編者注:Netty是Java領域有名的開源網絡庫,特點是高性能和高擴展性,因此很多流行的框架都是基於它來構建的,比如我們熟知的Dubbo、Rocketmq、Hadoop等。本文就netty線程模型展開分析討論下 : )
IO模型
- BIO:同步阻塞IO模型;
- NIO:基於IO多路復用技術的“非阻塞同步”IO模型。簡單來說,內核將可讀可寫事件通知應用,由應用主動發起讀寫操作;
- AIO:非阻塞異步IO模型。簡單來說,內核將讀完成事件通知應用,讀操作由內核完成,應用只需操作數據即可;應用做異步寫操作時立即返回,內核會進行寫操作排隊並執行寫操作。
NIO和AIO不同之處在於應用是否進行真正的讀寫操作。
reactor和proactor模型
- reactor:基於NIO技術,可讀可寫時通知應用;
- proactor:基於AIO技術,讀完成時通知應用,寫操作應用通知內核。
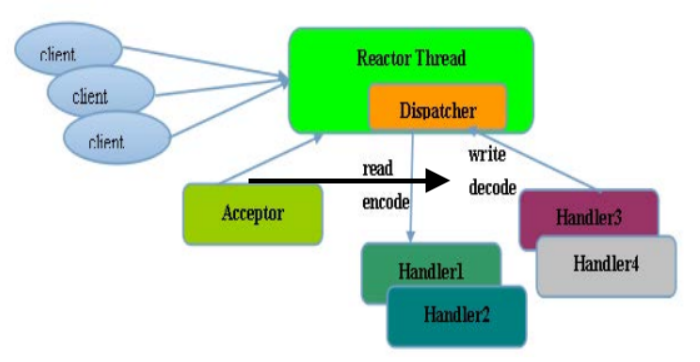
netty線程模型
netty的線程模型是基於Reactor模型的。
netty單線程模型
Reactor 單線程模型,是指所有的 I/O 操作都在同一個 NIO 線程上面完成的,此時NIO線程職責包括:接收新建連接請求、讀寫操作等。
在一些小容量應用場景下,可以使用單線程模型(注意,Redis的請求處理也是單線程模型,為什麼Redis的性能會如此之高呢?因為Redis的讀寫操作基本都是內存操作,並且Redis協議比較簡潔,序列化/反序列化耗費性能更低)。但是對於高負載、大併發的應用場景卻不合適,主要原因如下:
- 一個NIO線程同時處理成百上千的連接,性能上無法支撐,即便NIO線程的CPU負荷達到100%,也無法滿足海量消息的編碼、解碼、讀取和發送。
- 當NIO線程負載過重之後,處理速度將變慢,這會導致大量客戶端連接超時,超時之後往往會進行重發,這更加重了NIO線程的負載,最終會導致大量消息積壓和處理超時,成為系統的性能瓶頸。
- 可靠性問題:一旦NIO線程意外跑飛,或者進入死循環,會導致整個系統通信模塊不可用,不能接收和處理外部消息,造成節點故障。
Reactor多線程模型
Rector 多線程模型與單線程模型最大的區別就是有一組 NIO 線程來處理連接讀寫操作,一個NIO線程處理Accept。一個NIO線程可以處理多個連接事件,一個連接的事件只能屬於一個NIO線程。
在絕大多數場景下,Reactor 多線程模型可以滿足性能需求。但是,在個別特殊場景中,一個 NIO 線程負責監聽和處理所有的客戶端連接可能會存在性能問題。例如併發百萬客戶端連接,或者服務端需要對客戶端握手進行安全認證,但是認證本身非常損耗性能。在這類場景下,單獨一個 Acceptor 線程可能會存在性能不足的問題,為了解決性能問題,產生了第三種 Reactor 線程模型——主從Reactor 多線程模型。
Reactor主從多線程模型
主從 Reactor 線程模型的特點是:服務端用於接收客戶端連接的不再是一個單獨的 NIO 線程,而是一個獨立的 NIO 線程池。Acceptor 接收到客戶端 TCP連接請求並處理完成后(可能包含接入認證等),將新創建的 SocketChannel注 冊 到 I/O 線 程 池(sub reactor 線 程 池)的某個I/O線程上, 由它負責SocketChannel 的讀寫和編解碼工作。Acceptor 線程池僅僅用於客戶端的登錄、握手和安全認證,一旦鏈路建立成功,就將鏈路註冊到後端 subReactor 線程池的 I/O 線程上,由 I/O 線程負責後續的 I/O 操作。
netty線程模型思考
netty 的線程模型並不是一成不變的,它實際取決於用戶的啟動參數配置。通過設置不同的啟動參數,Netty 可以同時支持 Reactor 單線程模型、多線程模型。
為了盡可能地提升性能,Netty 在很多地方進行了無鎖化的設計,例如在 I/O 線程內部進行串行操作,避免多線程競爭導致的性能下降問題。表面上看,串行化設計似乎 CPU 利用率不高,併發程度不夠。但是,通過調整 NIO 線程池的線程參數,可以同時啟動多個串行化的線程并行運行,這種局部無鎖化的串行線程設計相比一個隊列多個工作線程的模型性能更優。(小夥伴們後續多線程併發流程可參考該類實現方案)
Netty 的 NioEventLoop 讀取到消息之後,直接調用 ChannelPipeline 的fireChannelRead (Object msg)。 只要用戶不主動切換線程, 一直都是由NioEventLoop 調用用戶的 ChannelHandler,期間不進行線程切換。這種串行化處理方式避免了多線程操作導致的鎖的競爭,從性能角度看是最優的。
Netty擁有兩個NIO線程池,分別是bossGroup和workerGroup,前者處理新建連接請求,然後將新建立的連接輪詢交給workerGroup中的其中一個NioEventLoop來處理,後續該連接上的讀寫操作都是由同一個NioEventLoop來處理。注意,雖然bossGroup也能指定多個NioEventLoop(一個NioEventLoop對應一個線程),但是默認情況下只會有一個線程,因為一般情況下應用程序只會使用一個對外監聽端口。
