@
目錄
- 前言
- 正文
- 基本概念
- 代理對象的創建
- 小結
- AOP鏈式調用
- AOP擴展知識
- 一、自定義全局攔截器Interceptor
- 二、循環依賴三級緩存存在的必要性
- 三、如何在Bean創建之前提前創建代理對象
- 總結
前言
AOP,也就是面向切面編程,它可以將公共的代碼抽離出來,動態的織入到目標類、目標方法中,大大提高我們編程的效率,也使程序變得更加優雅。如事務、操作日誌等都可以使用AOP實現。這種織入可以是在運行期動態生成代理對象實現,也可以在編譯期、類加載時期靜態織入到代碼中。而Spring正是通過第一種方法實現,且在代理類的生成上也有兩種方式:JDK Proxy和CGLIB,默認當類實現了接口時使用前者,否則使用後者;另外Spring AOP只能實現對方法的增強。
正文
基本概念
AOP的術語很多,雖然不清楚術語我們也能很熟練地使用AOP,但是要理解分析源碼,術語就需要深刻體會其含義。
- 增強(Advice):就是我們想要額外增加的功能
- 目標對象(Target):就是我們想要增強的目標類,如果沒有AOP,我們需要在每個目標對象中實現日誌、事務管理等非業務邏輯
- 連接點(JoinPoint):程序執行時的特定時機,如方法執行前、后以及拋出異常后等等。
- 切點(Pointcut):連接點的導航,我們如何找到目標對象呢?切點的作用就在於此,在Spring中就是匹配表達式。
- 引介(Introduction):引介是一種特殊的增強,它為類添加一些屬性和方法。這樣,即使一個業務類原本沒有實現某個接口,通過AOP的引介功能,我們可以動態地為該業務類添加接口的實現邏輯,讓業務類成為這個接口的實現類。
- 織入(Weaving):即如何將增強添加到目標對象的連接點上,有動態(運行期生成代理)、靜態(編譯期、類加載時期)兩種方式。
- 代理(Proxy):目標對象被織入增強后,就會產生一個代理對象,該對象可能是和原對象實現了同樣的一個接口(JDK),也可能是原對象的子類(CGLIB)。
- 切面(Aspect、Advisor):切面由切點和增強組成,包含了這兩者的定義。
代理對象的創建
在熟悉了AOP術語后,下面就來看看Spring是如何創建代理對象的,是否還記得上一篇提到的AOP的入口呢?在AbstractAutowireCapableBeanFactory類的applyBeanPostProcessorsAfterInitialization方法中循環調用了BeanPostProcessor的postProcessAfterInitialization方法,其中一個就是我們創建代理對象的入口。這裡是Bean實例化完成去創建代理對象,理所當然應該這樣,但實際上在Bean實例化之前調用了一個resolveBeforeInstantiation方法,這裏實際上我們也是有機會可以提前創建代理對象的,這裏放到最後來分析,先來看主入口,進入到AbstractAutoProxyCreator類中:
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {
if (bean != null) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
if (!this.earlyProxyReferences.contains(cacheKey)) {
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
//創建當前bean的代理,如果這個bean有advice的話,重點看
// Create proxy if we have advice.
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
//如果有切面,則生成該bean的代理
if (specificInterceptors != DO_NOT_PROXY) {
this.advisedBeans.put(cacheKey, Boolean.TRUE);
//把被代理對象bean實例封裝到SingletonTargetSource對象中
Object proxy = createProxy(
bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
this.proxyTypes.put(cacheKey, proxy.getClass());
return proxy;
}
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
先從緩存中拿,沒有則調用wrapIfNecessary方法創建。在這個方法裏面主要看兩個地方:getAdvicesAndAdvisorsForBean和createProxy。簡單一句話概括就是先掃描后創建,問題是掃描什麼呢?你可以先結合上面的概念思考下,換你會怎麼做。進入到子類AbstractAdvisorAutoProxyCreator的getAdvicesAndAdvisorsForBean方法中:
protected Object[] getAdvicesAndAdvisorsForBean(
Class<?> beanClass, String beanName, @Nullable TargetSource targetSource) {
//找到合格的切面
List<Advisor> advisors = findEligibleAdvisors(beanClass, beanName);
if (advisors.isEmpty()) {
return DO_NOT_PROXY;
}
return advisors.toArray();
}
protected List<Advisor> findEligibleAdvisors(Class<?> beanClass, String beanName) {
//找到候選的切面,其實就是一個尋找有@Aspectj註解的過程,把工程中所有有這個註解的類封裝成Advisor返回
List<Advisor> candidateAdvisors = findCandidateAdvisors();
//判斷候選的切面是否作用在當前beanClass上面,就是一個匹配過程。現在就是一個匹配
List<Advisor> eligibleAdvisors = findAdvisorsThatCanApply(candidateAdvisors, beanClass, beanName);
extendAdvisors(eligibleAdvisors);
if (!eligibleAdvisors.isEmpty()) {
//對有@Order@Priority進行排序
eligibleAdvisors = sortAdvisors(eligibleAdvisors);
}
return eligibleAdvisors;
}
在findEligibleAdvisors方法中可以看到有兩個步驟,第一先找到所有的切面,即掃描所有帶有@Aspect註解的類,並將其中的切點(表達式)和增強封裝為切面,掃描完成后,自然是要判斷哪些切面能夠連接到當前Bean實例上。下面一步步來分析,首先是掃描過程,進入到AnnotationAwareAspectJAutoProxyCreator類中:
protected List<Advisor> findCandidateAdvisors() {
// 先通過父類AbstractAdvisorAutoProxyCreator掃描,這裏不重要
List<Advisor> advisors = super.findCandidateAdvisors();
// 主要看這裏
if (this.aspectJAdvisorsBuilder != null) {
advisors.addAll(this.aspectJAdvisorsBuilder.buildAspectJAdvisors());
}
return advisors;
}
這裏委託給了BeanFactoryAspectJAdvisorsBuilderAdapter類,並調用其父類的buildAspectJAdvisors方法創建切面對象:
public List<Advisor> buildAspectJAdvisors() {
List<String> aspectNames = this.aspectBeanNames;
if (aspectNames == null) {
synchronized (this) {
aspectNames = this.aspectBeanNames;
if (aspectNames == null) {
List<Advisor> advisors = new ArrayList<>();
aspectNames = new ArrayList<>();
//獲取spring容器中的所有bean的名稱BeanName
String[] beanNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
this.beanFactory, Object.class, true, false);
for (String beanName : beanNames) {
if (!isEligibleBean(beanName)) {
continue;
}
Class<?> beanType = this.beanFactory.getType(beanName);
if (beanType == null) {
continue;
}
//判斷類上是否有@Aspect註解
if (this.advisorFactory.isAspect(beanType)) {
aspectNames.add(beanName);
AspectMetadata amd = new AspectMetadata(beanType, beanName);
if (amd.getAjType().getPerClause().getKind() == PerClauseKind.SINGLETON) {
// 當@Aspect的value屬性為""時才會進入到這裏
// 創建獲取有@Aspect註解類的實例工廠,負責獲取有@Aspect註解類的實例
MetadataAwareAspectInstanceFactory factory =
new BeanFactoryAspectInstanceFactory(this.beanFactory, beanName);
//創建切面advisor對象
List<Advisor> classAdvisors = this.advisorFactory.getAdvisors(factory);
if (this.beanFactory.isSingleton(beanName)) {
this.advisorsCache.put(beanName, classAdvisors);
}
else {
this.aspectFactoryCache.put(beanName, factory);
}
advisors.addAll(classAdvisors);
}
else {
MetadataAwareAspectInstanceFactory factory =
new PrototypeAspectInstanceFactory(this.beanFactory, beanName);
this.aspectFactoryCache.put(beanName, factory);
advisors.addAll(this.advisorFactory.getAdvisors(factory));
}
}
}
this.aspectBeanNames = aspectNames;
return advisors;
}
}
}
return advisors;
}
