目錄
- TCP網絡編程
- UDP網絡編程
- Http網絡編程
- 理解函數是一等公民
- HttpServer源碼閱讀
- HttpClient源碼閱讀
- DemoCode
- 整理思路
- 重要的struct
- 流程
- transport.dialConn
- 發送請求
TCP網絡編程
存在的問題:
- 拆包:
- 對發送端來說應用程序寫入的數據遠大於socket緩衝區大小,不能一次性將這些數據發送到server端就會出現拆包的情況。
- 通過網絡傳輸的數據包最大是1500字節,當
TCP報文的長度 - TCP頭部的長度 > MSS(最大報文長度時)將會發生拆包,MSS一般長(1460~1480)字節。
- 粘包:
- 對發送端來說:應用程序發送的數據很小,遠小於socket的緩衝區的大小,導致一個數據包裏面有很多不通請求的數據。
- 對接收端來說:接收數據的方法不能及時的讀取socket緩衝區中的數據,導致緩衝區中積壓了不同請求的數據。
解決方法:
- 使用帶消息頭的協議,在消息頭中記錄數據的長度。
- 使用定長的協議,每次讀取定長的內容,不夠的使用空格補齊。
- 使用消息邊界,比如使用 \n 分隔 不同的消息。
- 使用諸如 xml json protobuf這種複雜的協議。
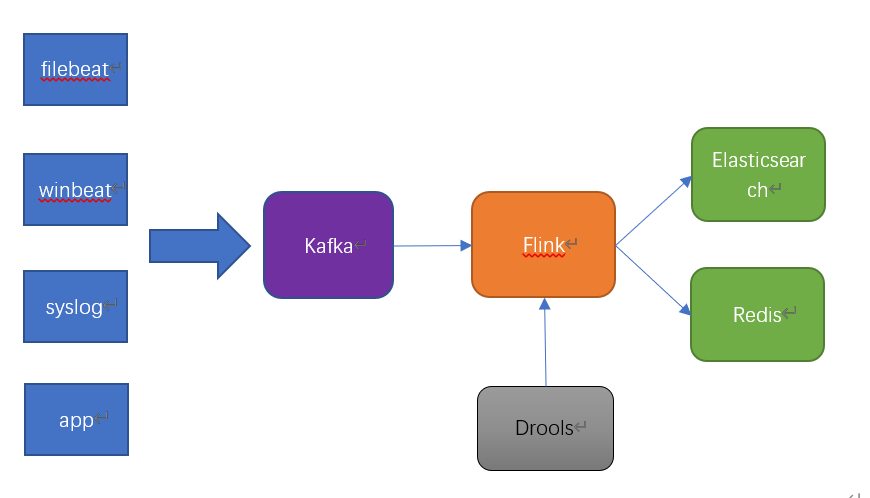
實驗:使用自定義協議
整體的流程:
客戶端:發送端連接服務器,將要發送的數據通過編碼器編碼,發送。
服務端:啟動、監聽端口、接收連接、將連接放在協程中處理、通過解碼器解碼數據。
//###########################
//###### Server端代碼 ######
//###########################
func main() {
// 1. 監聽端口 2.accept連接 3.開goroutine處理連接
listen, err := net.Listen("tcp", "0.0.0.0:9090")
if err != nil {
fmt.Printf("error : %v", err)
return
}
for{
conn, err := listen.Accept()
if err != nil {
fmt.Printf("Fail listen.Accept : %v", err)
continue
}
go ProcessConn(conn)
}
}
// 處理網絡請求
func ProcessConn(conn net.Conn) {
defer conn.Close()
for {
bt,err:=coder.Decode(conn)
if err != nil {
fmt.Printf("Fail to decode error [%v]", err)
return
}
s := string(bt)
fmt.Printf("Read from conn:[%v]\n",s)
}
}
//###########################
//###### Clinet端代碼 ######
//###########################
func main() {
conn, err := net.Dial("tcp", ":9090")
defer conn.Close()
if err != nil {
fmt.Printf("error : %v", err)
return
}
// 將數據編碼併發送出去
coder.Encode(conn,"hi server i am here");
}
//###########################
//###### 編解碼器代碼 ######
//###########################
/**
* 解碼:
*/
func Decode(reader io.Reader) (bytes []byte, err error) {
// 先把消息頭讀出來
headerBuf := make([]byte, len(msgHeader))
if _, err = io.ReadFull(reader, headerBuf); err != nil {
fmt.Printf("Fail to read header from conn error:[%v]", err)
return nil, err
}
// 檢驗消息頭
if string(headerBuf) != msgHeader {
err = errors.New("msgHeader error")
return nil, err
}
// 讀取實際內容的長度
lengthBuf := make([]byte, 4)
if _, err = io.ReadFull(reader, lengthBuf); err != nil {
return nil, err
}
contentLength := binary.BigEndian.Uint32(lengthBuf)
contentBuf := make([]byte, contentLength)
// 讀出消息體
if _, err := io.ReadFull(reader, contentBuf); err != nil {
return nil, err
}
return contentBuf, err
}
/**
* 編碼
* 定義消息的格式: msgHeader + contentLength + content
* conn 本身實現了 io.Writer 接口
*/
func Encode(conn io.Writer, content string) (err error) {
// 寫入消息頭
if err = binary.Write(conn, binary.BigEndian, []byte(msgHeader)); err != nil {
fmt.Printf("Fail to write msgHeader to conn,err:[%v]", err)
}
// 寫入消息體長度
contentLength := int32(len([]byte(content)))
if err = binary.Write(conn, binary.BigEndian, contentLength); err != nil {
fmt.Printf("Fail to write contentLength to conn,err:[%v]", err)
}
// 寫入消息
if err = binary.Write(conn, binary.BigEndian, []byte(content)); err != nil {
fmt.Printf("Fail to write content to conn,err:[%v]", err)
}
return err
客戶端的conn一直不被Close 有什麼表現?