這裏試想一下,難道不能使用多線程來監聽同一個對外端口么,即多線程epoll_wait到同一個epoll實例上?
epoll相關的主要兩個方法是epoll_wait和epoll_ctl,多線程同時操作同一個epoll實例,那麼首先需要確認epoll相關方法是否線程安全:簡單來說,epoll是通過鎖來保證線程安全的, epoll中粒度最小的自旋鎖ep->lock(spinlock)用來保護就緒的隊列, 互斥鎖ep->mtx用來保護epoll的重要數據結構紅黑樹。
看到這裏,可能有的小夥伴想到了Nginx多進程針對監聽端口的處理策略,Nginx是通過accept_mutex機制來保證的。accept_mutex是nginx的(新建連接)負載均衡鎖,讓多個worker進程輪流處理與client的新連接。當某個worker進程的連接數達到worker_connections配置(單個worker進程的最大處理連接數)的最大連接數的7/8時,會大大減小獲取該worker獲取accept鎖的概率,以此實現各worker進程間的連接數的負載均衡。accept鎖默認打開,關閉它時nginx處理新建連接耗時會更短,但是worker進程之間可能連接不均衡,並且存在“驚群”問題。只有在使能accept_mutex並且當前系統不支持原子鎖時,才會用文件實現accept鎖。注意,accept_mutex加鎖失敗時不會阻塞當前線程,類似tryLock。
現代linux中,多個socker同時監聽同一個端口也是可行的,nginx 1.9.1也支持這一行為。linux 3.9以上內核支持SO_REUSEPORT選項,允許多個socker bind/listen在同一端口上。這樣,多個進程可以各自申請socker監聽同一端口,當連接事件來臨時,內核做負載均衡,喚醒監聽的其中一個進程來處理,reuseport機制有效的解決了epoll驚群問題。
再回到剛才提出的問題,java中多線程來監聽同一個對外端口,epoll方法是線程安全的,這樣就可以使用使用多線程監聽epoll_wait了么,當然是不建議這樣乾的,除了epoll的驚群問題之外,還有一個就是,一般開發中我們使用epoll設置的是LT模式(水平觸發方式,與之相對的是ET默認,前者只要連接事件未被處理就會在epoll_wait時始終觸發,後者只會在真正有事件來時在epoll_wait觸發一次),這樣的話,多線程epoll_wait時就會導致第一個線程epoll_wait之後還未處理完畢已發生的事件時,第二個線程也會epoll_wait返回,顯然這不是我們想要的,關於java nio的測試demo如下:
public class NioDemo {
private static AtomicBoolean flag = new AtomicBoolean(true);
public static void main(String[] args) throws Exception {
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.socket().bind(new InetSocketAddress(8080));
// non-block io
serverChannel.configureBlocking(false);
Selector selector = Selector.open();
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
// 多線程執行
Runnable task = () -> {
try {
while (true) {
if (selector.select(0) == 0) {
System.out.println("selector.select loop... " + Thread.currentThread().getName());
Thread.sleep(1);
continue;
}
if (flag.compareAndSet(true, false)) {
System.out.println(Thread.currentThread().getName() + " over");
return;
}
Iterator<SelectionKey> iter = selector.selectedKeys().iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
// accept event
if (key.isAcceptable()) {
handlerAccept(selector, key);
}
// socket event