這個方法裏面首先從IOC中拿到所有Bean的名稱,並循環判斷該類上是否帶有@Aspect註解,如果有則將BeanName和Bean的Class類型封裝到BeanFactoryAspectInstanceFactory中,並調用ReflectiveAspectJAdvisorFactory.getAdvisors創建切面對象:
public List<Advisor> getAdvisors(MetadataAwareAspectInstanceFactory aspectInstanceFactory) {
//從工廠中獲取有@Aspect註解的類Class
Class<?> aspectClass = aspectInstanceFactory.getAspectMetadata().getAspectClass();
//從工廠中獲取有@Aspect註解的類的名稱
String aspectName = aspectInstanceFactory.getAspectMetadata().getAspectName();
validate(aspectClass);
// 創建工廠的裝飾類,獲取實例只會獲取一次
MetadataAwareAspectInstanceFactory lazySingletonAspectInstanceFactory =
new LazySingletonAspectInstanceFactoryDecorator(aspectInstanceFactory);
List<Advisor> advisors = new ArrayList<>();
//這裏循環沒有@Pointcut註解的方法
for (Method method : getAdvisorMethods(aspectClass)) {
//非常重要重點看看
Advisor advisor = getAdvisor(method, lazySingletonAspectInstanceFactory, advisors.size(), aspectName);
if (advisor != null) {
advisors.add(advisor);
}
}
if (!advisors.isEmpty() && lazySingletonAspectInstanceFactory.getAspectMetadata().isLazilyInstantiated()) {
Advisor instantiationAdvisor = new SyntheticInstantiationAdvisor(lazySingletonAspectInstanceFactory);
advisors.add(0, instantiationAdvisor);
}
//判斷屬性上是否有引介註解,這裏可以不看
for (Field field : aspectClass.getDeclaredFields()) {
//判斷屬性上是否有DeclareParents註解,如果有返回切面
Advisor advisor = getDeclareParentsAdvisor(field);
if (advisor != null) {
advisors.add(advisor);
}
}
return advisors;
}
private List<Method> getAdvisorMethods(Class<?> aspectClass) {
final List<Method> methods = new ArrayList<>();
ReflectionUtils.doWithMethods(aspectClass, method -> {
// Exclude pointcuts
if (AnnotationUtils.getAnnotation(method, Pointcut.class) == null) {
methods.add(method);
}
});
methods.sort(METHOD_COMPARATOR);
return methods;
}
根據Aspect的Class拿到所有不帶@Pointcut註解的方法對象(為什麼是不帶@Pointcut註解的方法?仔細想想不難理解),另外要注意這裏對method進行了排序,看看這個METHOD_COMPARATOR比較器:
private static final Comparator<Method> METHOD_COMPARATOR;
static {
Comparator<Method> adviceKindComparator = new ConvertingComparator<>(
new InstanceComparator<>(
Around.class, Before.class, After.class, AfterReturning.class, AfterThrowing.class),
(Converter<Method, Annotation>) method -> {
AspectJAnnotation<?> annotation =
AbstractAspectJAdvisorFactory.findAspectJAnnotationOnMethod(method);
return (annotation != null ? annotation.getAnnotation() : null);
});
Comparator<Method> methodNameComparator = new ConvertingComparator<>(Method::getName);
METHOD_COMPARATOR = adviceKindComparator.thenComparing(methodNameComparator);
}
關注InstanceComparator構造函數參數,記住它們的順序,這就是AOP鏈式調用中同一個@Aspect類中Advice的執行順序。接着往下看,在getAdvisors方法中循環獲取到的methods,分別調用getAdvisor方法,也就是根據方法逐個去創建切面:
public Advisor getAdvisor(Method candidateAdviceMethod, MetadataAwareAspectInstanceFactory aspectInstanceFactory,
int declarationOrderInAspect, String aspectName) {
validate(aspectInstanceFactory.getAspectMetadata().getAspectClass());
//獲取pointCut對象,最重要的是從註解中獲取表達式
AspectJExpressionPointcut expressionPointcut = getPointcut(
candidateAdviceMethod, aspectInstanceFactory.getAspectMetadata().getAspectClass());
if (expressionPointcut == null) {
return null;
}
//創建Advisor切面類,這才是真正的切面類,一個切面類裏面肯定要有1、pointCut 2、advice
//這裏pointCut是expressionPointcut, advice 增強方法是 candidateAdviceMethod
return new InstantiationModelAwarePointcutAdvisorImpl(expressionPointcut, candidateAdviceMethod,
this, aspectInstanceFactory, declarationOrderInAspect, aspectName);
}
private static final Class<?>[] ASPECTJ_ANNOTATION_CLASSES = new Class<?>[] {
Pointcut.class, Around.class, Before.class, After.class, AfterReturning.class, AfterThrowing.class};
private AspectJExpressionPointcut getPointcut(Method candidateAdviceMethod, Class<?> candidateAspectClass) {
//從候選的增強方法裏面 candidateAdviceMethod 找有有註解
//Pointcut.class, Around.class, Before.class, After.class, AfterReturning.class, AfterThrowing.class
//並把註解信息封裝成AspectJAnnotation對象
AspectJAnnotation<?> aspectJAnnotation =
AbstractAspectJAdvisorFactory.findAspectJAnnotationOnMethod(candidateAdviceMethod);
if (aspectJAnnotation == null) {
return null;
}
//創建一個PointCut類,並且把前面從註解裏面解析的表達式設置進去
AspectJExpressionPointcut ajexp =
new AspectJExpressionPointcut(candidateAspectClass, new String[0], new Class<?>[0]);
ajexp.setExpression(aspectJAnnotation.getPointcutExpression());
if (this.beanFactory != null) {
ajexp.setBeanFactory(this.beanFactory);
}
return ajexp;
}
之前就說過切面的定義,是切點和增強的組合,所以這裏首先通過getPointcut獲取到註解對象,然後new了一個Pointcut對象,並將表達式設置進去。然後在getAdvisor方法中最後new了一個InstantiationModelAwarePointcutAdvisorImpl對象:
public InstantiationModelAwarePointcutAdvisorImpl(AspectJExpressionPointcut declaredPointcut,
Method aspectJAdviceMethod, AspectJAdvisorFactory aspectJAdvisorFactory,
MetadataAwareAspectInstanceFactory aspectInstanceFactory, int declarationOrder, String aspectName) {
this.declaredPointcut = declaredPointcut;
this.declaringClass = aspectJAdviceMethod.getDeclaringClass();
this.methodName = aspectJAdviceMethod.getName();
this.parameterTypes = aspectJAdviceMethod.getParameterTypes();
this.aspectJAdviceMethod = aspectJAdviceMethod;
this.aspectJAdvisorFactory = aspectJAdvisorFactory;
this.aspectInstanceFactory = aspectInstanceFactory;
this.declarationOrder = declarationOrder;
this.aspectName = aspectName;
if (aspectInstanceFactory.getAspectMetadata().isLazilyInstantiated()) {
// Static part of the pointcut is a lazy type.