四次揮手各個狀態的如下:
主從關閉方 被動關閉方
established established
Fin-wait1
closeWait
Fin-wait2
Tiem-wait lastAck
Closed Closed
如果客戶端的連接手動的關閉,它和服務端的狀態會一直保持established建立連接中的狀態。
MacBook-Pro% netstat -aln | grep 9090
tcp4 0 0 127.0.0.1.9090 127.0.0.1.62348 ESTABLISHED
tcp4 0 0 127.0.0.1.62348 127.0.0.1.9090 ESTABLISHED
tcp46 0 0 *.9090 *.* LISTEN
服務端的conn一直不被關閉 有什麼表現?
客戶端的進程結束后,會發送fin數據包給服務端,向服務端請求斷開連接。
服務端的conn不關閉的話,服務端就會停留在四次揮手的close_wait階段(我們不手動Close,服務端就任務還有數據/任務沒處理完,因此它不關閉)。
客戶端停留在 fin_wait2的階段(在這個階段等着服務端告訴自己可以真正斷開連接的消息)。
MacBook-Pro% netstat -aln | grep 9090
tcp4 0 0 127.0.0.1.9090 127.0.0.1.62888 CLOSE_WAIT
tcp4 0 0 127.0.0.1.62888 127.0.0.1.9090 FIN_WAIT_2
tcp46 0 0 *.9090 *.* LISTEN
什麼是binary.BigEndian?什麼是binary.LittleEndian?
對計算機來說一切都是二進制的數據,BigEndian和LittleEndian描述的就是二進制數據的字節順序。計算機內部,小端序被廣泛應用於現代性 CPU 內部存儲數據;大端序常用於網絡傳輸和文件存儲。
比如:
一個數的二進製表示為 0x12345678
BigEndian 表示為: 0x12 0x34 0x56 0x78
LittleEndian表示為: 0x78 0x56 0x34 0x12
UDP網絡編程
思路:
UDP服務器:1、監聽 2、循環讀取消息 3、回複數據。
UDP客戶端:1、連接服務器 2、發送消息 3、接收消息。
// ################################
// ######## UDPServer #########
// ################################
func main() {
// 1. 監聽端口 2.accept連接 3.開goroutine處理連接
listen, err := net.Listen("tcp", "0.0.0.0:9090")
if err != nil {
fmt.Printf("error : %v", err)
return
}
for{
conn, err := listen.Accept()
if err != nil {
fmt.Printf("Fail listen.Accept : %v", err)
continue
}
go ProcessConn(conn)
}
}
// 處理網絡請求
func ProcessConn(conn net.Conn) {
defer conn.Close()
for {
bt,err:= coder.Decode(conn)
if err != nil {
fmt.Printf("Fail to decode error [%v]", err)
return
}
s := string(bt)
fmt.Printf("Read from conn:[%v]\n",s)
}
}
// ################################
// ######## UDPClient #########
// ################################
func main() {
udpConn, err := net.DialUDP("udp", nil, &net.UDPAddr{
IP: net.IPv4(127, 0, 0, 1),
Port: 9091,
})
if err != nil {
fmt.Printf("error : %v", err)
return
}
_, err = udpConn.Write([]byte("i am udp client"))
if err != nil {
fmt.Printf("error : %v", err)
return
}
bytes:=make([]byte,1024)
num, addr, err := udpConn.ReadFromUDP(bytes)
if err != nil {
fmt.Printf("Fail to read from udp error: [%v]", err)
return
}
fmt.Printf("Recieve from udp address:[%v], bytes:[%v], content:[%v]",addr,num,string(bytes))
}
Http網絡編程
思路整理:
HttpServer:1、創建路由器。2、為路由器綁定路由規則。3、創建服務器、監聽端口。 4啟動讀服務。
HttpClient: 1、創建連接池。2、創建客戶端,綁定連接池。3、發送請求。4、讀取響應。
func main() {
mux := http.NewServeMux()
mux.HandleFunc("/login", doLogin)
server := &http.Server{
Addr: ":8081",
WriteTimeout: time.Second * 2,
Handler: mux,
}
log.Fatal(server.ListenAndServe())
}
func doLogin(writer http.ResponseWriter,req *http.Request){
_, err := writer.Write([]byte("do login"))
if err != nil {
fmt.Printf("error : %v", err)
return
}
}
HttpClient端
func main() {
transport := &http.Transport{
// 撥號的上下文
DialContext: (&net.Dialer{
Timeout: 30 * time.Second, // 撥號建立連接時的超時時間
KeepAlive: 30 * time.Second, // 長連接存活的時間
}).DialContext,
// 最大空閑連接數
MaxIdleConns: 100,
// 超過最大的空閑連接數的連接,經過 IdleConnTimeout時間後會失效
IdleConnTimeout: 10 * time.Second,
// https使用了SSL安全證書,TSL是SSL的升級版
// 當我們使用https時,這行配置生效
TLSHandshakeTimeout: 10 * time.Second,
ExpectContinueTimeout: 1 * time.Second, // 100-continue 狀態碼超時時間
}
// 創建客戶端
client := &http.Client{
Timeout: time.Second * 10, //請求超時時間
Transport: transport,
}
// 請求數據
res, err := client.Get("http://localhost:8081/login")
if err != nil {
fmt.Printf("error : %v", err)
return
}
defer res.Body.Close()
bytes, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Printf("error : %v", err)
return
}
fmt.Printf("Read from http server res:[%v]", string(bytes))
}
理解函數是一等公民
點擊查看在github中函數相關的筆記
在golang中函數是一等公民,我們可以把一個函數當作普通變量一樣使用。
比如我們有個函數HelloHandle,我們可以直接使用它。
func HelloHandle(name string, age int) {
fmt.Printf("name:[%v] age:[%v]", name, age)
}
func main() {
HelloHandle("tom",12)
}
閉包
如何理解閉包:閉包本質上是一個函數,而且這個函數會引用它外部的變量,如下例子中的f3中的匿名函數本身就是一個閉包。 通常我們使用閉包起到一個適配的作用。
例1:
// f2是一個普通函數,有兩個入參數
func f2() {
fmt.Printf("f2222")
}
// f1函數的入參是一個f2類型的函數
func f1(f2 func()) {
f2()
}
func main() {
// 由於golang中函數是一等公民,所以我們可以把f2同普通變量一般傳遞給f1
f1(f2)
}
例2: 在上例中更進一步。f2有了自己的參數, 這時就不能直接把f2傳遞給f1了。
總不能傻傻的這樣吧f1(f2(1,2)) ???
