背景
之前做過一次uboot的升級,當時留下了一些記錄,本文摘錄其中比較有意思的兩個問題。
啟動失敗問題
問題簡述
uboot代碼中用到了一個庫,考慮到庫本身跟uboot版本沒什麼關係,就直接把舊的庫文件拷貝過來使用。結果編譯鏈接是沒問題,啟動卻會卡住。
消失的打印
為了明確卡住的位置,就去修改了庫的源碼,添加一些打印(此時還是在舊版本uboot下編譯的),結果發現卡住的位置或隨着添加打印的變化而變化,且有些打印語句,添加后未打印出來。
我決定先從這些神秘消失的打印入手。
分析下uboot中的printf實現,最底層就是寫寄存器,是一個同步的函數,也沒什麼可疑的地方。
為了確認打印不出來的時候,到底有沒有調用到printf,我決定給printf增加一個計數器,在gd結構體中,增加一個printf_count字段,初始化為0,每次打印時執行printf_count++並打印出值。
設計這個試驗,本意是確認未打印出來時是否確實也調用到了printf,但卻有了別的發現,實驗結果中printf_count值會異常變化,不是按打印順序遞增,而是會突變成很大的異常值。
printf_count是gd結構體的成員,那就是gd的問題了。進一步將uboot全局結構體gd的地址打印出來。確認了原因是gd結構體的指針變化了。
這也可以解釋部分打印消失的現象,原因是我們在gd中有另一個字段,用於控制打印等級。當gd被改動了,printf就可能解析出錯,誤以為打印等級為0而提前返回。
gd的實現
那麼好端端的,gd為什麼會被改了呢?這就要先看看gd到底是怎麼實現的了。
uboot中維護了一個全局的結構體gd。在代碼中加入
DECLARE_GLOBAL_DATA_PTR;
即可使用gd指針訪問這個全局結構體,許多地方都會藉助gd來保存傳遞信息。
進一步看看這個宏的定義
舊版本uboot:
#define DECLARE_GLOBAL_DATA_PTR register volatile gd_t *gd asm ("r8")
新版本uboot:
#define DECLARE_GLOBAL_DATA_PTR register volatile gd_t *gd asm ("r9")
居然不一樣,一個是將gd的值放到r8寄存器,一個是放在r9寄存器。
那麼就可以猜測到,庫是在舊版本uboot中編譯出來的,可能使用了r9,那麼放到新版本uboot中去,就會破壞r9寄存器中保存的gd值,導致一系列依賴gd的代碼不能正常工作。
驗證改動
為了求證,將庫反彙編出來,發現確實避開了r8寄存器,但使用了r9寄存器。
說明uboot在指定gd寄存器的同時,還有某種方法讓其他代碼不使用這個寄存器。
那是不是把舊uboot中的這個r8改成r9,重新編譯庫就可以了呢?試一下,還是不行。
那麼禁止其他代碼使用r8寄存器肯定就是通過別的方式實現的了。簡單粗暴地在舊版本uboot下搜索r8,去掉.c .h等類型后,很容易發現了
./arch/arm/cpu/armv7/config.mk:24:PLATFORM_RELFLAGS += -fno-common -ffixed-r8 -msoft-floa
將-ffixed-r8修改為-ffixed-r9,重新編譯出庫,這回就可以正常工作了,打印正常,啟動正常。反彙編出來也可以看到,新編譯出來的庫用了r8沒有用r9。
當然更好的改法,是直接在新版本的uboot中編譯,這是最可靠的。
追本溯源
話說回來,為什麼兩個版本的uboot,會使用不同的寄存器呢?難道有什麼坑?
這就得去翻一下git記錄了。
commit fe1378a961e508b31b1f29a2bb08ba1dac063155
Author: Jeroen Hofstee <jeroen@myspectrum.nl>
Date: Sat Sep 21 14:04:41 2013 +0200
ARM: use r9 for gd
To be more EABI compliant and as a preparation for building
with clang, use the platform-specific r9 register for gd
instead of r8.
note: The FIQ is not updated since it is not used in u-boot,
and under discussion for the time being.
