問題
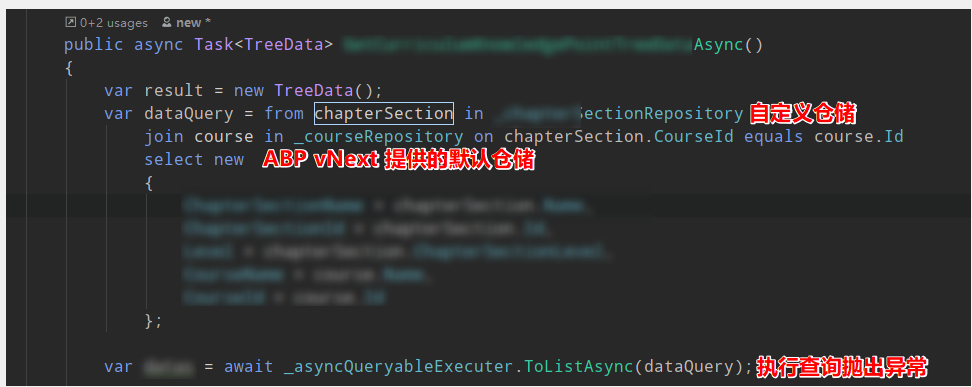
在使用自定義 Ef Core 倉儲和 ABP vNext 注入的默認倉儲時,通過兩個 Repository 進行 Join 操作,提示 Cannot use multiple DbContext instances within a single query execution. Ensure the query uses a single context instance. 。這個異常信息翻譯成中文的大概意思就是,你不能使用兩個 DbContext 裏面的 DbSet 進行 Join 查詢。
如果將自定義倉儲改為 IRepository<TEntity,TKey> 進行注入,是可以與 _courseRepostory 進行關聯查詢的。
我在 XXXEntityFrameworkCoreModule 的配置,以及自定義倉儲 EfCoreStudentRepository 代碼如下。
XXXEntityFrameworkCoreModule 代碼:
public class XXXEntityFrameworkCoreModule : AbpModule
{
public override void ConfigureServices(ServiceConfigurationContext context)
{
context.Services.AddAbpDbContext<XXXDbContext>(op =>
{
op.AddDefaultRepositories();
});
Configure<AbpDbContextOptions>(op => op.UsePostgreSql());
}
}
EfCoreStudentRepository 代碼:
public class EfCoreStudentRepository : EfCoreRepository<IXXXDbContext, Student, long>, IStudentRepository
{
public EfCoreStudentRepository(IDbContextProvider<IXXXDbContext> dbContextProvider) : base(dbContextProvider)
{
}
public Task<int> GetCountWithStudentlIdAsync(long studentId)
{
return DbSet.CountAsync(x=>x.studentId == studentId);
}
}
原因
原因在異常信息已經說得十分清楚了,這裏我們需要了解兩個問題。
- 什麼原因導致兩個倉儲內部的 DbContext 不一致?
- 為什麼 ABP vNext 自己實現的倉儲能夠進行關聯查詢呢?
首先我們得知道,倉儲內部的 DbContext是怎麼獲取的。我們的自定義倉儲都會繼承 EfCoreRepository ,而這個倉儲是實現了 IQuerable<T> 接口的,最終它會通過一個 IDbContextProvider<TDbContext> 獲得一個可用的 DbContext 。
public class EfCoreRepository<TDbContext, TEntity> : RepositoryBase<TEntity>, IEfCoreRepository<TEntity>
where TDbContext : IEfCoreDbContext
where TEntity : class, IEntity
{
public virtual DbSet<TEntity> DbSet => DbContext.Set<TEntity>();
DbContext IEfCoreRepository<TEntity>.DbContext => DbContext.As<DbContext>();
// 這裏可以看到,是通過 IDbContextProvider 來獲得 DbContext 的。
protected virtual TDbContext DbContext => _dbContextProvider.GetDbContext();
protected virtual AbpEntityOptions<TEntity> AbpEntityOptions => _entityOptionsLazy.Value;
private readonly IDbContextProvider<TDbContext> _dbContextProvider;
private readonly Lazy<AbpEntityOptions<TEntity>> _entityOptionsLazy;
// ... 其他代碼。
}
下面就是 IDbContextProvider<TDbContext> 內部的核心代碼:
public class UnitOfWorkDbContextProvider<TDbContext> : IDbContextProvider<TDbContext> where TDbContext : IEfCoreDbContext
{
private readonly IUnitOfWorkManager _unitOfWorkManager;
private readonly IConnectionStringResolver _connectionStringResolver;
// ... 其他代碼。
public TDbContext GetDbContext()
{
var unitOfWork = _unitOfWorkManager.Current;
if (unitOfWork == null)
{
throw new AbpException("A DbContext can only be created inside a unit of work!");
}
var connectionStringName = ConnectionStringNameAttribute.GetConnStringName<TDbContext>();
var connectionString = _connectionStringResolver.Resolve(connectionStringName);
// 會構造一個 Key,而這個 Key 剛好是泛型類型的 FullName。
var dbContextKey = $"{typeof(TDbContext).FullName}_{connectionString}";
// 內部是從一個字典當中,根據 dbContextKey 獲取 DbContext。如果不存在的話則調用工廠方法創建一個新的 DbContext。
var databaseApi = unitOfWork.GetOrAddDatabaseApi(
dbContextKey,
() => new EfCoreDatabaseApi<TDbContext>(
CreateDbContext(unitOfWork, connectionStringName, connectionString)
));
return ((EfCoreDatabaseApi<TDbContext>)databaseApi).DbContext;
}
// ... 其他代碼。
}