Pointcut preInstantiationPointcut = Pointcuts.union(
aspectInstanceFactory.getAspectMetadata().getPerClausePointcut(), this.declaredPointcut);
// Make it dynamic: must mutate from pre-instantiation to post-instantiation state.
// If it's not a dynamic pointcut, it may be optimized out
// by the Spring AOP infrastructure after the first evaluation.
this.pointcut = new PerTargetInstantiationModelPointcut(
this.declaredPointcut, preInstantiationPointcut, aspectInstanceFactory);
this.lazy = true;
}
else {
// A singleton aspect.
this.pointcut = this.declaredPointcut;
this.lazy = false;
//這個方法重點看看,創建advice對象
this.instantiatedAdvice = instantiateAdvice(this.declaredPointcut);
}
}
這個就是我們的切面類,在其構造方法的最後通過instantiateAdvice創建了Advice對象。注意這裏傳進來的declarationOrder參數,它就是循環method時的序號,其作用就是賦值給這裏的declarationOrder屬性以及Advice的declarationOrder屬性,在後面排序時就會通過這個序號來比較,因此Advice的執行順序是固定的,至於為什麼要固定,後面分析完AOP鏈式調用過程自然就明白了。
public Advice getAdvice(Method candidateAdviceMethod, AspectJExpressionPointcut expressionPointcut,
MetadataAwareAspectInstanceFactory aspectInstanceFactory, int declarationOrder, String aspectName) {
//獲取有@Aspect註解的類
Class<?> candidateAspectClass = aspectInstanceFactory.getAspectMetadata().getAspectClass();
validate(candidateAspectClass);
//找到candidateAdviceMethod方法上面的註解,並且包裝成AspectJAnnotation對象,這個對象中就有註解類型
AspectJAnnotation<?> aspectJAnnotation =
AbstractAspectJAdvisorFactory.findAspectJAnnotationOnMethod(candidateAdviceMethod);
if (aspectJAnnotation == null) {
return null;
}
AbstractAspectJAdvice springAdvice;
//根據不同的註解類型創建不同的advice類實例
switch (aspectJAnnotation.getAnnotationType()) {
case AtPointcut:
if (logger.isDebugEnabled()) {
logger.debug("Processing pointcut '" + candidateAdviceMethod.getName() + "'");
}
return null;
case AtAround:
//實現了MethodInterceptor接口
springAdvice = new AspectJAroundAdvice(
candidateAdviceMethod, expressionPointcut, aspectInstanceFactory);
break;
case AtBefore:
//實現了MethodBeforeAdvice接口,沒有實現MethodInterceptor接口
springAdvice = new AspectJMethodBeforeAdvice(
candidateAdviceMethod, expressionPointcut, aspectInstanceFactory);
break;
case AtAfter:
//實現了MethodInterceptor接口
springAdvice = new AspectJAfterAdvice(
candidateAdviceMethod, expressionPointcut, aspectInstanceFactory);
break;
case AtAfterReturning:
//實現了AfterReturningAdvice接口,沒有實現MethodInterceptor接口
springAdvice = new AspectJAfterReturningAdvice(
candidateAdviceMethod, expressionPointcut, aspectInstanceFactory);
AfterReturning afterReturningAnnotation = (AfterReturning) aspectJAnnotation.getAnnotation();
if (StringUtils.hasText(afterReturningAnnotation.returning())) {
springAdvice.setReturningName(afterReturningAnnotation.returning());
}
break;
case AtAfterThrowing:
//實現了MethodInterceptor接口
springAdvice = new AspectJAfterThrowingAdvice(
candidateAdviceMethod, expressionPointcut, aspectInstanceFactory);
AfterThrowing afterThrowingAnnotation = (AfterThrowing) aspectJAnnotation.getAnnotation();
if (StringUtils.hasText(afterThrowingAnnotation.throwing())) {
springAdvice.setThrowingName(afterThrowingAnnotation.throwing());
}
break;
default:
throw new UnsupportedOperationException(
"Unsupported advice type on method: " + candidateAdviceMethod);
}
// Now to configure the advice...
springAdvice.setAspectName(aspectName);
springAdvice.setDeclarationOrder(declarationOrder);
String[] argNames = this.parameterNameDiscoverer.getParameterNames(candidateAdviceMethod);
if (argNames != null) {
springAdvice.setArgumentNamesFromStringArray(argNames);
}
//計算argNames和類型的對應關係
springAdvice.calculateArgumentBindings();
return springAdvice;
}
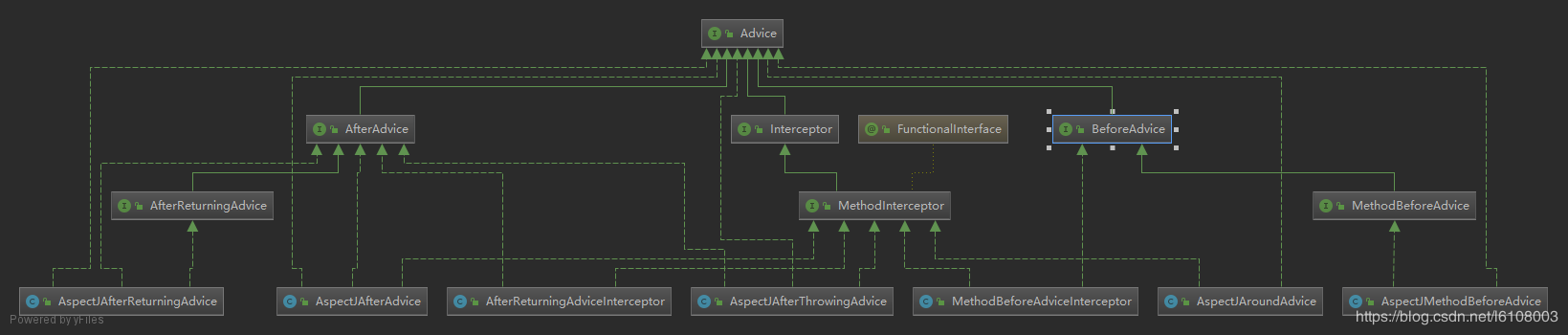
這裏邏輯很清晰,就是拿到方法上的註解類型,根據類型創建不同的增強Advice對象:AspectJAroundAdvice、AspectJMethodBeforeAdvice、AspectJAfterAdvice、AspectJAfterReturningAdvice、AspectJAfterThrowingAdvice。完成之後通過calculateArgumentBindings方法進行參數綁定,感興趣的可自行研究。這裏主要看看幾個Advice的繼承體系:
可以看到有兩個Advice是沒有實現MethodInterceptor接口的:AspectJMethodBeforeAdvice和AspectJAfterReturningAdvice。而MethodInterceptor有一個invoke方法,這個方法就是鏈式調用的核心方法,但那兩個沒有實現該方法的Advice怎麼處理呢?稍後會分析。
到這裏切面對象就創建完成了,接下來就是判斷當前創建的Bean實例是否和這些切面匹配以及對切面排序。匹配過程比較複雜,對理解主流程也沒什麼幫助,所以這裏就不展開分析,感興趣的自行分析(AbstractAdvisorAutoProxyCreator.findAdvisorsThatCanApply())。下面看看排序的過程,回到AbstractAdvisorAutoProxyCreator.findEligibleAdvisors方法:
protected List<Advisor> findEligibleAdvisors(Class<?> beanClass, String beanName) {
//找到候選的切面,其實就是一個尋找有@Aspectj註解的過程,把工程中所有有這個註解的類封裝成Advisor返回
List<Advisor> candidateAdvisors = findCandidateAdvisors();
//判斷候選的切面是否作用在當前beanClass上面,就是一個匹配過程。。現在就是一個匹配
List<Advisor> eligibleAdvisors = findAdvisorsThatCanApply(candidateAdvisors, beanClass, beanName);
extendAdvisors(eligibleAdvisors);
if (!eligibleAdvisors.isEmpty()) {
//對有@Order@Priority進行排序
eligibleAdvisors = sortAdvisors(eligibleAdvisors);
}
return eligibleAdvisors;
}
sortAdvisors方法就是排序,但這個方法有兩個實現:當前類AbstractAdvisorAutoProxyCreator和子類AspectJAwareAdvisorAutoProxyCreator,應該走哪個呢?
