Python中的異常處理
異常分類
程序中難免出現錯誤,總共可分為兩種。
1.邏輯錯誤
2.語法錯誤
對於剛接觸編程的人來說,這兩個錯誤都會經常去犯,但是隨着經驗慢慢的積累,語法錯誤的情況會越來越少反而邏輯錯誤的情況會越來越多(因為工程量巨大)。不論多麼老道的程序員都不可避免出現這兩種錯誤。
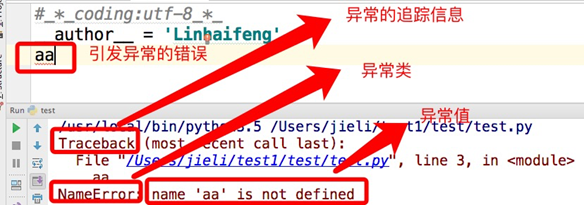
異常的三大信息
異常其實就是程序運行時發生錯誤的信號,我們寫代碼的過程中不可避免也最害怕的就是出現異常,然而當程序拋出異常時實際上會分為三部分,即三大信息。
常用的異常類
在Python中一切皆對象,異常本身也是由一個類生成的,NameError其實本身就是一個異常類,其他諸如此類的異常類還有很多。
| Python中常見的異常類 |
| AttributeError |
試圖訪問一個對象沒有的屬性,比如foo.x,但是foo並沒有屬性x |
| IOError |
輸入/輸出異常;基本上是無法打開文件 |
| ImportError |
無法引入模塊或包;基本上是路徑問題或名稱錯誤 |
| IndentationError |
語法錯誤(的子類) ;代碼沒有正確對齊 |
| IndexError |
下標索引超出序列邊界,比如當x只有三個元素,卻試圖訪問x[5] |
| KeyError |
試圖訪問字典里不存在的鍵 |
| KeyboardInterrupt |
Ctrl+C被按下 |
| NameError |
試圖使用一個還未被賦予對象的變量 |
| SyntaxError |
Python代碼非法,代碼不能編譯(其實就是語法錯誤,寫錯了) |
| TypeError |
傳入對象類型與要求的不符合 |
| UnboundLocalError |
試圖訪問一個還未被設置的局部變量,基本上是由於另有一個同名的 全局變量,導致你以為正在訪問它 |
| ValueError |
傳入一個調用者不期望的值,即使值的類型是正確的 |
異常處理
我們可以來用某些方法進行異常捕捉,當出現異常時我們希望代碼以另一種邏輯運行,使得我們的程序更加健壯,這個就叫做異常處理。異常處理是非常重要的,本身也並不複雜,千萬不可馬虎大意。
但是切記不可濫用異常處理,這會使得你的代碼可讀性變差。
if else處理異常
if和else本身就具有處理異常的功能,他們更多的是在我們能預測到可能出現的範圍內進行規避異常,對於我們不能預測的異常來說就顯得不是那麼的好用。如下:
# ==== if else 處理異常 ====
while 1:
select = input("請輸入数字0進行關機:").strip()
if select.isdigit(): # 我們可以防止用戶輸入非数字的字符
if select == "0":
print("正在關機...")
break
print("輸入有誤,請重新輸入")
# ==== 執行結果 ====
"""
請輸入数字0進行關機:關機
輸入有誤,請重新輸入
請輸入数字0進行關機:關機啊
輸入有誤,請重新輸入
請輸入数字0進行關機:0
正在關機...
"""
這種異常處理機制雖然非常簡單,但是並不靈活,我們可以使用更加簡單的方式來處理他們。
try except處理異常
try:代表要檢測可能出現異常的代碼塊
except:當異常出現后的處理情況
執行流程:
try中檢測的代碼塊 —> 如果有異常 —> 執行except代碼塊 —> 執行正常邏輯代碼 —> 程序結束
try中檢測的代碼塊 —> 如果沒有異常 —> 執行完畢try中的代碼塊 —> 執行正常邏輯代碼 —> 程序結束
# ==== try except 執行流程 有異常的情況 ====
li = [1,2,3]
try:
print("開始執行我try了...")
print(li[10]) # 出錯點...
print("繼續執行我try...")
except IndexError as e:
print("有異常執行我except...")
print("正常邏輯代碼...")
# ==== 執行結果 ====
"""
開始執行我try了...
有異常執行我except...
正常邏輯代碼...
"""
# ==== try except 執行流程 無異常的情況 ====
li = [1,2,3]
try:
print("開始執行我try了...")
print(li[2])
print("繼續執行我try...")
except IndexError as e:
print("有異常執行我except...")
print("正常邏輯代碼...")
# ==== 執行結果 ====
"""
開始執行我try了...
3
繼續執行我try...
正常邏輯代碼...
