的數量完全等於所處理的輸入對的數量,或者所處理的德語文檔的比例在該比例之內。
Others
shuffle:將所有具有相同 key 的value 發送個單個的 reduce 進程,在網絡上傳輸數據,是MapReduce代價最大的部分
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※幫你省時又省力,新北清潔一流服務好口碑
※別再煩惱如何寫文案,掌握八大原則!