而閉包就能解決這個問題。
// f2是一個普通函數,有兩個入參數
func f2(x int, y int) {
fmt.Println("this is f2 start")
fmt.Printf("x: %d y: %d \n", x, y)
fmt.Println("this is f2 end")
}
// f1函數的入參是一個f2類型的函數
func f1(f2 func()) {
fmt.Println("this is f1 will call f2")
f2()
fmt.Println("this is f1 finished call f2")
}
// 接受一個兩個參數的函數, 返回一個包裝函數
func f3(f func(int,int) ,x,y int) func() {
fun := func() {
f(x,y)
}
return fun
}
func main() {
// 目標是實現如下的傳遞與調用
f1(f3(f2,6,6))
}
實現方法的回調:
下面的例子中實現這樣的功能:就好像是我設計了一個框架,定好了整個框架運轉的流程(或者說是提供了一個編程模版),框架具體做事的函數你根據自己的需求自己實現,我的框架只是負責幫你回調你具體的方法。
// 自定義類型,handler本質上是一個函數
type HandlerFunc func(string, int)
// 閉包
func (f HandlerFunc) Serve(name string, age int) {
f(name, age)
}
// 具體的處理函數
func HelloHandle(name string, age int) {
fmt.Printf("name:[%v] age:[%v]", name, age)
}
func main() {
// 把HelloHandle轉換進自定義的func中
handlerFunc := HandlerFunc(HelloHandle)
// 本質上會去回調HelloHandle方法
handlerFunc.Serve("tom", 12)
// 上面兩行效果 == 下面這行
// 只不過上面的代碼是我在幫你回調,下面的是你自己主動調用
HelloHandle("tom",12)
}
HttpServer源碼閱讀
註冊路由
直觀上看註冊路由這一步,就是它要做的就是將在路由器url pattern和開發者提供的func關聯起來。 很容易想到,它裏面很可能是通過map實現的。
func main() {
// 創建路由器
// 為路由器綁定路由規則
mux := http.NewServeMux()
mux.HandleFunc("/login", doLogin)
...
}
func doLogin(writer http.ResponseWriter,req *http.Request){
_, err := writer.Write([]byte("do login"))
if err != nil {
fmt.Printf("error : %v", err)
return
}
}
姑且將ServeMux當作是路由器。我們使用http包下的 NewServerMux 函數創建一個新的路由器對象,進而使用它的HandleFunc(pattern,func)函數完成路由的註冊。
跟進NewServerMux函數,可以看到,它通過new函數返回給我們一個ServeMux結構體。
func NewServeMux() *ServeMux {
return new(ServeMux)
}
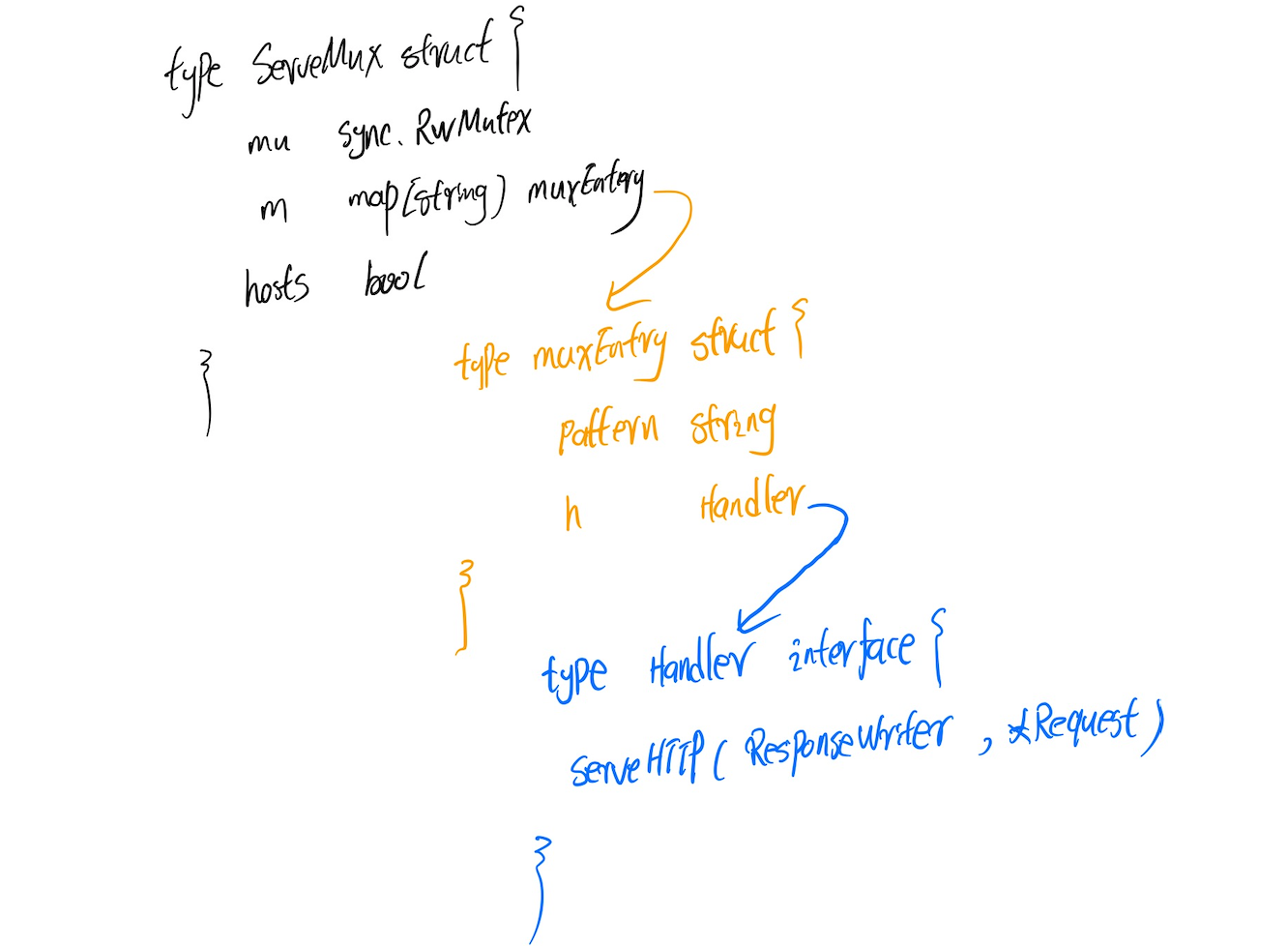
這個ServeMux結構體長下面這樣:在這個ServeMux結構體中我們就看到了這個維護pattern和func的map
type ServeMux struct {
mu sync.RWMutex
m map[string]muxEntry
hosts bool // whether any patterns contain hostnames
}
這個muxEntry長下面這樣:
type muxEntry struct {
h Handler
pattern string
}
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
看到這裏問題就來了,上面我們手動註冊進路由器中的僅僅是一個有規定參數的方法,到這裏怎麼成了一個Handle了?我們也沒有說去手動的實現Handler這個接口,也沒有重寫ServeHTTP函數啊, 在golang中實現一個接口不得像下面這樣搞嗎?**
type Handle interface {
Serve(string, int, string)
}
type HandleImpl struct {
}
func (h HandleImpl)Serve(string, int, string){
}
帶着這個疑問看下面的方法:
// 由於函數是一等公民,故我們將doLogin函數同普通變量一樣當做入參傳遞進去。
mux.HandleFunc("/login", doLogin)
func doLogin(writer http.ResponseWriter,req *http.Request){
...
}
跟進去看 HandleFunc 函數的實現:
首先:HandleFunc函數的第二個參數是接收的函數的類型和doLogin函數的類型是一致的,所以doLogin能正常的傳遞進HandleFunc中。
其次:我們的關注點應該是下面的HandlerFunc(handler)
// HandleFunc registers the handler function for the given pattern.
func (mux *ServeMux) HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {
if handler == nil {
panic("http: nil handler")
}
mux.Handle(pattern, HandlerFunc(handler))
}
跟進這個HandlerFunc(handler) 看到下圖,真相就大白於天下了。golang以一種優雅的方式悄無聲息的為我們完成了一次適配。這麼看來上面的HandlerFunc(handler)並不是函數的調用,而是doLogin轉換成自定義類型。這個自定義類型去實現了Handle接口(因為它重寫了ServeHTTP函數)以閉包的形式完美的將我們的doLogin適配成了Handle類型。
在往下看Handle方法:
第一:將pattern和handler註冊進map中
第二:為了保證整個過程的併發安全,使用鎖保護整個過程。
// Handle registers the handler for the given pattern.
// If a handler already exists for pattern, Handle panics.
func (mux *ServeMux) Handle(pattern string, handler Handler) {