"""
# ==== try except 處理異常 ====
while 1:
try: # try檢測可能出錯的語句,一旦出錯立馬跳轉到except語句塊執行代碼。
select = int(input("請輸入数字0進行關機:").strip())
if select == 0:
print("正在關機...")
break
print("輸入有誤,請重新輸入...")
except ValueError as e: # 當執行完except的代碼塊后,程序運行結束,其中e代表的是異常信息。
print("錯誤信息是:",e)
print("輸入有誤,請重新輸入")
# ==== 執行結果 ====
"""
請輸入数字0進行關機:1
輸入有誤,請重新輸入...
請輸入数字0進行關機:tt
錯誤信息是: invalid literal for int() with base 10: 'tt'
輸入有誤,請重新輸入
請輸入数字0進行關機:0
正在關機...
"""
多段except捕捉多異常
我們可以使用try和多段except的語法來檢測某一代碼塊,可以更加方便的應對更多類型的錯誤,Ps不常用:
# ==== 多段 except 捕捉多異常 ====
while 1:
li = [1,2,3,4]
dic = {"name":"Yunya","age":18}
li_index = input("請輸入索引:")
dic_key = input("請輸入鍵的名稱:")
if li_index.isdigit():
li_index = int(li_index)
try:
print(li[li_index])
print(dic[dic_key])
except IndexError as e1: # 注意,先拋出的錯誤會直接跳到其處理的except代碼塊,而try下面的語句將不會被執行。
print("索引出錯啦!")
except KeyError as e2:
print("鍵出錯啦!")
# ==== 執行結果 ====
"""
請輸入索引:10
請輸入鍵的名稱:gender
索引出錯啦!
請輸入索引:2
請輸入鍵的名稱:gender
3
鍵出錯啦!
"""
元組捕捉多異常
使用多段except捕捉多異常會顯得特別麻煩,這個時候我們可以使用(異常類1,異常類2)來捕捉多異常,但是需要注意的是,對比多段except捕捉多異常來說,這種方式的處理邏輯會顯得較為複雜(因為只有一段處理邏輯),如下:
# ==== 元組捕捉多異常 ====
while 1:
li = [1,2,3,4]
dic = {"name":"Yunya","age":18}
li_index = input("請輸入索引:")
dic_key = input("請輸入鍵的名稱:")
if li_index.isdigit():
li_index = int(li_index)
try:
print(li[li_index])
print(dic[dic_key])
except (IndexError,KeyError) as e: # 使用()的方式可以同時捕捉很多異常。
print("出錯啦!")
# ==== 執行結果 ====
"""
請輸入索引:10
請輸入鍵的名稱:gender
出錯啦!
請輸入索引:2
請輸入鍵的名稱:gender
3
出錯啦!
"""
可以看到,不管是那種錯誤都只有一種應對策略,如果我們想要多種應對策略就只能寫if判斷來判斷異常類型再做處理。所以就會顯得很麻煩,如下:
# ==== 元組捕捉多異常 ====
while 1:
li = [1,2,3,4]
dic = {"name":"Yunya","age":18}
li_index = input("請輸入索引:")
dic_key = input("請輸入鍵的名稱:")
if li_index.isdigit():
li_index = int(li_index)
try:
print(li[li_index])
print(dic[dic_key])
except (IndexError,KeyError) as e:
# 判斷異常類型再做出相應的對應策略
if isinstance(e,IndexError):
print("索引出錯啦!")
elif isinstance(e,KeyError):
print("鍵出錯啦!")
# ==== 執行結果 ====
"""
請輸入索引:10
請輸入鍵的名稱:gender
索引出錯啦!
請輸入索引:2
請輸入鍵的名稱:gender
3
鍵出錯啦!
"""
萬能異常Exception
我們可以捕捉Exception類引發的異常,它是所有異常類的基類。(Exception類的父類則是BaseException類,而BaseException的父類則是object類)
# ==== 萬能異常Exception ====
while 1:
li = [1,2,3,4]
dic = {"name":"Yunya","age":18}
li_index = input("請輸入索引:")
dic_key = input("請輸入鍵的名稱:")
if li_index.isdigit():
li_index = int(li_index)
try:
print(li[li_index])
print(dic[dic_key])
except Exception as e: #使用 Exception來捕捉所有異常。
# 判斷異常類型再做出相應的對應策略
if isinstance(e,IndexError):
print("索引出錯啦!")
elif isinstance(e,KeyError):
print("鍵出錯啦!")
# ==== 執行結果 ====
"""
請輸入索引:10
請輸入鍵的名稱:gender
索引出錯啦!
請輸入索引:2
請輸入鍵的名稱:gender
3
鍵出錯啦!