if (key.isReadable()) {
handlerRead(key);
}
/**
* Selector不會自己從已選擇鍵集中移除SelectionKey實例,必須在處理完通道時手動移除。
* 下次該通道變成就緒時,Selector會再次將其放入已選擇鍵集中。
*/
iter.remove();
}
}
} catch (Exception e) {
e.printStackTrace();
}
};
List<Thread> threadList = new ArrayList<>();
for (int i = 0; i < 2; i++) {
Thread thread = new Thread(task);
threadList.add(thread);
thread.start();
}
for (Thread thread : threadList) {
thread.join();
}
System.out.println("main end");
}
static void handlerAccept(Selector selector, SelectionKey key) throws Exception {
System.out.println("coming a new client... " + Thread.currentThread().getName());
Thread.sleep(10000);
SocketChannel channel = ((ServerSocketChannel) key.channel()).accept();
channel.configureBlocking(false);
channel.register(selector, SelectionKey.OP_READ, ByteBuffer.allocate(1024));
}
static void handlerRead(SelectionKey key) throws Exception {
SocketChannel channel = (SocketChannel) key.channel();
ByteBuffer buffer = (ByteBuffer) key.attachment();
buffer.clear();
int num = channel.read(buffer);
if (num <= 0) {
// error or fin
System.out.println("close " + channel.getRemoteAddress());
channel.close();
} else {
buffer.flip();
String recv = Charset.forName("UTF-8").newDecoder().decode(buffer).toString();
System.out.println("recv: " + recv);
buffer = ByteBuffer.wrap(("server: " + recv).getBytes());
channel.write(buffer);
}
}
}netty線程模型實踐
(1) 時間可控的簡單業務直接在 I/O 線程上處理
時間可控的簡單業務直接在 I/O 線程上處理,如果業務非常簡單,執行時間非常短,不需要與外部網絡交互、訪問數據庫和磁盤,不需要等待其它資源,則建議直接在業務 ChannelHandler 中執行,不需要再啟業務的線程或者線程池。避免線程上下文切換,也不存在線程併發問題。
(2) 複雜和時間不可控業務建議投遞到後端業務線程池統一處理
複雜度較高或者時間不可控業務建議投遞到後端業務線程池統一處理,對於此類業務,不建議直接在業務 ChannelHandler 中啟動線程或者線程池處理,建議將不同的業務統一封裝成 Task,統一投遞到後端的業務線程池中進行處理。過多的業務ChannelHandler 會帶來開發效率和可維護性問題,不要把 Netty 當作業務容器,對於大多數複雜的業務產品,仍然需要集成或者開發自己的業務容器,做好和Netty 的架構分層。
(3) 業務線程避免直接操作 ChannelHandler
業務線程避免直接操作 ChannelHandler,對於 ChannelHandler,IO 線程和業務線程都可能會操作,因為業務通常是多線程模型,這樣就會存在多線程操作ChannelHandler。為了盡量避免多線程併發問題,建議按照 Netty 自身的做法,通過將操作封裝成獨立的 Task 由 NioEventLoop 統一執行,而不是業務線程直接操作,相關代碼如下所示:
如果你確認併發訪問的數據或者併發操作是安全的,則無需多此一舉,這個需要根據具體的業務場景進行判斷,靈活處理。
推薦閱讀
歡迎小夥伴關注【TopCoder】閱讀更多精彩好文。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!