mux.mu.Lock()
defer mux.mu.Unlock()
if pattern == "" {
panic("http: invalid pattern")
}
if handler == nil {
panic("http: nil handler")
}
if _, exist := mux.m[pattern]; exist {
panic("http: multiple registrations for " + pattern)
}
if mux.m == nil {
mux.m = make(map[string]muxEntry)
}
mux.m[pattern] = muxEntry{h: handler, pattern: pattern}
if pattern[0] != '/' {
mux.hosts = true
}
啟動服務
概覽圖:
和java對比着看,在java一組複雜的邏輯會被封裝成一個class。在golang中對應的就是一組複雜的邏輯會被封裝成一個結構體。
對應HttpServer肯定也是這樣,http服務器在golang的實現中有自己的結構體。它就是http包下的Server。
它有一系列描述性屬性。如監聽的地址、寫超時時間、路由器。
server := &http.Server{
Addr: ":8081",
WriteTimeout: time.Second * 2,
Handler: mux,
}
log.Fatal(server.ListenAndServe())
我們看它啟動服務的函數:server.ListenAndServe()
實現的邏輯是使用net包下的Listen函數,獲取給定地址上的tcp連接。
再將這個tcp連接封裝進 tcpKeepAliveListenner 結構體中。
在將這個tcpKeepAliveListenner丟進Server的Serve函數中處理
// ListenAndServe 會監聽開發者給定網絡地址上的tcp連接,當有請求到來時,會調用Serve函數去處理這個連接。
// 它接收到所有連接都使用 TCP keep-alives相關的配置
//
// 如果構造Server時沒有指定Addr,他就會使用默認值: “:http”
//
// 當Server ShutDown或者是Close,ListenAndServe總是會返回一個非nil的error。
// 返回的這個Error是 ErrServerClosed
func (srv *Server) ListenAndServe() error {
if srv.shuttingDown() {
return ErrServerClosed
}
addr := srv.Addr
if addr == "" {
addr = ":http"
}
// 底層藉助於tcp實現
ln, err := net.Listen("tcp", addr)
if err != nil {
return err
}
return srv.Serve(tcpKeepAliveListener{ln.(*net.TCPListener)})
}
// tcpKeepAliveListener會為TCP設置一個keep-alive 超時時長。
// 它通常被 ListenAndServe 和 ListenAndServeTLS使用。
// 它保證了已經dead的TCP最終都會消失。
type tcpKeepAliveListener struct {
*net.TCPListener
}
接着去看看Serve方法,上一個函數中獲取到了一個基於tcp的Listener,從這個Listener中可以不斷的獲取出新的連接,下面的方法中使用無限for循環完成這件事。conn獲取到后將連接封裝進httpConn,為了保證不阻塞下一個連接到到來,開啟新的goroutine處理這個http連接。
func (srv *Server) Serve(l net.Listener) error {
// 如果有一個包裹了 srv 和 listener 的鈎子函數,就執行它
if fn := testHookServerServe; fn != nil {
fn(srv, l) // call hook with unwrapped listener
}
// 將tcp的Listener封裝進onceCloseListener,保證連接不會被關閉多次。
l = &onceCloseListener{Listener: l}
defer l.Close()
// http2相關的配置
if err := srv.setupHTTP2_Serve(); err != nil {
return err
}
if !srv.trackListener(&l, true) {
return ErrServerClosed
}
defer srv.trackListener(&l, false)
// 如果沒有接收到請求睡眠多久
var tempDelay time.Duration // how long to sleep on accept failure
baseCtx := context.Background() // base is always background, per Issue 16220
ctx := context.WithValue(baseCtx, ServerContextKey, srv)
// 開啟無限循環,嘗試從Listenner中獲取連接。
for {
rw, e := l.Accept()
// accpet過程中發生錯屋
if e != nil {
select {
// 如果從server的doneChan中可以獲取內容,返回Server關閉了
case <-srv.getDoneChan():
return ErrServerClosed
default:
}
// 如果發生了 net.Error 並且是臨時的錯誤就睡5毫秒,再發生錯誤睡眠的時間*2,上線是1s
if ne, ok := e.(net.Error); ok && ne.Temporary() {
if tempDelay == 0 {
tempDelay = 5 * time.Millisecond
} else {
tempDelay *= 2
}
if max := 1 * time.Second; tempDelay > max {
tempDelay = max
}
srv.logf("http: Accept error: %v; retrying in %v", e, tempDelay)
time.Sleep(tempDelay)
continue
}
return e
}
// 如果沒有發生錯誤,清空睡眠的時間
tempDelay = 0
// 將接收到連接封裝進httpConn
c := srv.newConn(rw)
c.setState(c.rwc, StateNew) // before Serve can return
// 開啟一條新的協程處理這個連接
go c.serve(ctx)
}
}
處理請求
在c.serve(ctx)中就會去解析http相關的報文信息~,將http報文解析進Request結構體中。