通過以上代碼我們就可以知道,ABP vNext 在倉儲的內部是通過 IDbContextProvider<TDbContext> 中的 TDbContext 泛型,來確定是否構建一個新的 DbContext 對象。
不論是 ABP vNext 針對 IRepository<TEntity,TKey> ,還是我們自己實現的自定義倉儲,它們最終的實現都是基於 EfCoreRepository<TDbContext,TEntity,TKey> 的。而我們 IDbContextProvider<TDbContext> 的泛型,也是這個倉儲基類提供的,後者的 TDbContext 就是前者的泛型參數。
所以當我們在模塊添加 DbContext 的過城中,只要調用了 AddDefaultRepositories() 方法,ABP vNext 就會遍歷你提供的 TDbContext 所定義的實體,然後為這些實體建立默認的倉儲。
在注入倉儲的時候,找到了獲得默認倉儲實現類型的方法,可以看到這裏它使用的是 DefaultRepositoryDbContextType 作為默認的 TDbContext 類型。
protected virtual Type GetDefaultRepositoryImplementationType(Type entityType)
{
var primaryKeyType = EntityHelper.FindPrimaryKeyType(entityType);
// 重點在於構造倉儲類型時,傳遞的 Options.DefaultRepositoryDbContextType 參數,這個參數就是後面 EfCoreRepository 的 TDbContext 泛型。
if (primaryKeyType == null)
{
return Options.SpecifiedDefaultRepositoryTypes
? Options.DefaultRepositoryImplementationTypeWithoutKey.MakeGenericType(entityType)
: GetRepositoryType(Options.DefaultRepositoryDbContextType, entityType);
}
return Options.SpecifiedDefaultRepositoryTypes
? Options.DefaultRepositoryImplementationType.MakeGenericType(entityType, primaryKeyType)
: GetRepositoryType(Options.DefaultRepositoryDbContextType, entityType, primaryKeyType);
}
最後我發現這個就是在模塊調用 AddAbpContext<TDbContext> 所提供的泛型參數。
public abstract class AbpCommonDbContextRegistrationOptions : IAbpCommonDbContextRegistrationOptionsBuilder
{
// ... 其他代碼
protected AbpCommonDbContextRegistrationOptions(Type originalDbContextType, IServiceCollection services)
{
OriginalDbContextType = originalDbContextType;
Services = services;
DefaultRepositoryDbContextType = originalDbContextType;
CustomRepositories = new Dictionary<Type, Type>();
ReplacedDbContextTypes = new List<Type>();
}
// ... 其他代碼
}
public class AbpDbContextRegistrationOptions : AbpCommonDbContextRegistrationOptions, IAbpDbContextRegistrationOptionsBuilder
{
public Dictionary<Type, object> AbpEntityOptions { get; }
public AbpDbContextRegistrationOptions(Type originalDbContextType, IServiceCollection services)
: base(originalDbContextType, services) // 之類調用的就是上面的構造方法。
{
AbpEntityOptions = new Dictionary<Type, object>();
}
}
public static class AbpEfCoreServiceCollectionExtensions
{
public static IServiceCollection AddAbpDbContext<TDbContext>(
this IServiceCollection services,
Action<IAbpDbContextRegistrationOptionsBuilder> optionsBuilder = null)
where TDbContext : AbpDbContext<TDbContext>
{
// ... 其他代碼。
var options = new AbpDbContextRegistrationOptions(typeof(TDbContext), services);
// ... 其他代碼。
return services;
}
}
所以,我們的默認倉儲的 dbContextKey 是 XXXDbContext,我們的自定義倉儲繼承 EfCoreRepository<IXXXDbContext,TEntity,TKey> ,所以它的 dbContextKey 就是 IXXXDbContext 。所以自定義倉儲獲取到的 DbContext 就與自定義倉儲的不一致了,從而提示上述異常。
解決
找到自定自定義倉儲的定義,修改它 EfCoreReposiotry<TDbContext,TEntity,TKey> 的 TDbContext 泛型參數,變更為 XXXDbContext 即可。
public class EfCoreStudentRepository : EfCoreRepository<XXXDbContext, Student, long>, IStudentRepository
{
public EfCoreStudentRepository(IDbContextProvider<XXXDbContext> dbContextProvider) : base(dbContextProvider)
{
}
public Task<int> GetCountWithStudentlIdAsync(long studentId)
{
return DbSet.CountAsync(x=>x.studentId == studentId);
}
}
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※南投搬家前需注意的眉眉角角,別等搬了再說!