The following checkpatch warning is ignored:
WARNING: Use of volatile is usually wrong: see
Documentation/volatile-considered-harmful.txt
Signed-off-by: Jeroen Hofstee <jeroen@myspectrum.nl>
cc: Albert ARIBAUD <albert.u.boot@aribaud.net>
從git記錄中,也可以確認完整地將r8切換到r9,都需要做哪些修改
diff --git a/arch/arm/config.mk b/arch/arm/config.mk
index 16c2e3d1e0..d0cf43ff41 100644
--- a/arch/arm/config.mk
+++ b/arch/arm/config.mk
@@ -17,7 +17,7 @@ endif
LDFLAGS_FINAL += --gc-sections
PLATFORM_RELFLAGS += -ffunction-sections -fdata-sections \
- -fno-common -ffixed-r8 -msoft-float
+ -fno-common -ffixed-r9 -msoft-float
# Support generic board on ARM
__HAVE_ARCH_GENERIC_BOARD := y
diff --git a/arch/arm/cpu/armv7/lowlevel_init.S b/arch/arm/cpu/armv7/lowlevel_init.S
index 82b2b86520..69e3053a42 100644
--- a/arch/arm/cpu/armv7/lowlevel_init.S
+++ b/arch/arm/cpu/armv7/lowlevel_init.S
@@ -22,11 +22,11 @@ ENTRY(lowlevel_init)
ldr sp, =CONFIG_SYS_INIT_SP_ADDR
bic sp, sp, #7 /* 8-byte alignment for ABI compliance */
#ifdef CONFIG_SPL_BUILD
- ldr r8, =gdata
+ ldr r9, =gdata
#else
sub sp, #GD_SIZE
bic sp, sp, #7
- mov r8, sp
+ mov r9, sp
#endif
/*
* Save the old lr(passed in ip) and the current lr to stack
diff --git a/arch/arm/include/asm/global_data.h b/arch/arm/include/asm/global_data.h
index 79a9597419..e126436093 100644
--- a/arch/arm/include/asm/global_data.h
+++ b/arch/arm/include/asm/global_data.h
@@ -47,6 +47,6 @@ struct arch_global_data {
#include <asm-generic/global_data.h>
-#define DECLARE_GLOBAL_DATA_PTR register volatile gd_t *gd asm ("r8")
+#define DECLARE_GLOBAL_DATA_PTR register volatile gd_t *gd asm ("r9")
#endif /* __ASM_GBL_DATA_H */
diff --git a/arch/arm/lib/crt0.S b/arch/arm/lib/crt0.S
index 960d12e732..ac54b9359a 100644
--- a/arch/arm/lib/crt0.S
+++ b/arch/arm/lib/crt0.S
@@ -69,7 +69,7 @@ ENTRY(_main)
bic sp, sp, #7 /* 8-byte alignment for ABI compliance */
sub sp, #GD_SIZE /* allocate one GD above SP */
bic sp, sp, #7 /* 8-byte alignment for ABI compliance */
- mov r8, sp /* GD is above SP */
+ mov r9, sp /* GD is above SP */
mov r0, #0
bl board_init_f
@@ -81,15 +81,15 @@ ENTRY(_main)
* 'here' but relocated.