部分代碼如下:
// 將 server 包裹為 serverHandler 的實例,執行它的 ServeHTTP 方法,處理請求,返迴響應。
// serverHandler 委託給 server 的 Handler 或者 DefaultServeMux(默認路由器)
// 來處理 "OPTIONS *" 請求。
serverHandler{c.server}.ServeHTTP(w, w.req)
// serverHandler delegates to either the server's Handler or
// DefaultServeMux and also handles "OPTIONS *" requests.
type serverHandler struct {
srv *Server
}
func (sh serverHandler) ServeHTTP(rw ResponseWriter, req *Request) {
// 如果沒有定義Handler就使用默認的
handler := sh.srv.Handler
if handler == nil {
handler = DefaultServeMux
}
if req.RequestURI == "*" && req.Method == "OPTIONS" {
handler = globalOptionsHandler{}
}
// 處理請求,返迴響應。
handler.ServeHTTP(rw, req)
}
可以看到,req中包含了我們前面說的pattern,叫做RequestUri,有了它下一步就知道該回調ServeMux中的哪一個函數。
HttpClient源碼閱讀
DemoCode
func main() {
// 創建連接池
// 創建客戶端,綁定連接池
// 發送請求
// 讀取響應
transport := &http.Transport{
DialContext: (&net.Dialer{
Timeout: 30 * time.Second, // 連接超時
KeepAlive: 30 * time.Second, // 長連接存活的時間
}).DialContext,
// 最大空閑連接數
MaxIdleConns: 100,
// 超過最大空閑連接數的連接會在IdleConnTimeout后被銷毀
IdleConnTimeout: 10 * time.Second,
TLSHandshakeTimeout: 10 * time.Second, // tls握手超時時間
ExpectContinueTimeout: 1 * time.Second, // 100-continue 狀態碼超時時間
}
// 創建客戶端
client := &http.Client{
Timeout: time.Second * 10, //請求超時時間
Transport: transport,
}
// 請求數據,獲得響應
res, err := client.Get("http://localhost:8081/login")
if err != nil {
fmt.Printf("error : %v", err)
return
}
defer res.Body.Close()
// 處理數據
bytes, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Printf("error : %v", err)
return
}
fmt.Printf("Read from http server res:[%v]", string(bytes))
}
整理思路
http.Client的代碼其實是很多的,全部很細的過一遍肯定也會難度,下面可能也是只能提及其中的一部分。
首先明白一件事,我們編寫的HttpClient是在干什麼?(雖然這個問題很傻,但是總得問一下)是在發送Http請求。
一般我們在開發的時候,更多的編寫的是HttpServer的代碼。是在處理Http請求, 而不是去發送Http請求,Http請求都是是前端通過ajax經由瀏覽器發送到後端的。
其次,Http請求實際上是建立在tcp連接之上的,所以如果我們去看http.Client肯定能找到net.Dial("tcp",adds)相關的代碼。
那也就是說,我們要看看,http.Client是如何在和服務端建立連接、發送數據、接收數據的。
重要的struct
http.Client中有機幾個比較重要的struct,如下
http.Client結構體中封裝了和http請求相關的屬性,諸如 cookie,timeout,redirect以及Transport。
type Client struct {
Transport RoundTripper
CheckRedirect func(req *Request, via []*Request) error
Jar CookieJar
Timeout time.Duration
}
Tranport實現了RoundTrpper接口:
type RoundTripper interface {
// 1、RoundTrip會去執行一個簡單的 Http Trancation,併為requestt返回一個響應
// 2、RoundTrip不會嘗試去解析response
// 3、注意:只要返回了Reponse,無論response的狀態碼是多少,RoundTrip返回的結果:err == nil
// 4、RoundTrip將請求發送出去后,如果他沒有獲取到response,他會返回一個非空的err。
// 5、同樣,RoundTrip不會嘗試去解析諸如重定向、認證、cookie這種更高級的協議。
// 6、除了消費和關閉請求體之外,RoundTrip不會修改request的其他字段
// 7、RoundTrip可以在一個單獨的gorountine中讀取request的部分字段。一直到ResponseBody關閉之前,調用者都不能取消,或者重用這個request
// 8、RoundTrip始終會保證關閉Body(包含在發生err時)。根據實現的不同,在RoundTrip關閉前,關閉Body這件事可能會在一個單獨的goroutine中去做。這就意味着,如果調用者想將請求體用於後續的請求,必須等待知道發生Close
// 9、請求的URL和Header字段必須是被初始化的。
RoundTrip(*Request) (*Response, error)
}
看上面RoundTrpper接口,它裏面只有一個方法RoundTrip,方法的作用就是執行一次Http請求,發送Request然後獲取Response。
RoundTrpper被設計成了一個支持併發的結構體。
Transport結構體如下:
type Transport struct {
idleMu sync.Mutex
// user has requested to close all idle conns
wantIdle bool
// Transport的作用就是用來建立一個連接,這個idleConn就是Transport維護的空閑連接池。