通過類圖我們可以肯定是進入的AspectJAwareAdvisorAutoProxyCreator類,因為AnnotationAwareAspectJAutoProxyCreator的父類是它。
protected List<Advisor> sortAdvisors(List<Advisor> advisors) {
List<PartiallyComparableAdvisorHolder> partiallyComparableAdvisors = new ArrayList<>(advisors.size());
for (Advisor element : advisors) {
partiallyComparableAdvisors.add(
new PartiallyComparableAdvisorHolder(element, DEFAULT_PRECEDENCE_COMPARATOR));
}
List<PartiallyComparableAdvisorHolder> sorted = PartialOrder.sort(partiallyComparableAdvisors);
if (sorted != null) {
List<Advisor> result = new ArrayList<>(advisors.size());
for (PartiallyComparableAdvisorHolder pcAdvisor : sorted) {
result.add(pcAdvisor.getAdvisor());
}
return result;
}
else {
return super.sortAdvisors(advisors);
}
}
這裏排序主要是委託給PartialOrder進行的,而在此之前將所有的切面都封裝成了PartiallyComparableAdvisorHolder對象,注意傳入的DEFAULT_PRECEDENCE_COMPARATOR參數,這個就是比較器對象:
private static final Comparator<Advisor> DEFAULT_PRECEDENCE_COMPARATOR = new AspectJPrecedenceComparator();
所以我們直接看這個比較器的compare方法:
public int compare(Advisor o1, Advisor o2) {
int advisorPrecedence = this.advisorComparator.compare(o1, o2);
if (advisorPrecedence == SAME_PRECEDENCE && declaredInSameAspect(o1, o2)) {
advisorPrecedence = comparePrecedenceWithinAspect(o1, o2);
}
return advisorPrecedence;
}
private final Comparator<? super Advisor> advisorComparator;
public AspectJPrecedenceComparator() {
this.advisorComparator = AnnotationAwareOrderComparator.INSTANCE;
}
第一步先通過AnnotationAwareOrderComparator去比較,點進去看可以發現是對實現了PriorityOrdered和Ordered接口以及標記了Priority和Order註解的非同一個@Aspect類中的切面進行排序。這個和之前分析BeanFacotryPostProcessor類是一樣的原理。而對同一個@Aspect類中的切面排序主要是comparePrecedenceWithinAspect方法:
private int comparePrecedenceWithinAspect(Advisor advisor1, Advisor advisor2) {
boolean oneOrOtherIsAfterAdvice =
(AspectJAopUtils.isAfterAdvice(advisor1) || AspectJAopUtils.isAfterAdvice(advisor2));
int adviceDeclarationOrderDelta = getAspectDeclarationOrder(advisor1) - getAspectDeclarationOrder(advisor2);
if (oneOrOtherIsAfterAdvice) {
// the advice declared last has higher precedence
if (adviceDeclarationOrderDelta < 0) {
// advice1 was declared before advice2
// so advice1 has lower precedence
return LOWER_PRECEDENCE;
}
else if (adviceDeclarationOrderDelta == 0) {
return SAME_PRECEDENCE;
}
else {
return HIGHER_PRECEDENCE;
}
}
else {
// the advice declared first has higher precedence
if (adviceDeclarationOrderDelta < 0) {
// advice1 was declared before advice2
// so advice1 has higher precedence
return HIGHER_PRECEDENCE;
}
else if (adviceDeclarationOrderDelta == 0) {
return SAME_PRECEDENCE;
}
else {
return LOWER_PRECEDENCE;
}
}
}
private int getAspectDeclarationOrder(Advisor anAdvisor) {
AspectJPrecedenceInformation precedenceInfo =
AspectJAopUtils.getAspectJPrecedenceInformationFor(anAdvisor);
if (precedenceInfo != null) {
return precedenceInfo.getDeclarationOrder();
}
else {
return 0;
}
}
這裏就是通過precedenceInfo.getDeclarationOrder拿到在創建InstantiationModelAwarePointcutAdvisorImpl對象時設置的declarationOrder屬性,這就驗證了之前的說法(實際上這裏排序過程非常複雜,不是簡單的按照這個屬性進行排序)。
當上面的一切都進行完成后,就該創建代理對象了,回到AbstractAutoProxyCreator.wrapIfNecessary,看關鍵部分代碼:
//如果有切面,則生成該bean的代理
if (specificInterceptors != DO_NOT_PROXY) {
this.advisedBeans.put(cacheKey, Boolean.TRUE);
//把被代理對象bean實例封裝到SingletonTargetSource對象中
Object proxy = createProxy(
bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
this.proxyTypes.put(cacheKey, proxy.getClass());
return proxy;
}
注意這裏將被代理對象封裝成了一個SingletonTargetSource對象,它是TargetSource的實現類。
protected Object createProxy(Class<?> beanClass, @Nullable String beanName,
@Nullable Object[] specificInterceptors, TargetSource targetSource) {
if (this.beanFactory instanceof ConfigurableListableBeanFactory) {
AutoProxyUtils.exposeTargetClass((ConfigurableListableBeanFactory) this.beanFactory, beanName, beanClass);
}
//創建代理工廠
ProxyFactory proxyFactory = new ProxyFactory();
proxyFactory.copyFrom(this);
if (!proxyFactory.isProxyTargetClass()) {
if (shouldProxyTargetClass(beanClass, beanName)) {
//proxyTargetClass 是否對類進行代理,而不是對接口進行代理,設置為true時,使用CGLib代理。
proxyFactory.setProxyTargetClass(true);
}
else {
evaluateProxyInterfaces(beanClass, proxyFactory);
}
}
//把advice類型的增強包裝成advisor切面
Advisor[] advisors = buildAdvisors(beanName, specificInterceptors);
proxyFactory.addAdvisors(advisors);
proxyFactory.setTargetSource(targetSource);
customizeProxyFactory(proxyFactory);
////用來控制代理工廠被配置后,是否還允許修改代理的配置,默認為false
proxyFactory.setFrozen(this.freezeProxy);
if (advisorsPreFiltered()) {
proxyFactory.setPreFiltered(true);
}
//獲取代理實例
return proxyFactory.getProxy(getProxyClassLoader());