*/
- ldr sp, [r8, #GD_START_ADDR_SP] /* sp = gd->start_addr_sp */
+ ldr sp, [r9, #GD_START_ADDR_SP] /* sp = gd->start_addr_sp */
bic sp, sp, #7 /* 8-byte alignment for ABI compliance */
- ldr r8, [r8, #GD_BD] /* r8 = gd->bd */
- sub r8, r8, #GD_SIZE /* new GD is below bd */
+ ldr r9, [r9, #GD_BD] /* r9 = gd->bd */
+ sub r9, r9, #GD_SIZE /* new GD is below bd */
adr lr, here
- ldr r0, [r8, #GD_RELOC_OFF] /* r0 = gd->reloc_off */
+ ldr r0, [r9, #GD_RELOC_OFF] /* r0 = gd->reloc_off */
add lr, lr, r0
- ldr r0, [r8, #GD_RELOCADDR] /* r0 = gd->relocaddr */
+ ldr r0, [r9, #GD_RELOCADDR] /* r0 = gd->relocaddr */
b relocate_code
here:
@@ -111,8 +111,8 @@ clbss_l:cmp r0, r1 /* while not at end of BSS */
bl red_led_on
/* call board_init_r(gd_t *id, ulong dest_addr) */
- mov r0, r8 /* gd_t */
- ldr r1, [r8, #GD_RELOCADDR] /* dest_addr */
+ mov r0, r9 /* gd_t */
+ ldr r1, [r9, #GD_RELOCADDR] /* dest_addr */
/* call board_init_r */
ldr pc, =board_init_r /* this is auto-relocated! */
啟動慢問題
問題簡述
填了幾個坑之後,新的uboot可以啟動到內核了,但發現啟動速度非常慢,內核啟動速度慢了接近10倍!明明是同一個內核,為什麼差異這麼大。
排查寄存器
初步排查了下設備樹配置,以及uboot跳轉內核前的一些關鍵寄存器,確實在兩個版本的uboot中有所不同,但具體去看這些不同,發現都不會影響速度,將一些驅動對齊之後寄存器差異基本就消失了。
差異的分界
那再細看,kernel的速度有差異,uboot呢?在哪個時間點之後,速度開始產生差異?
嘗試在兩個版本的uboot中插入一些操作,對比時間戳,發現兩個uboot在某個節點之後的速度確實有區別。
進一步排查,原來是在打開cache操作之後,舊uboot的速度就會比新uboot快。嘗試將舊uboot的cache關掉,則二者基本一致。嘗試將舊uboot操作cache的代碼,移植到新uboot,未發生改變。
此時可確認新uboot的開cache有問題。但覺得這個跟kernel啟動慢沒關係。因為uboot進入kernel之前都會關cache,由kernel自己去重新打開。
也就是不管是用哪份uboot,也不管uboot中是否開了cache,對kernel階段都應該沒有影響才對。
於是記錄下來uboot的這個問題,待後續修復。先繼續找kernel啟動慢的原因。(注:現在看來當時的做法是有問題的,這裏的異常這麼明顯,應該設法追蹤下去找出原因才對)
鎖定uboot
uboot的嫌疑非常大,但還不能完全確認,因為uboot之前還有一級spl。是否會是spl的問題呢?
嘗試改用新spl+舊uboot,啟動速度正常。而新spl+新uboot的啟動速度則很慢,其他因素都不變,說明問題確實出在uboot階段。
多做or少做
當時到這一步就卡住了,直接比較兩份uboot的代碼不太現實,差異太大了。
後來我就給自己提了個問題,到底新uboot是多做了某件事情,還是少做了某件事情?
換個說法,目前已知
spl --> 舊uboot --> kernel(速度快)
spl --> 新uboot --> kernel(速度快)
但到底是以下的情況A還是情況B呢?