idleConn map[connectMethodKey][]*persistConn // most recently used at end
idleConnCh map[connectMethodKey]chan *persistConn
}
其中的connectMethodKey也是結構體:
type connectMethodKey struct {
// proxy 代理的URL,當他不為空時,就會一直使用這個key
// scheme 協議的類型, http https
// addr 代理的url,也就是下游的url
proxy, scheme, addr string
}
persistConn是一個具體的連接實例,包含連接的上下文。
type persistConn struct {
// alt可選地指定TLS NextProto RoundTripper。
// 這用於今天的HTTP / 2和以後的將來的協議。 如果非零,則其餘字段未使用。
alt RoundTripper
t *Transport
cacheKey connectMethodKey
conn net.Conn
tlsState *tls.ConnectionState
// 用於從conn中讀取內容
br *bufio.Reader // from conn
// 用於往conn中寫內容
bw *bufio.Writer // to conn
nwrite int64 // bytes written
// 他是個chan,roundTrip會將readLoop中的內容寫入到reqch中
reqch chan requestAndChan
// 他是個chan,roundTrip會將writeLoop中的內容寫到writech中
writech chan writeRequest
closech chan struct{} // closed when conn closed
另外補充一個結構體:Request,他用來描述一次http請求的實例,它定義於http包request.go, 裏面封裝了對Http請求相關的屬性
type Request struct {
Method string
URL *url.URL
Proto string // "HTTP/1.0"
ProtoMajor int // 1
ProtoMinor int // 0
Header Header
Body io.ReadCloser
GetBody func() (io.ReadCloser, error)
ContentLength int64
TransferEncoding []string
Close bool
Host string
Form url.Values
PostForm url.Values
MultipartForm *multipart.Form
Trailer Header
RemoteAddr string
RequestURI string
TLS *tls.ConnectionState
Cancel <-chan struct{}
Response *Response
ctx context.Context
}
這幾個結構體共同完成如下圖所示http.Client的工作流程
流程
我們想發送一次Http請求。首先我們需要構造一個Request,Request本質上是對Http協議的描述(因為大家使用的都是Http協議,所以將這個Request發送到HttpServer后,HttpServer能識別並解析它)。
// 從這行代碼開始往下看
res, err := client.Get("http://localhost:8081/login")
// 跟進Get
req, err := NewRequest("GET", url, nil)
if err != nil {
return nil, err
}
return c.Do(req)
// 跟進Do
func (c *Client) Do(req *Request) (*Response, error) {
return c.do(req)
}
// 跟進do,do函數中有下面的邏輯,可以看到執行完send后已經拿到返回值了。所以我們得繼續跟進send方法
if resp, didTimeout, err = c.send(req, deadline); err != nil
// 跟進send方法,可以看到send中還有一send方法,入參分別是:request,tranpost,deadline
// 到現在為止,我們沒有看到有任何和服務端建立連接的動作發生,但是構造的req和擁有連接池的tranport已經見面了~
resp, didTimeout, err = send(req, c.transport(), deadline)
// 繼續跟進這個send方法,看到了調用了rt的RoundTrip方法。
// 這個rt就是我們編寫HttpClient代碼時創建的,綁定在http.Client上的tranport實例。
// 這個RoundTrip方法的作用我們在上面已經說過了,最直接的作用就是:發送request 並獲取response。
resp, err = rt.RoundTrip(req)
但是RoundTrip他是個定義在RoundTripper接口中的抽象方法,我們看代碼肯定是要去看具體的實現嘛
這裏可以使用斷點調試法:在上面最後一行上打上斷點,會進入到他的具體實現中。從圖中可以看到具體的實現在roundtrip中。
RoundTrip中調用的函數是我們自定義的transport的roundTrip函數, 跟進去如下:
緊接着我們需要一個conn,這個conn我們通過Transport可以獲取到。conn的類型為persistConn。
// roundTrip函數中又一個無限for循環
for {
// 檢查請求的上下文是否關閉了
select {
case <-ctx.Done():
req.closeBody()
return nil, ctx.Err()
default:
}
// 對傳遞進來的req進行了有一層的封裝,封裝后的這個treq可以被roundTrip修改,所以每次重試都會新建
treq := &transportRequest{Request: req, trace: trace}
cm, err := t.connectMethodForRequest(treq)
if err != nil {
req.closeBody()
return nil, err
}
// 到這裏真的執行從tranport中獲取和對應主機的連接,這個連接可能是http、https、http代理、http代理的高速緩存, 但是無論如何我們都已經準備好了向這個連接發送treq
// 這裏獲取出來的連接就是我們在上文中提及的persistConn
pconn, err := t.getConn(treq, cm)
if err != nil {
t.setReqCanceler(req, nil)
req.closeBody()
return nil, err
}
var resp *Response
if pconn.alt != nil {
// HTTP/2 path.