}
這裏通過ProxyFactory對象去創建代理實例,這是工廠模式的體現,但在創建代理對象之前還有幾個準備動作:需要判斷是JDK代理還是CGLIB代理以及通過buildAdvisors方法將擴展的Advice封裝成Advisor切面。準備完成則通過getProxy創建代理對象:
public Object getProxy(@Nullable ClassLoader classLoader) {
//根據目標對象是否有接口來判斷採用什麼代理方式,cglib代理還是jdk動態代理
return createAopProxy().getProxy(classLoader);
}
protected final synchronized AopProxy createAopProxy() {
if (!this.active) {
activate();
}
return getAopProxyFactory().createAopProxy(this);
}
public AopProxy createAopProxy(AdvisedSupport config) throws AopConfigException {
if (config.isOptimize() || config.isProxyTargetClass() || hasNoUserSuppliedProxyInterfaces(config)) {
Class<?> targetClass = config.getTargetClass();
if (targetClass == null) {
throw new AopConfigException("TargetSource cannot determine target class: " +
"Either an interface or a target is required for proxy creation.");
}
if (targetClass.isInterface() || Proxy.isProxyClass(targetClass)) {
return new JdkDynamicAopProxy(config);
}
return new ObjenesisCglibAopProxy(config);
}
else {
return new JdkDynamicAopProxy(config);
}
}
首先通過配置拿到對應的代理類:ObjenesisCglibAopProxy和JdkDynamicAopProxy,然後再通過getProxy創建Bean的代理,這裏以JdkDynamicAopProxy為例:
public Object getProxy(@Nullable ClassLoader classLoader) {
//advised是代理工廠對象
Class<?>[] proxiedInterfaces = AopProxyUtils.completeProxiedInterfaces(this.advised, true);
findDefinedEqualsAndHashCodeMethods(proxiedInterfaces);
return Proxy.newProxyInstance(classLoader, proxiedInterfaces, this);
}
這裏的代碼你應該不陌生了,就是JDK的原生API,newProxyInstance方法傳入的InvocationHandler對象是this,因此,最終AOP代理的調用就是從該類中的invoke方法開始。至此,代理對象的創建就完成了,下面來看下整個過程的時序圖:
小結
代理對象的創建過程整體來說並不複雜,首先找到所有帶有@Aspect註解的類,並獲取其中沒有@Pointcut註解的方法,循環創建切面,而創建切面需要切點和增強兩個元素,其中切點可簡單理解為我們寫的表達式,增強則是根據@Before、@Around、@After等註解創建的對應的Advice類。切面創建好后則需要循環判斷哪些切面能對當前的Bean實例的方法進行增強並排序,最後通過ProxyFactory創建代理對象。
AOP鏈式調用
熟悉JDK動態代理的都知道通過代理對象調用方法時,會進入到InvocationHandler對象的invoke方法,所以我們直接從JdkDynamicAopProxy的這個方法開始:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
MethodInvocation invocation;
Object oldProxy = null;
boolean setProxyContext = false;
//從代理工廠中拿到TargetSource對象,該對象包裝了被代理實例bean
TargetSource targetSource = this.advised.targetSource;
Object target = null;
try {
//被代理對象的equals方法和hashCode方法是不能被代理的,不會走切面
.......
Object retVal;
// 可以從當前線程中拿到代理對象
if (this.advised.exposeProxy) {
// Make invocation available if necessary.
oldProxy = AopContext.setCurrentProxy(proxy);
setProxyContext = true;
}
//這個target就是被代理實例
target = targetSource.getTarget();
Class<?> targetClass = (target != null ? target.getClass() : null);
//從代理工廠中拿過濾器鏈 Object是一個MethodInterceptor類型的對象,其實就是一個advice對象
List<Object> chain = this.advised.getInterceptorsAndDynamicInterceptionAdvice(method, targetClass);
//如果該方法沒有執行鏈,則說明這個方法不需要被攔截,則直接反射調用
if (chain.isEmpty()) {
Object[] argsToUse = AopProxyUtils.adaptArgumentsIfNecessary(method, args);
retVal = AopUtils.invokeJoinpointUsingReflection(target, method, argsToUse);
}
else {
invocation = new ReflectiveMethodInvocation(proxy, target, method, args, targetClass, chain);
retVal = invocation.proceed();
}
// Massage return value if necessary.
Class<?> returnType = method.getReturnType();
if (retVal != null && retVal == target &&
returnType != Object.class && returnType.isInstance(proxy) &&
!RawTargetAccess.class.isAssignableFrom(method.getDeclaringClass())) {
retVal = proxy;
}
return retVal;
}
finally {
if (target != null && !targetSource.isStatic()) {
// Must have come from TargetSource.
targetSource.releaseTarget(target);
}
if (setProxyContext) {
// Restore old proxy.
AopContext.setCurrentProxy(oldProxy);
}
}
}
這段代碼比較長,我刪掉了不關鍵的地方。首先來看this.advised.exposeProxy這個屬性,這在@EnableAspectJAutoProxy註解中可以配置,當為true時,會將該代理對象設置到當前線程的ThreadLocal對象中,這樣就可以通過AopContext.currentProxy拿到代理對象。這個有什麼用呢?我相信有經驗的Java開發都遇到過這樣一個BUG,在Service實現類中調用本類中的另一個方法時,事務不會生效,這是因為直接通過this調用就不會調用到代理對象的方法,而是原對象的,所以事務切面就沒有生效。因此這種情況下就可以從當前線程的ThreadLocal對象拿到代理對象,不過實際上直接使用@Autowired注入自己本身也可以拿到代理對象。
接下來就是通過getInterceptorsAndDynamicInterceptionAdvice拿到執行鏈,看看具體做了哪些事情:
public List<Object> getInterceptorsAndDynamicInterceptionAdvice(
Advised config, Method method, @Nullable Class<?> targetClass) {
AdvisorAdapterRegistry registry = GlobalAdvisorAdapterRegistry.getInstance();
//從代理工廠中獲得該被代理類的所有切面advisor,config就是代理工廠對象
Advisor[] advisors = config.getAdvisors();
List<Object> interceptorList = new ArrayList<>(advisors.length);
Class<?> actualClass = (targetClass != null ? targetClass : method.getDeclaringClass());
Boolean hasIntroductions = null;
for (Advisor advisor : advisors) {
//大部分走這裏
if (advisor instanceof PointcutAdvisor) {
// Add it conditionally.