"""
try except else聯用
這種玩法比較少,else代表沒有異常發生的情況下執行的代碼,執行順序如下:
try中檢測的代碼塊 —> 如果有異常 —> 終止try中的代碼塊繼續執行 —> 執行except代碼塊 —> 執行正常邏輯代碼 —> 程序結束
try中檢測的代碼塊 —> 如果沒有異常 —> 執行完畢try中的代碼塊 —> 執行else代碼塊 —> 執行正常邏輯代碼 —> 程序結束
# ==== try except else聯用 有異常的情況====
li = [1,2,3]
try:
print("開始執行我try了...")
print(li[10]) # 出錯點...
print("繼續執行我try...")
except IndexError as e:
print("有異常執行我except...")
else:
print("沒有異常執行我else...")
print("正常邏輯代碼...")
# ==== 執行結果 ====
"""
開始執行我try了...
有異常執行我except...
正常邏輯代碼...
"""
# ==== try except else聯用 無異常的情況====
li = [1,2,3]
try:
print("開始執行我try了...")
print(li[2])
print("繼續執行我try...")
except IndexError as e:
print("有異常執行我except...")
else:
print("沒有異常執行我else...")
print("正常邏輯代碼...")
# ==== 執行結果 ====
"""
開始執行我try了...
3
繼續執行我try...
沒有異常執行我else...
正常邏輯代碼...
"""
try except finally聯用
finally代表不論拋異常與否都會執行,因此常被用作關閉系統資源的操作,關於try,except,else,finally他們的優先級如下:
有異常的情況下:
try代碼塊
終止try代碼塊繼續執行
except代碼塊
finally代碼塊
正常邏輯代碼
無異常的情況下:
try代碼塊
else代碼塊
finally代碼塊
正常邏輯代碼
# ==== try except else finally 執行流程 有異常的情況 ====
li = [1,2,3]
try:
print("開始執行我try了...")
print(li[10]) # 出錯點...
print("繼續執行我try...")
except IndexError as e:
print("有異常執行我except...")
else:
print("沒有異常執行我else...")
finally:
print("不管有沒有異常都執行我finally...")
print("正常邏輯代碼...")
# ==== 執行結果 ====
"""
開始執行我try了...
有異常執行我except...
不管有沒有異常都執行我finally...
正常邏輯代碼...
"""
# ==== try except else finally 執行流程 無異常的情況 ====
li = [1,2,3]
try:
print("開始執行我try了...")
print(li[2])
print("繼續執行我try...")
except IndexError as e:
print("有異常執行我except...")
else:
print("沒有異常執行我else...")
finally:
print("不管有沒有異常都執行我finally...")
print("正常邏輯代碼...")
# ==== 執行結果 ====
"""
開始執行我try了...
3
繼續執行我try...
沒有異常執行我else...
不管有沒有異常都執行我finally...
正常邏輯代碼...
"""
自定義異常
raise主動拋出異常
在某些時候我們可能需要主動的去阻止程序的運行,主動的拋出一個異常。可以使用raise來進行操作。這個是一種非常常用的手段。
# ==== raise使用方法 ====
print("----1----")
print("----2----")
print("----3----")
raise Exception("我也不知道是什麼類型的異常...")
print("----4----")
print("----5----")
print("----6----")
# ==== 執行結果 ====
"""
----1----
----2----
----3----
Traceback (most recent call last):
File "C:/Users/Administrator/PycharmProjects/learn/元類編程.py", line 6, in <module>
raise Exception("我也不知道是什麼類型的異常...")
Exception: 我也不知道是什麼類型的異常...
Process finished with exit code 1
"""
自定義異常類
前面已經說過一切皆對象,異常也來自一個對象。因此我們也可以自己來定製一個對象。注意,自定義異常類必須繼承BaseException類。
# ==== 自定義異常類 ====
class MyError(BaseException):
pass
raise MyError("我的異常")
# ==== 執行結果 ====
"""
Traceback (most recent call last):
File "C:/Users/Administrator/PycharmProjects/learn/元類編程.py", line 6, in <module>
raise MyError("我的異常")
__main__.MyError: 我的異常
"""
擴展:斷言assert
斷言是一個十分裝逼的使用,假設多個函數進行計算,我們已經有了預期的結果只是在做一個算法的設計。如果函數的最後的結果不是我們本來預期的結果那麼寧願讓他停止運行也不要讓錯誤繼續擴大,在這種情況下就可以使用斷言操作,使用斷言會拋出一個AssertionError類的異常。
# ==== 斷言assert ====
def calculate():
"""假設在做非常複雜的運算"""
return 3+2*5
res = calculate()
assert res == 25 # AssertionError
print("算法測試通過!你真的太厲害了")
# ==== 執行結果 ====
"""
Traceback (most recent call last):
File "C:/Users/Administrator/PycharmProjects/learn/元類編程.py", line 8, in <module>
assert res == 25
AssertionError
"""
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※新北清潔公司,居家、辦公、裝潢細清專業服務
※教你寫出一流的銷售文案?