t.decHostConnCount(cm.key()) // don't count cached http2 conns toward conns per host
t.setReqCanceler(req, nil) // not cancelable with CancelRequest
resp, err = pconn.alt.RoundTrip(req)
} else {
// 調用persistConn的roundTrip方法,發送treq並獲取響應。
resp, err = pconn.roundTrip(treq)
}
if err == nil {
return resp, nil
}
if !pconn.shouldRetryRequest(req, err) {
// Issue 16465: return underlying net.Conn.Read error from peek,
// as we've historically done.
if e, ok := err.(transportReadFromServerError); ok {
err = e.err
}
return nil, err
}
testHookRoundTripRetried()
// Rewind the body if we're able to. (HTTP/2 does this itself so we only
// need to do it for HTTP/1.1 connections.)
if req.GetBody != nil && pconn.alt == nil {
newReq := *req
var err error
newReq.Body, err = req.GetBody()
if err != nil {
return nil, err
}
req = &newReq
}
}
整理思路:然後看上面代碼中獲取conn和roundTrip的實現細節。
我們需要一個conn,這個conn可以通過Transport獲取到。conn的類型為persistConn。但是不管怎麼樣,都得先獲取出 persistConn,才能進一步完成發送請求再得到服務端到響應。
然後關於這個persistConn結構體其實上面已經提及過了。重新貼在下面
type persistConn struct {
// alt可選地指定TLS NextProto RoundTripper。
// 這用於今天的HTTP / 2和以後的將來的協議。 如果非零,則其餘字段未使用。
alt RoundTripper
conn net.Conn
t *Transport
br *bufio.Reader // 用於從conn中讀取內容
bw *bufio.Writer // 用於往conn中寫內容
// 他是個chan,roundTrip會將readLoop中的內容寫入到reqch中
reqch chan requestAndChan
// 他是個chan,roundTrip會將writeLoop中的內容寫到writech中
nwrite int64 // bytes written
cacheKey connectMethodKey
tlsState *tls.ConnectionState
writech chan writeRequest
closech chan struct{} // closed when conn closed
跟進 t.getConn(treq, cm)代碼如下:
// 先嘗試從空閑緩衝池中取得連接
// 所謂的空閑緩衝池就是Tranport結構體中的: idleConn map[connectMethodKey][]*persistConn
// 入參位置的cm如下:
/* type connectMethod struct {
// 代理的url,如果沒有代理的話,這個值為nil
proxyURL *url.URL
// 連接所使用的協議 http、https
targetScheme string
// 如果proxyURL指定了http代理或者是https代理,並且使用的協議是http而不是https。
// 那麼下面的targetAddr就會不包含在connect method key中。
// 因為socket可以復用不同的targetAddr值
targetAddr string
}*/
t.getIdleConn(cm);
// 空閑緩衝池有的空閑連接的話返回conn,否則進行如下的select
select {
// todo 這裏我還不確定是在干什麼,目前猜測是這樣的:每個服務器能打開的socket句柄是有限的
// 每次來獲取鏈接的時候,我們就計數+1。當整體的句柄在Host允許範圍內時我們不做任何干涉~
case <-t.incHostConnCount(cmKey):
// count below conn per host limit; proceed
// 重新嘗試從空閑連接池中獲取連接,因為可能有的連接使用完后被放回連接池了
case pc := <-t.getIdleConnCh(cm):
if trace != nil && trace.GotConn != nil {
trace.GotConn(httptrace.GotConnInfo{Conn: pc.conn, Reused: pc.isReused()})
}
return pc, nil
// 請求是否被取消了
case <-req.Cancel:
return nil, errRequestCanceledConn
// 請求的上下文是否Done掉了
case <-req.Context().Done():
return nil, req.Context().Err()
case err := <-cancelc:
if err == errRequestCanceled {
err = errRequestCanceledConn
}
return nil, err
}
// 開啟新的gorountine新建連接一個連接
go func() {
/**
* 新建連接,方法底層封裝了tcp client dial相關的邏輯
* conn, err := t.dial(ctx, "tcp", cm.addr())
* 以及根據不同的targetScheme構建不同的request的邏輯。
*/
// 獲取到persistConn
pc, err := t.dialConn(ctx, cm)
// 將persistConn寫到chan中
dialc <- dialRes{pc, err}
}()
// 再嘗試從空閑連接池中獲取
idleConnCh := t.getIdleConnCh(cm)
select {
// 如果上面的go協程撥號成功了,這裏就能取出值來
case v := <-dialc:
// Our dial finished.
if v.pc != nil {
if trace != nil && trace.GotConn != nil && v.pc.alt == nil {
trace.GotConn(httptrace.GotConnInfo{Conn: v.pc.conn})
}
return v.pc, nil
}
// Our dial failed. See why to return a nicer error
// value.