PointcutAdvisor pointcutAdvisor = (PointcutAdvisor) advisor;
//如果切面的pointCut和被代理對象是匹配的,說明是切面要攔截的對象
if (config.isPreFiltered() || pointcutAdvisor.getPointcut().getClassFilter().matches(actualClass)) {
MethodMatcher mm = pointcutAdvisor.getPointcut().getMethodMatcher();
boolean match;
if (mm instanceof IntroductionAwareMethodMatcher) {
if (hasIntroductions == null) {
hasIntroductions = hasMatchingIntroductions(advisors, actualClass);
}
match = ((IntroductionAwareMethodMatcher) mm).matches(method, actualClass, hasIntroductions);
}
else {
//接下來判斷方法是否是切面pointcut需要攔截的方法
match = mm.matches(method, actualClass);
}
//如果類和方法都匹配
if (match) {
//獲取到切面advisor中的advice,並且包裝成MethodInterceptor類型的對象
MethodInterceptor[] interceptors = registry.getInterceptors(advisor);
if (mm.isRuntime()) {
for (MethodInterceptor interceptor : interceptors) {
interceptorList.add(new InterceptorAndDynamicMethodMatcher(interceptor, mm));
}
}
else {
interceptorList.addAll(Arrays.asList(interceptors));
}
}
}
}
//如果是引介切面
else if (advisor instanceof IntroductionAdvisor) {
IntroductionAdvisor ia = (IntroductionAdvisor) advisor;
if (config.isPreFiltered() || ia.getClassFilter().matches(actualClass)) {
Interceptor[] interceptors = registry.getInterceptors(advisor);
interceptorList.addAll(Arrays.asList(interceptors));
}
}
else {
Interceptor[] interceptors = registry.getInterceptors(advisor);
interceptorList.addAll(Arrays.asList(interceptors));
}
}
return interceptorList;
}
這也是個長方法,看關鍵的部分,因為之前我們創建的基本上都是InstantiationModelAwarePointcutAdvisorImpl對象,該類是PointcutAdvisor的實現類,所以會進入第一個if判斷里,這裏首先進行匹配,看切點和當前對象以及該對象的哪些方法匹配,如果能匹配上,則調用getInterceptors獲取執行鏈:
private final List<AdvisorAdapter> adapters = new ArrayList<>(3);
public DefaultAdvisorAdapterRegistry() {
registerAdvisorAdapter(new MethodBeforeAdviceAdapter());
registerAdvisorAdapter(new AfterReturningAdviceAdapter());
registerAdvisorAdapter(new ThrowsAdviceAdapter());
}
public MethodInterceptor[] getInterceptors(Advisor advisor) throws UnknownAdviceTypeException {
List<MethodInterceptor> interceptors = new ArrayList<>(3);
Advice advice = advisor.getAdvice();
//如果是MethodInterceptor類型的,如:AspectJAroundAdvice
//AspectJAfterAdvice
//AspectJAfterThrowingAdvice
if (advice instanceof MethodInterceptor) {
interceptors.add((MethodInterceptor) advice);
}
//處理 AspectJMethodBeforeAdvice AspectJAfterReturningAdvice
for (AdvisorAdapter adapter : this.adapters) {
if (adapter.supportsAdvice(advice)) {
interceptors.add(adapter.getInterceptor(advisor));
}
}
if (interceptors.isEmpty()) {
throw new UnknownAdviceTypeException(advisor.getAdvice());
}
return interceptors.toArray(new MethodInterceptor[0]);
}
這裏我們可以看到如果是MethodInterceptor的實現類,則直接添加到鏈中,如果不是,則需要通過適配器去包裝后添加,剛好這裡有MethodBeforeAdviceAdapter和AfterReturningAdviceAdapter兩個適配器對應上文兩個沒有實現MethodInterceptor接口的類。最後將Interceptors返回。
if (chain.isEmpty()) {
Object[] argsToUse = AopProxyUtils.adaptArgumentsIfNecessary(method, args);
retVal = AopUtils.invokeJoinpointUsingReflection(target, method, argsToUse);
}
else {
// We need to create a method invocation...
invocation = new ReflectiveMethodInvocation(proxy, target, method, args, targetClass, chain);
// Proceed to the joinpoint through the interceptor chain.
retVal = invocation.proceed();
}
返回到invoke方法后,如果執行鏈為空,說明該方法不需要被增強,所以直接反射調用原對象的方法(注意傳入的是TargetSource封裝的被代理對象);反之,則通過ReflectiveMethodInvocation類進行鏈式調用,關鍵方法就是proceed:
private int currentInterceptorIndex = -1;
public Object proceed() throws Throwable {
//如果執行鏈中的advice全部執行完,則直接調用joinPoint方法,就是被代理方法
if (this.currentInterceptorIndex == this.interceptorsAndDynamicMethodMatchers.size() - 1) {
return invokeJoinpoint();
}
Object interceptorOrInterceptionAdvice =
this.interceptorsAndDynamicMethodMatchers.get(++this.currentInterceptorIndex);
if (interceptorOrInterceptionAdvice instanceof InterceptorAndDynamicMethodMatcher) {
InterceptorAndDynamicMethodMatcher dm =
(InterceptorAndDynamicMethodMatcher) interceptorOrInterceptionAdvice;
Class<?> targetClass = (this.targetClass != null ? this.targetClass : this.method.getDeclaringClass());
if (dm.methodMatcher.matches(this.method, targetClass, this.arguments)) {
return dm.interceptor.invoke(this);
}
else {
return proceed();
}
}
else {
//調用MethodInterceptor中的invoke方法
return ((MethodInterceptor) interceptorOrInterceptionAdvice).invoke(this);
}
}
這個方法的核心就在兩個地方:invokeJoinpoint和interceptorOrInterceptionAdvice.invoke(this)。當增強方法調用完后就會通過前者調用到被代理的方法,否則則是依次調用Interceptor的invoke方法。下面就分別看看每個Interceptor是怎麼實現的。
- AspectJAroundAdvice
public Object invoke(MethodInvocation mi) throws Throwable {
if (!(mi instanceof ProxyMethodInvocation)) {
throw new IllegalStateException("MethodInvocation is not a Spring ProxyMethodInvocation: " + mi);
}
ProxyMethodInvocation pmi = (ProxyMethodInvocation) mi;
ProceedingJoinPoint pjp = lazyGetProceedingJoinPoint(pmi);
JoinPointMatch jpm = getJoinPointMatch(pmi);
return invokeAdviceMethod(pjp, jpm, null, null);
}
- MethodBeforeAdviceInterceptor -> AspectJMethodBeforeAdvice
public Object invoke(MethodInvocation mi) throws Throwable {
this.advice.before(mi.getMethod(), mi.getArguments(), mi.getThis());
return mi.proceed();
}
public void before(Method method, Object[] args, @Nullable Object target) throws Throwable {