A: spl(速度慢) --> 舊uboot(做了某個會提升速度的操作) --> kernel(速度快)
spl(速度慢) --> 新uboot(少做了某個會提升速度的操作) --> kernel(速度慢)
B: spl(速度快) --> 舊uboot(沒做特殊操作) --> kernel(速度快)
spl(速度快) --> 新uboot(多做了某個會限制速度的操作) --> kernel(速度慢)
為了驗證,我決定讓spl直接啟動內核,看看內核到底是快是慢。
支持過程碰到了一些小問題
1.spl沒有能力加載這麼大的kernel
解決:此時不需要kernel能完全啟動,只需要能加載啟動一段,足以體現出啟動速度是否正常即可,於是裁剪出一個非常小kernel來輔助實驗。
2.kernel需要dtb
解決:內核有一個CONFIG_BUILD_ARM_APPENDED_DTB_IMAGE選項。選上重新編譯。編譯后再用dd將kernel和dtb拼接到一起,作為新的kernel。這樣,spl就只需要加載一個文件並跳轉過去即可。
試驗結果,spl啟動的kernel和使用新uboot啟動的kernel速度一致,均比舊uboot啟動的kernel慢。
說明,舊uboot中做了某個關鍵操作,而新uboot沒做。
找出關鍵操作
那接下來的任務就是,找出舊uboot中的這個關鍵操作了。
怎麼找呢?有了上一步的成果,我們可以使用以下方法來排查
-
spl加載kernel和舊uboot
-
spl跳轉到舊uboot,此時kernel其實已經在dram中準備好了,隨時可以啟動
-
在舊uboot的啟動流程各個階段,嘗試直接跳轉到kernel,觀察啟動速度
-
如果在舊uboot的A點跳轉kernel啟動慢,B點跳轉啟動快,則說明關鍵操作位於AB點之間。
方法有了,很快就鎖定到start.S,進一步在start.S中揪出了這段代碼
#if defined(CONFIG_ARM_A7)
@set SMP bit
mrc p15, 0, r0, c1, c0, 1
orr r0, r0, #(1<<6)
mcr p15, 0, r0, c1, c0, 1
#endif
新uboot的start.S中沒有這段代碼,嘗試在新uboot的start.S中添加此操作,速度立馬恢復正常了。
再全局搜索下,原來這個新版本uboot中,套路是在board_init中進行此項設置的,而這個平台從舊版本移植過來,就沒有設置 SMP bit, 補上即可。
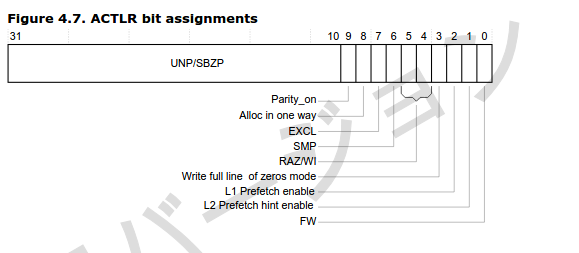
SMP bit是什麼
SMP 是指對稱多處理器,看起來這個 bit 會影響多核的 cache一致性,此處沒有再深入研究。
但可以知道,對於單處理器的情況,也需要設置這個bit才能正常使用cache。
貼下arm的圖和描述:
[6] SMP
Signals if the Cortex-A9 processor is taking part in coherency or not.
In uniprocessor configurations, if this bit is set, then Inner Cacheable Shared is treated as Cacheable. The reset value is zero.
搜下kernel的代碼,發現也是有地方調用了的。不過這個芯片是單核的,根本就沒配置CONFIG_SMP。
#ifdef CONFIG_SMP
ALT_SMP(mrc p15, 0, r0, c1, c0, 1)
ALT_UP(mov r0, #(1 << 6)) @ fake it for UP
tst r0, #(1 << 6) @ SMP/nAMP mode enabled?
orreq r0, r0, #(1 << 6) @ Enable SMP/nAMP mode
orreq r0, r0, r10 @ Enable CPU-specific SMP bits
mcreq p15, 0, r0, c1, c0, 1
#endif
總結
整理出來一方面是記錄這兩個bug,另一方面也是想記錄下當時的一些操作。
畢竟同樣的bug可能以後都不會碰到了,但解bug的方法和思路卻是可以積累復用的。
blog: https://www.cnblogs.com/zqb-all/p/13172546.html
公眾號:https://sourl.cn/shT3kz
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化