// 將Host的連接-1
t.decHostConnCount(cmKey)
select {
...
transport.dialConn
下面代碼中的cm長這樣
// dialConn是Transprot的方法
// 入參:context上下文, connectMethod
// 出參:persisnConn
func (t *Transport) dialConn(ctx context.Context, cm connectMethod) (*persistConn, error) {
// 構建將要返回的 persistConn
pconn := &persistConn{
t: t,
cacheKey: cm.key(),
reqch: make(chan requestAndChan, 1),
writech: make(chan writeRequest, 1),
closech: make(chan struct{}),
writeErrCh: make(chan error, 1),
writeLoopDone: make(chan struct{}),
}
trace := httptrace.ContextClientTrace(ctx)
wrapErr := func(err error) error {
if cm.proxyURL != nil {
// Return a typed error, per Issue 16997
return &net.OpError{Op: "proxyconnect", Net: "tcp", Err: err}
}
return err
}
// 判斷cm中使用的協議是否是https
if cm.scheme() == "https" && t.DialTLS != nil {
var err error
pconn.conn, err = t.DialTLS("tcp", cm.addr())
if err != nil {
return nil, wrapErr(err)
}
if pconn.conn == nil {
return nil, wrapErr(errors.New("net/http: Transport.DialTLS returned (nil, nil)"))
}
if tc, ok := pconn.conn.(*tls.Conn); ok {
// Handshake here, in case DialTLS didn't. TLSNextProto below
// depends on it for knowing the connection state.
if trace != nil && trace.TLSHandshakeStart != nil {
trace.TLSHandshakeStart()
}
if err := tc.Handshake(); err != nil {
go pconn.conn.Close()
if trace != nil && trace.TLSHandshakeDone != nil {
trace.TLSHandshakeDone(tls.ConnectionState{}, err)
}
return nil, err
}
cs := tc.ConnectionState()
if trace != nil && trace.TLSHandshakeDone != nil {
trace.TLSHandshakeDone(cs, nil)
}
pconn.tlsState = &cs
}
} else {
// 如果不是https協議就來到這裏,使用tcp向httpserver撥號,獲取一個tcp連接。
conn, err := t.dial(ctx, "tcp", cm.addr())
if err != nil {
return nil, wrapErr(err)
}
// 將獲取到tcp連接交給我們的persistConn維護
pconn.conn = conn
// 處理https相關邏輯
if cm.scheme() == "https" {
var firstTLSHost string
if firstTLSHost, _, err = net.SplitHostPort(cm.addr()); err != nil {
return nil, wrapErr(err)
}
if err = pconn.addTLS(firstTLSHost, trace); err != nil {
return nil, wrapErr(err)
}
}
}
// Proxy setup.
switch {
// 如果代理URL為空,不做任何處理
case cm.proxyURL == nil:
// Do nothing. Not using a proxy.
//
case cm.proxyURL.Scheme == "socks5":
conn := pconn.conn
d := socksNewDialer("tcp", conn.RemoteAddr().String())
if u := cm.proxyURL.User; u != nil {
auth := &socksUsernamePassword{
Username: u.Username(),
}
auth.Password, _ = u.Password()
d.AuthMethods = []socksAuthMethod{
socksAuthMethodNotRequired,
socksAuthMethodUsernamePassword,
}
d.Authenticate = auth.Authenticate
}
if _, err := d.DialWithConn(ctx, conn, "tcp", cm.targetAddr); err != nil {
conn.Close()
return nil, err
}
case cm.targetScheme == "http":
pconn.isProxy = true
if pa := cm.proxyAuth(); pa != "" {
pconn.mutateHeaderFunc = func(h Header) {
h.Set("Proxy-Authorization", pa)
}
}
case cm.targetScheme == "https":
conn := pconn.conn
hdr := t.ProxyConnectHeader
if hdr == nil {
hdr = make(Header)
}
connectReq := &Request{
Method: "CONNECT",
URL: &url.URL{Opaque: cm.targetAddr},
Host: cm.targetAddr,
Header: hdr,
}
if pa := cm.proxyAuth(); pa != "" {
connectReq.Header.Set("Proxy-Authorization", pa)
}
connectReq.Write(conn)
// Read response.
// Okay to use and discard buffered reader here, because
// TLS server will not speak until spoken to.
br := bufio.NewReader(conn)
resp, err := ReadResponse(br, connectReq)
if err != nil {
conn.Close()
return nil, err
}
if resp.StatusCode != 200 {
f := strings.SplitN(resp.Status, " ", 2)
conn.Close()
if len(f) < 2 {
return nil, errors.New("unknown status code")
}
return nil, errors.New(f[1])
}
}
if cm.proxyURL != nil && cm.targetScheme == "https" {
if err := pconn.addTLS(cm.tlsHost(), trace); err != nil {
return nil, err
}
}
if s := pconn.tlsState; s != nil && s.NegotiatedProtocolIsMutual && s.NegotiatedProtocol != "" {
if next, ok := t.TLSNextProto[s.NegotiatedProtocol]; ok {
return &persistConn{alt: next(cm.targetAddr, pconn.conn.(*tls.Conn))}, nil
}
}
if t.MaxConnsPerHost > 0 {
pconn.conn = &connCloseListener{Conn: pconn.conn, t: t, cmKey: pconn.cacheKey}
}
// 初始化persistConn的bufferReader和bufferWriter
pconn.br = bufio.NewReader(pconn) // 可以從上面給pconn維護的tcpConn中讀數據
pconn.bw = bufio.NewWriter(persistConnWriter{pconn})// 可以往上面pconn維護的tcpConn中寫數據
// 新開啟兩條和persistConn相關的go協程。
go pconn.readLoop()
go pconn.writeLoop()
return pconn, nil
}
上面的兩條goroutine 和 br bw共同完成如下圖的流程
發送請求
發送req的邏輯在http包的下的tranport包中的func (t *Transport) roundTrip(req *Request) (*Response, error) {}函數中。
如下:
// 發送treq
resp, err = pconn.roundTrip(treq)
// 跟進roundTrip
// 可以看到他將一個writeRequest結構體類型的實例寫入了writech中
// 而這個writech會被上圖中的writeLoop消費,藉助bufferWriter寫入tcp連接中,完成往服務端數據的發送。
pc.writech <- writeRequest{req, writeErrCh, continueCh}
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!