invokeAdviceMethod(getJoinPointMatch(), null, null);
}
- AspectJAfterAdvice
public Object invoke(MethodInvocation mi) throws Throwable {
try {
return mi.proceed();
}
finally {
invokeAdviceMethod(getJoinPointMatch(), null, null);
}
}
- AfterReturningAdviceInterceptor -> AspectJAfterReturningAdvice
public Object invoke(MethodInvocation mi) throws Throwable {
Object retVal = mi.proceed();
this.advice.afterReturning(retVal, mi.getMethod(), mi.getArguments(), mi.getThis());
return retVal;
}
public void afterReturning(@Nullable Object returnValue, Method method, Object[] args, @Nullable Object target) throws Throwable {
if (shouldInvokeOnReturnValueOf(method, returnValue)) {
invokeAdviceMethod(getJoinPointMatch(), returnValue, null);
}
}
- AspectJAfterThrowingAdvice
public Object invoke(MethodInvocation mi) throws Throwable {
try {
return mi.proceed();
}
catch (Throwable ex) {
if (shouldInvokeOnThrowing(ex)) {
invokeAdviceMethod(getJoinPointMatch(), null, ex);
}
throw ex;
}
}
這裏的調用順序是怎樣的呢?其核心就是通過proceed方法控制流程,每執行完一個Advice就會回到proceed方法中調用下一個Advice。可以思考一下,怎麼才能讓調用結果滿足如下圖的執行順序。
以上就是AOP的鏈式調用過程,但是這隻是只有一個切面類的情況,如果有多個@Aspect類呢,這個調用過程又是怎樣的?其核心思想和“棧”一樣,就是“先進后出,後進先出”。
AOP擴展知識
一、自定義全局攔截器Interceptor
在上文創建代理對象的時候有這樣一個方法:
protected Advisor[] buildAdvisors(@Nullable String beanName, @Nullable Object[] specificInterceptors) {
//自定義MethodInterceptor.拿到setInterceptorNames方法注入的Interceptor對象
Advisor[] commonInterceptors = resolveInterceptorNames();
List<Object> allInterceptors = new ArrayList<>();
if (specificInterceptors != null) {
allInterceptors.addAll(Arrays.asList(specificInterceptors));
if (commonInterceptors.length > 0) {
if (this.applyCommonInterceptorsFirst) {
allInterceptors.addAll(0, Arrays.asList(commonInterceptors));
}
else {
allInterceptors.addAll(Arrays.asList(commonInterceptors));
}
}
}
Advisor[] advisors = new Advisor[allInterceptors.size()];
for (int i = 0; i < allInterceptors.size(); i++) {
//對自定義的advice要進行包裝,把advice包裝成advisor對象,切面對象
advisors[i] = this.advisorAdapterRegistry.wrap(allInterceptors.get(i));
}
return advisors;
}
這個方法的作用就在於我們可以擴展我們自己的Interceptor,首先通過resolveInterceptorNames方法獲取到通過setInterceptorNames方法設置的Interceptor,然後調用DefaultAdvisorAdapterRegistry.wrap方法將其包裝為DefaultPointcutAdvisor對象並返回:
public Advisor wrap(Object adviceObject) throws UnknownAdviceTypeException {
if (adviceObject instanceof Advisor) {
return (Advisor) adviceObject;
}
if (!(adviceObject instanceof Advice)) {
throw new UnknownAdviceTypeException(adviceObject);
}
Advice advice = (Advice) adviceObject;
if (advice instanceof MethodInterceptor) {
return new DefaultPointcutAdvisor(advice);
}
for (AdvisorAdapter adapter : this.adapters) {
if (adapter.supportsAdvice(advice)) {
return new DefaultPointcutAdvisor(advice);
}
}
throw new UnknownAdviceTypeException(advice);
}
public DefaultPointcutAdvisor(Advice advice) {
this(Pointcut.TRUE, advice);
}
需要注意DefaultPointcutAdvisor構造器裏面傳入了一個Pointcut.TRUE,表示這種擴展的Interceptor是全局的攔截器。下面來看看如何使用:
public class MyMethodInterceptor implements MethodInterceptor {
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
System.out.println("自定義攔截器");
return invocation.proceed();
}
}
首先寫一個類實現MethodInterceptor 接口,在invoke方法中實現我們的攔截邏輯,然後通過下面的方式測試,只要UserService 有AOP攔截就會發現自定義的MyMethodInterceptor也生效了。
public void costomInterceptorTest() {
AnnotationAwareAspectJAutoProxyCreator bean = applicationContext.getBean(AnnotationAwareAspectJAutoProxyCreator.class);
bean.setInterceptorNames("myMethodInterceptor ");
UserService userService = applicationContext.getBean(UserService.class);
userService.queryUser("dark");
}
但是如果換個順序,像下面這樣:
public void costomInterceptorTest() {
UserService userService = applicationContext.getBean(UserService.class);
AnnotationAwareAspectJAutoProxyCreator bean = applicationContext.getBean(AnnotationAwareAspectJAutoProxyCreator.class);
bean.setInterceptorNames("myMethodInterceptor ");
userService.queryUser("dark");
}
這時自定義的全局攔截器就沒有作用了,這是為什麼呢?因為當執行getBean的時候,如果有切面匹配就會通過ProxyFactory去創建代理對象,注意Interceptor是存到這個Factory對象中的,而這個對象和代理對象是一一對應的,因此調用getBean時,還沒有myMethodInterceptor這個對象,自定義攔截器就沒有效果了,也就是說要想自定義攔截器生效,就必須在代理對象生成之前註冊進去。
二、循環依賴三級緩存存在的必要性
在上一篇文章我分析了Spring是如何通過三級緩存來解決循環依賴的問題的,但你是否考慮過第三級緩存為什麼要存在?我直接將bean存到二級不就行了么,為什麼還要存一個ObjectFactory對象到第三級緩存中?這個在學習了AOP之後就很清楚了,因為我們在@Autowired對象時,想要注入的不一定是Bean本身,而是想要注入一個修改過後的對象,如代理對象。在AbstractAutowireCapableBeanFactory.getEarlyBeanReference方法中循環調用了SmartInstantiationAwareBeanPostProcessor.getEarlyBeanReference方法,AbstractAutoProxyCreator對象就實現了該方法:
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
if (!this.earlyProxyReferences.contains(cacheKey)) {
this.earlyProxyReferences.add(cacheKey);
}
// 創建代理對象
return wrapIfNecessary(bean, beanName, cacheKey);
}
因此,當我們想要對循壞依賴的Bean做出修改時,就可以像AOP這樣做。
三、如何在Bean創建之前提前創建代理對象
Spring的代理對象基本上都是在Bean實例化完成之後創建的,但在文章開始我就說過,Spring也提供了一個機會在創建Bean對象之前就創建代理對象,在AbstractAutowireCapableBeanFactory.resolveBeforeInstantiation方法中:
protected Object resolveBeforeInstantiation(String beanName, RootBeanDefinition mbd) {
Object bean = null;
if (!Boolean.FALSE.equals(mbd.beforeInstantiationResolved)) {
// Make sure bean class is actually resolved at this point.
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
Class<?> targetType = determineTargetType(beanName, mbd);
if (targetType != null) {
bean = applyBeanPostProcessorsBeforeInstantiation(targetType, beanName);
if (bean != null) {
bean = applyBeanPostProcessorsAfterInitialization(bean, beanName);
}
}
}
mbd.beforeInstantiationResolved = (bean != null);
}
return bean;
}
protected Object applyBeanPostProcessorsBeforeInstantiation(Class<?> beanClass, String beanName) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
Object result = ibp.postProcessBeforeInstantiation(beanClass, beanName);
if (result != null) {
return result;
}
}
}
return null;
}
主要是InstantiationAwareBeanPostProcessor.postProcessBeforeInstantiation方法中,這裏又會進入到AbstractAutoProxyCreator類中:
public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) {
TargetSource targetSource = getCustomTargetSource(beanClass, beanName);
if (targetSource != null) {
if (StringUtils.hasLength(beanName)) {
this.targetSourcedBeans.add(beanName);
}
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(beanClass, beanName, targetSource);
Object proxy = createProxy(beanClass, beanName, specificInterceptors, targetSource);
this.proxyTypes.put(cacheKey, proxy.getClass());
return proxy;
}
return null;
}
protected TargetSource getCustomTargetSource(Class<?> beanClass, String beanName) {
// We can't create fancy target sources for directly registered singletons.
if (this.customTargetSourceCreators != null &&
this.beanFactory != null && this.beanFactory.containsBean(beanName)) {
for (TargetSourceCreator tsc : this.customTargetSourceCreators) {
TargetSource ts = tsc.getTargetSource(beanClass, beanName);
if (ts != null) {
return ts;
}
}
}
// No custom TargetSource found.
return null;
}
看到這裏大致應該明白了,先是獲取到一個自定義的TargetSource對象,然後創建代理對象,所以我們首先需要自己實現一個TargetSource類,這裏直接繼承一個抽象類,getTarget方法則返回原始對象:
public class MyTargetSource extends AbstractBeanFactoryBasedTargetSource {
@Override
public Object getTarget() throws Exception {
return getBeanFactory().getBean(getTargetBeanName());
}
}
但這還不夠,上面首先判斷了customTargetSourceCreators!=null,而這個屬性是個數組,可以通過下面這個方法設置進來:
public void setCustomTargetSourceCreators(TargetSourceCreator... targetSourceCreators) {
this.customTargetSourceCreators = targetSourceCreators;
}
所以我們還要實現一個TargetSourceCreator類,同樣繼承一個抽象類實現,並只對userServiceImpl對象進行攔截:
public class MyTargetSourceCreator extends AbstractBeanFactoryBasedTargetSourceCreator {
@Override
protected AbstractBeanFactoryBasedTargetSource createBeanFactoryBasedTargetSource(Class<?> beanClass, String beanName) {
if (getBeanFactory() instanceof ConfigurableListableBeanFactory) {
if(beanName.equalsIgnoreCase("userServiceImpl")) {
return new MyTargetSource();
}
}
return null;
}
}
createBeanFactoryBasedTargetSource方法是在AbstractBeanFactoryBasedTargetSourceCreator.getTargetSource中調用的,而getTargetSource就是在上面getCustomTargetSource中調用的。以上工作做完后,還需要將其設置到AnnotationAwareAspectJAutoProxyCreator對象中,因此需要我們注入這個對象:
@Configuration
public class TargetSourceCreatorBean {
@Autowired
private BeanFactory beanFactory;
@Bean
public AnnotationAwareAspectJAutoProxyCreator annotationAwareAspectJAutoProxyCreator() {
AnnotationAwareAspectJAutoProxyCreator creator = new AnnotationAwareAspectJAutoProxyCreator();
MyTargetSourceCreator myTargetSourceCreator = new MyTargetSourceCreator();
myTargetSourceCreator.setBeanFactory(beanFactory);
creator.setCustomTargetSourceCreators(myTargetSourceCreator);
return creator;
}
}
這樣,當我們通過getBean獲取userServiceImpl的對象時,就會優先生成代理對象,然後在調用執行鏈的過程中再通過TargetSource.getTarget獲取到被代理對象。但是,為什麼我們在getTarget方法中調用getBean就能拿到被代理對象呢?
繼續探究,通過斷點我發現從getTarget進入時,在resolveBeforeInstantiation方法中返回的bean就是null了,而getBeanPostProcessors方法返回的Processors中也沒有了AnnotationAwareAspectJAutoProxyCreator對象,也就是沒有進入到AbstractAutoProxyCreator.postProcessBeforeInstantiation方法中,所以不會再次獲取到代理對象,那AnnotationAwareAspectJAutoProxyCreator對象是在什麼時候移除的呢?
帶着問題,我開始反推,發現在AbstractBeanFactoryBasedTargetSourceCreator類中有這樣一個方法buildInternalBeanFactory:
protected DefaultListableBeanFactory buildInternalBeanFactory(ConfigurableBeanFactory containingFactory) {
DefaultListableBeanFactory internalBeanFactory = new DefaultListableBeanFactory(containingFactory);
// Required so that all BeanPostProcessors, Scopes, etc become available.
internalBeanFactory.copyConfigurationFrom(containingFactory);
// Filter out BeanPostProcessors that are part of the AOP infrastructure,
// since those are only meant to apply to beans defined in the original factory.
internalBeanFactory.getBeanPostProcessors().removeIf(beanPostProcessor ->
beanPostProcessor instanceof AopInfrastructureBean);
return internalBeanFactory;
}
在這裏移除掉了所有AopInfrastructureBean的子類,而AnnotationAwareAspectJAutoProxyCreator就是其子類,那這個方法是在哪裡調用的呢?繼續反推:
protected DefaultListableBeanFactory getInternalBeanFactoryForBean(String beanName) {
synchronized (this.internalBeanFactories) {
DefaultListableBeanFactory internalBeanFactory = this.internalBeanFactories.get(beanName);
if (internalBeanFactory == null) {
internalBeanFactory = buildInternalBeanFactory(this.beanFactory);
this.internalBeanFactories.put(beanName, internalBeanFactory);
}
return internalBeanFactory;
}
}
public final TargetSource getTargetSource(Class<?> beanClass, String beanName) {
AbstractBeanFactoryBasedTargetSource targetSource =
createBeanFactoryBasedTargetSource(beanClass, beanName);
// 創建完targetSource后就移除掉AopInfrastructureBean類型的BeanPostProcessor對象,如AnnotationAwareAspectJAutoProxyCreator
DefaultListableBeanFactory internalBeanFactory = getInternalBeanFactoryForBean(beanName);
......
return targetSource;
}
至此,關於TargetSource接口擴展的原理就搞明白了。
總結
本篇篇幅比較長,主要搞明白Spring代理對象是如何創建的以及AOP鏈式調用過程,而後面的擴展則是對AOP以及Bean創建過程中一些疑惑的補充,可根據實際情況學習掌握。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!